所有語言











分享
律師觀點: “餵養”的AI畫師,是創作還是偷竊?
巴比特_肖飒654天前
原創:肖颯lawyer
核心提示
1、根據《生成式人工智能服務管理辦法(徵求意見稿)》第二十條,AIGC的服務提供者“構成犯罪的,依法追究刑事責任”。
2、AI繪畫服務提供者“投喂”AI繪畫不侵犯複製權與信息網絡傳播權,不會構成侵犯著作權罪。
3、若著作權人採取技術措施,AI繪畫服務提供者通過“爬蟲”避開技術措施獲取圖片並“投喂”,則可能構成侵犯著作權罪。
AIGC的服務提供者雖然僅是根據用戶的要求進行相應的輸出,用戶具有相當強的自由決定如何使用,但作為平台也需要承擔一定的社會責任。國家互聯網信息辦公室2023年04月11日發布的《生成式人工智能服務管理辦法(徵求意見稿)》中第二十條提到,aigc服務提供者“構成犯罪的,依法追究刑事責任”。颯姐團隊之前已經在合規 | “投喂”AI作畫,或成侵權作品?!一文中研究過有關“投喂”的法律性質,我們從AI創作者的角度出發,認為一般情況下AI創作並不會構成侵權行為,但仍需個案判斷。今天我們將從AIGC服務提供者的角度,聊一聊涉及到的刑事法律問題。
首先我們再來回顧一下AI繪畫的原理。具體而言AI繪畫有三層機制。第一層是基礎邏輯層。AI繪畫能完成風格上的遷移。第二層是數據庫。在第一層基礎邏輯的基礎上,AI就需要大量的“喂圖”來進行學習和總結,獲得不同的圖像參數範例。這一步就是所謂的深度學習過程。第三層是創造性輸出。AI繪畫的厲害之處在於其生成的圖片不僅是符合文字描述的,更重要的是能夠創造出符合美學邏輯的圖像。在上一步的基礎上,AI需要通過人類工程師告訴它哪一種結果是美的,並調整增加此類輸出結果的比重。這一步就是範例學習。
通過長期往複的深度學習和範例學習,AI就掌握了一些通用的繪圖規律,並通過總結規律修正模型。因此,AI繪畫大體上又可以分為三個階段的工作,數據收集、數據處理、生產圖像。“喂圖”是其中第二步“深度學習”的核心,也是飽受爭議的一種行為。優秀的AI繪畫模型,必然少不了龐大的數據庫支撐,因此許多服務提供者會選擇使用“爬蟲”獲取大量數據。篇幅有限,以下我們主要分析對於AI繪畫服務提供者而言,AI繪畫服務提供者通過“爬蟲”獲取圖片后“投喂”AI繪畫這種行為是否有構成侵犯著作權罪的風險。

《中華人民共和國著作權法》(以下簡稱《著作權法》)對於著作權人的權利保護採取的是列舉的方式,並在第五章“著作權和與著作權有關的權利的保護”詳細列舉了諸多侵犯著作權的行為。但在《刑法》第二百一十七條侵犯著作權罪中僅列舉了六項行為,而這還是在最近的一次刑法改動——《中華人民共和國刑法修正案(十一)》(以下簡稱《修十一》)——中從四項增加至六項。《修十一》對該條作了較大改動,不僅提高了刑期上限,還對構成要件做了一定的改動。一方面,除“複製發行”行為構成侵犯著作權的行為要件外,“通過信息網絡傳播”行為也同樣構成侵犯著作權的侵權行為要件;另一方面,《修十一》還針對“採取避開或破壞技術措施”的行為加設了約束。
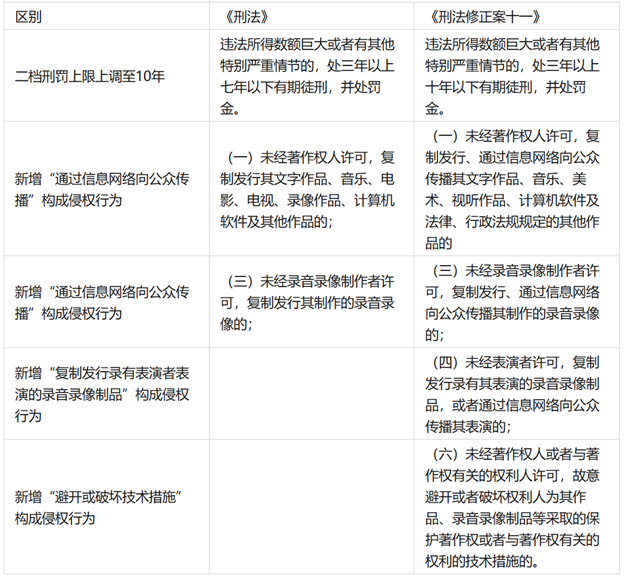
關於數據收集方面,以下我們主要討論是否會觸犯本條第一項與第六項。
其中第一項主要涉及複製發行與信息網絡傳播的問題。
關於複製發行的規定保護的是著作權人的複製權。根據《著作權法》第十條第五項,複製權是指:“以印刷、複印、拓印、錄音、錄像、翻錄、翻拍、数字化等方式將作品製作一份或者多份的權利”。複製是以現有已知或未知的方式,將作品固定在有形的物質媒介上,使得作品被他人感知、傳播、複製。因此我們認為一般要構成著作權法上的複製行為,該行為應當在有形物質載體上再現作品。只有通過一定的物質形式,作品才能獲得固定性,使原作和複製件具有明顯的對比關係。而將其作為數據存儲,獲得其圖像參數範例時,尚未進行輸出的時候,我們很難認定其侵犯了作者的複製權。
關於信息網絡傳播的規定保護的是著作權人的信息網絡傳播權。根據《著作權法》第十條第十二項,信息網絡傳播權是指以有線或者無線方式向公眾提供作品,使公眾可以在其個人選定的時間和地點獲得作品的權利。而一般我們認為,AI繪畫服務提供者的數據庫是非公開的,公眾沒有機會直接獲得作品。那麼另一方面,公眾能否通過使用AI繪畫服務間接獲得原作品呢?我們認為也是不大可能的。這類的AI生成模型的核心技術能力就是,把人類創作的內容,用某一個高維的“向量”進行表示。如果這種內容到向量的“翻譯”足夠合理且能代表內容的特徵,那麼人類所有的創作內容都可以轉化為這個空間里的向量,那麼此時我們有可能通過給出所有的向量從而還原最初的內容。但目前我們的“翻譯”顯然還不具有這種能力,即大量現實世界的內容是無法被AI系統的“向量”所概括。因此我們認為即使想通過關鍵詞等溯源,公眾依舊是無法獲取原作品的,AI繪畫服務不會侵犯著作權人的信息網絡傳播權。

其中第六項主要涉及“反向工程”的認定問題。《著作權法》第四十九條賦予了著作權人採取技術措施的權利,現實中隨着人們權利意識的增強也往往開始採取設置瀏覽權限等方式保護自己的作品,此時“爬蟲”無法直接獲取作品,但通過一定的技術手段也可避開技術措施獲得作品。目前我國還沒有關於因通過“爬蟲”繞過或破壞技術措施獲取數據而認定為侵犯著作權罪的裁判案例,但存在因為未經著作權人許可,複製遊戲數據后修改其作品採取的保護著作權或者與著作權有關的權利的技術措施,而被認定為侵犯著作權罪的案例(案號:(2022)滬0107刑初81號);民事案件中,也存在將通過“爬蟲”避開技術措施認定為侵犯信息網絡傳播權的裁判((2016)京73民終143號)。綜上,我們並不排除通過“爬蟲”繞過或破壞技術措施獲取數據而被認定為侵犯著作權罪的可能。
同時根據《著作權法》第五十條,避開技術措施是有例外情形的,即滿足條件的情況下是允許避開技術措施的。

但顯然經過檢索,我們無法將“爬蟲“行為歸類入以上範圍內。以上談論的《修十一》對侵犯著作權罪第六項的更改是跟隨2020年《著作權法》修法的產物,其承接了對直接規避行為與間接規避行為均持反對的態度。但學界大多數觀點認為,我們不應禁止直接規避行為,即對於直接規避行為,應通過檢閱其後續使用行為是否侵犯著作權,構成直接侵權,從而對其進行規制。循此思路,則具有審查是否符合條件較為寬泛的“合理使用”之餘地,即我國《著作權法》中“著作權的限制”。不過退一步而言,即使採取了以上立法觀點,“喂圖”也很難歸入“合理使用”的範疇以內。
綜合以上,我們認為“喂圖”這種行為一般不具有構成侵犯著作權罪的風險,但若是通過“爬蟲”並避開相應的技術措施對AI繪畫進行“投喂”,將可能構成侵犯著作權罪。
寫在最後
“版權”在18世紀正式出現並發展,於1709年由英國《安娜女王法》的頒布而得此確立,距今已有三百多年。版權或著作權的本質是通過賦予其一定的垄斷對智力勞動成果進行法律保護,從而鼓勵智力勞動。隨着時代變遷,科技進步,人們的智力成果呈現多樣化的態勢,著作權通過正面列舉認定的方式進行保護,必然會較於時代發展滯后。一方面,我們應當鼓勵共享與開放的未來,在信息化時代數據共享使用將是時代浪潮;但另一方面,我們也應當注意在AI迅速發展下的現實場景下應當在何種程度上以何種方式保護著作權。目前無論提供AIGC服務的行為性質如何,其在繪畫領域的發展已經對該行業產生了巨大的影響。大量的原畫師失業已是不爭的事實,“AI繪畫師”這一職業卻冉冉升起。我們在考慮AIGC相關創作是否違反有關知識產權的相關法律規定的同時,是否應當給予更多人文視野的關懷於這些不願接納AIGC時代的人們呢?