所有語言











分享
百川智能首款AI助手大秀神操作!Baichuan 4強勢升級登頂國內第一
巴比特_AIcore332天前
文章來源:新智元
【導讀】時隔4個月,百川智能的基座大模型又雙叒升級了!新一代Baichuan 4出世直接登頂國內第一。不僅如此,首款最懂搜索、會提問的AI助手「百小應」正式殺入移動APP戰場。

圖片來源:由無界AI生成
近半個月,國外科技大廠們連番轟炸,GPT-4o、Project Astra、Copilot+ PC的誕生讓人目不暇接。
而國內大模型這邊也是毫不示弱,不斷地推陳出新、迭代升級。
就在今天,歷時4個月打磨,百川智能發布了新一代基座大模型Baichuan 4。
不僅如此,他們還帶着自家首款AI助手「百小應」殺入移動APP戰場。
試玩地址:ying.ai
與吊人胃口的OpenAI不同,iOS和安卓版應用程序今天一併推出,並且免費使用。
毋庸置疑,「百小應」已經用上了升級后Baichuan 4基座大模型的能力,與其他的AI助手一樣,讀文件、獲取最新信息、整理資料、輔助創作等各種問題,「百小應」通通可以解決。
但與眾不同的是,「百小應」將Baichuan 4的能力與其天然的搜索技術優勢進行了深度融合。
它不僅具備多輪搜索的能力,甚至還可以定向搜索,可以被看作是最懂搜索的AI助手。
說這麼多,不如來一波深度體驗。
懂搜索、會提問的AI「夥伴」
在試用過程中,小編深深地體會到,「百小應」絕不僅是連接信息的工具,而是真正成為了一個提供知識和服務的AI助手,甚至有了一點夥伴的味道。

百小應的名稱源自「一呼百應」
多輪搜索
在以往的搜索產品中,我們通常只會得到一個搜索結果。推一步才能走一步,非常被動。
但百小應不同,在得到搜索結果后,它還會結合用戶的問題開啟「自我反思」。
比如,它會自主判斷當前提供的資料是否足夠詳實,從而來自主決策,是否需要進行更多輪次的搜索。
當我們問「含能材料的行業前景」,它就自己去進行了2輪搜索,然後給出了高度概括的介紹。

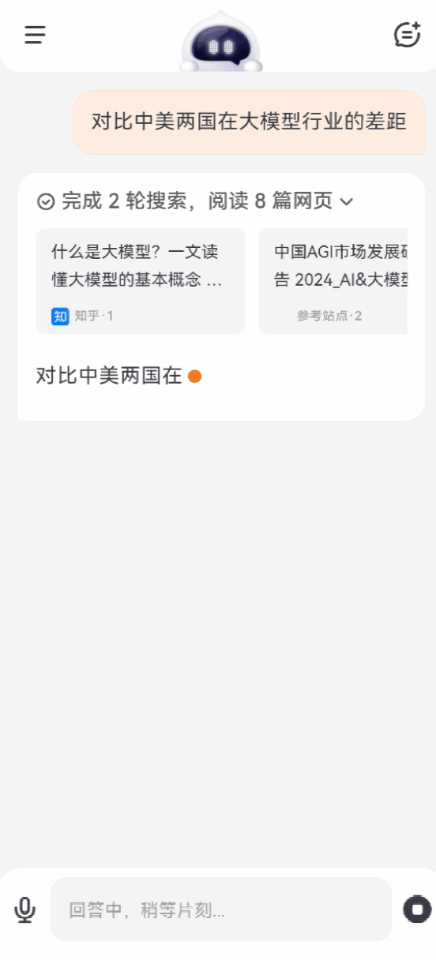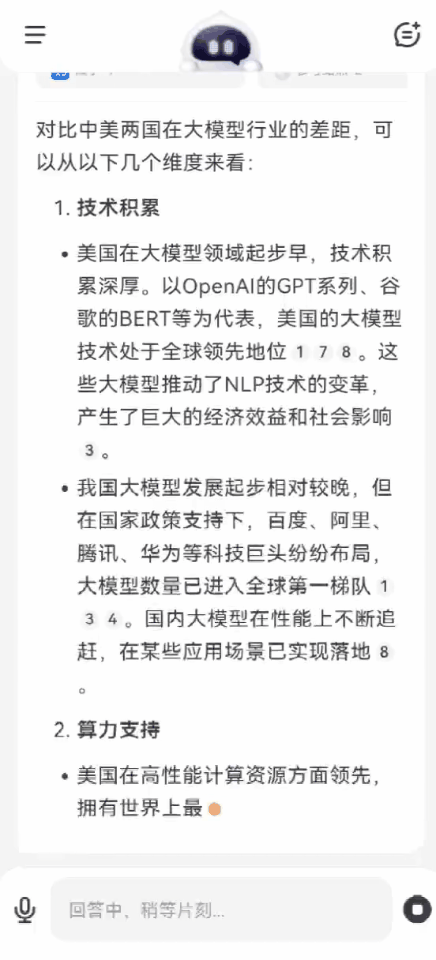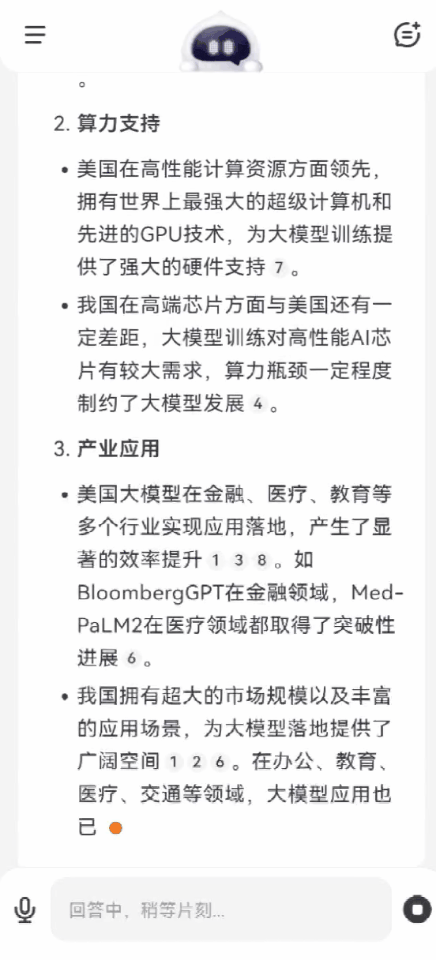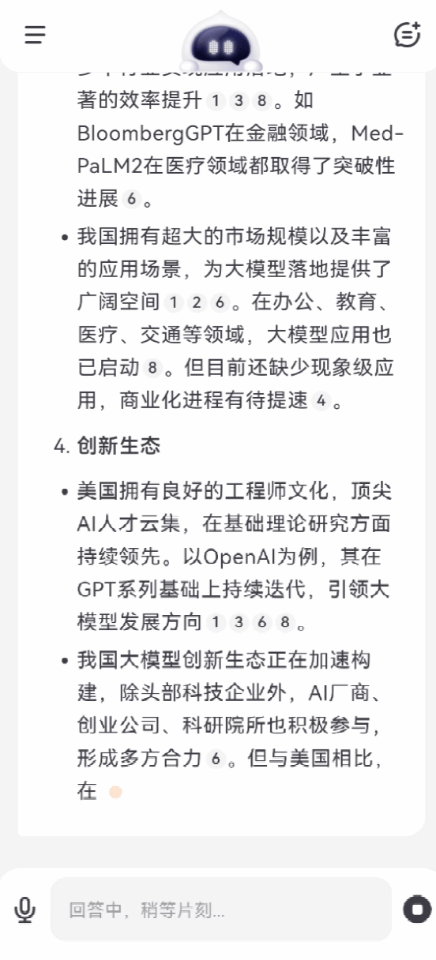
再問一個問題:中美兩國在大模型行業的差距,究竟有多大?
百小應同樣自動完成了2輪搜索,在技術積累、算力支持、產業應用、創新生態等方面,給出了客觀中肯的分析。

可以看出,如果遇到市場調研、產業分析這類複雜場景,多輪搜索就能發揮最大的效力,更有效地獲取更專業、更有深度的信息。
而在搜索結果的呈現上也可以看出,百小應相比其他搜索產品的獨特之處。
它不是簡單的總結網頁信息,而是會將搜索結果嵌入回答中,成為回答的支撐或者創作的一部分,這樣我們就有了參考資料來源,不必擔心結果是無本之木、無源之水了。
除此之外,百小應在結果的結構化上,也做得非常優秀。
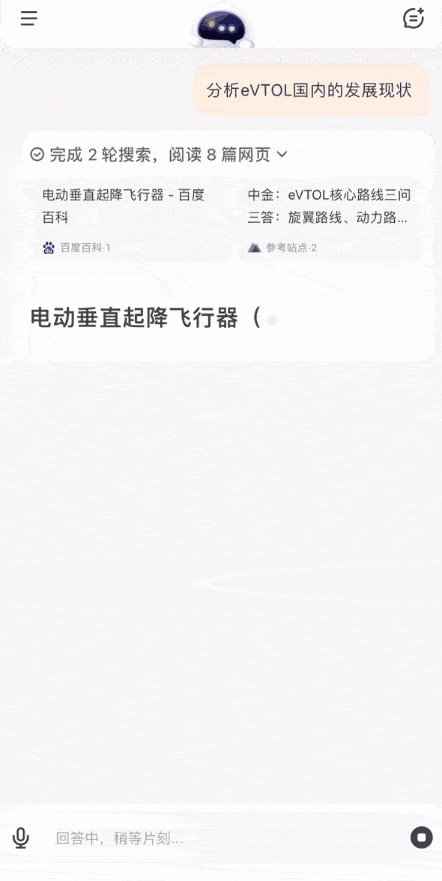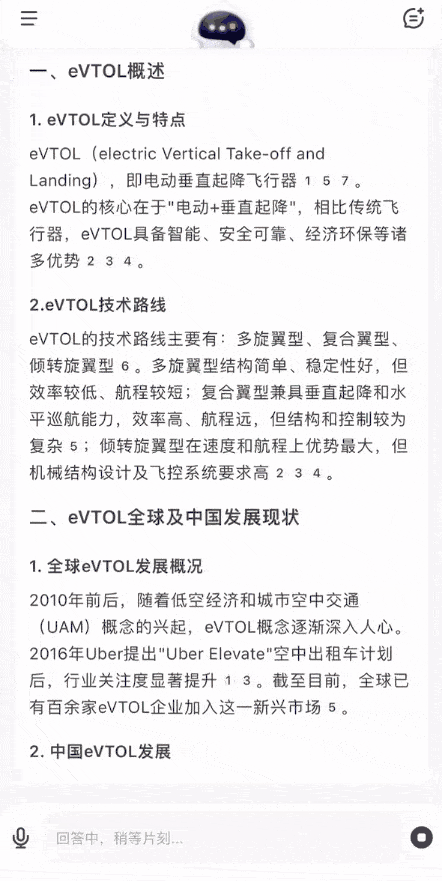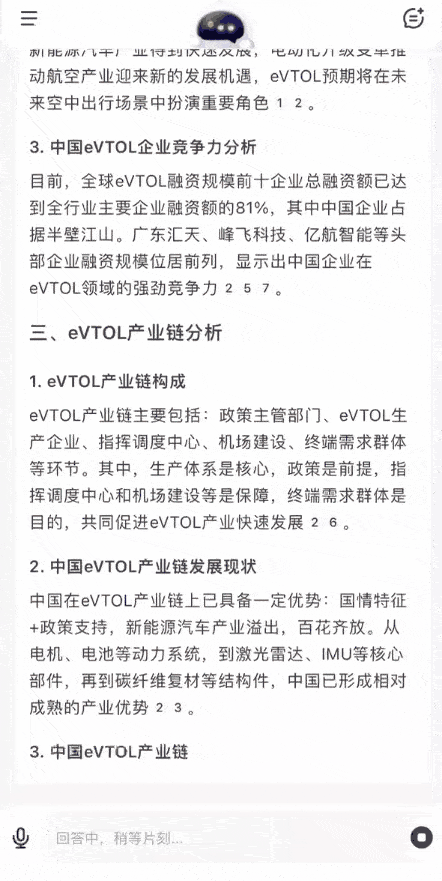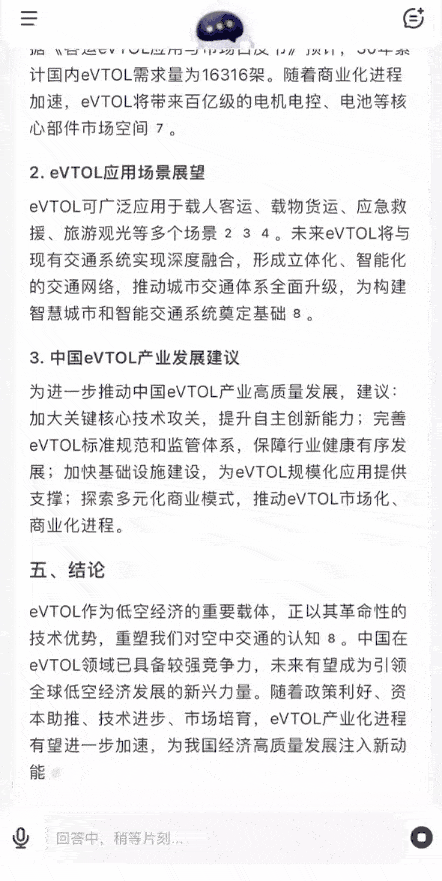
作為市場研究,上面這份輸出的格式很標準,可以為行業分析、調研工作提供強大的助力。
定向搜索
很多時候,我們需要精準定位問題領域,直接訪問權威站點。
百小應的「定向搜索」,此時就显示出了強大的功能。
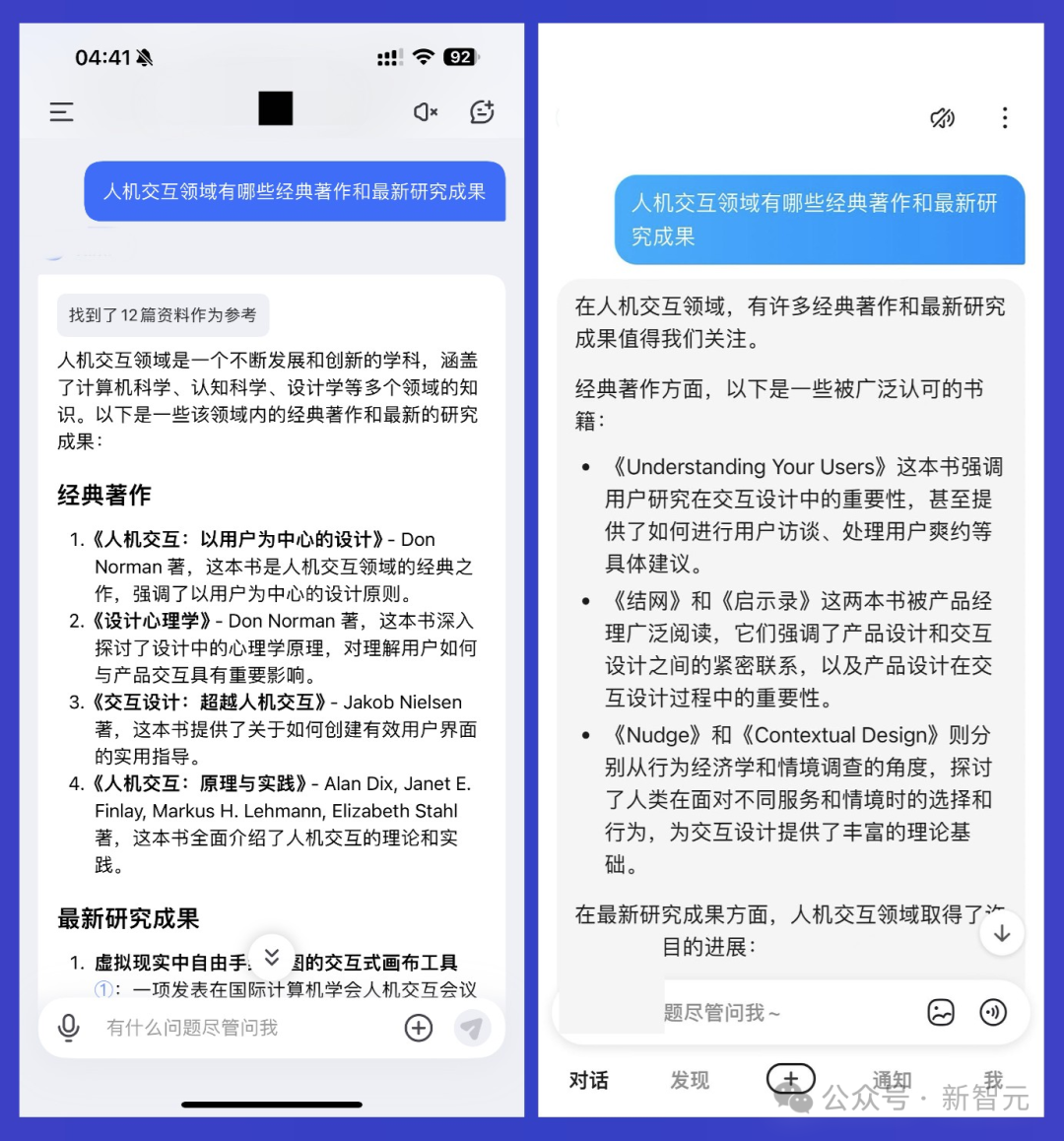
我們可以直接問它:人機交互領域有哪些經典著作和最新研究成果?
通過2輪搜索,它精準地找到了知乎上的參考資料,詳細給出了領域內的經典著作和最新論文。

從它給出的論文鏈接中,我們直接就可以查閱arXiv上對應的論文。
相比之下,其他智能助手僅僅是針對搜索結果做了大致的總結。
下面,我們試着讓百小應在arXiv上找出關於RAG的最新研究成果。
果然,它會選擇直接訪問arXiv,讓我們更高效地鏈接到想要的結果,不必在多餘的繁雜信息中浪費時間。

會提問
一次流利的搜索體驗,是由產品和用戶共同完成的。
一方面,模型需要掌握專業的搜索技能,懂得什麼是搜索;而另一方面,用戶也必須會表達,才能真正通過AI來尋找到自己想要的信息。
雖然以上是最理想的情況,然而現實中,表達清楚自身需求,對很多用戶是個困難的事兒,或者說懶得費那個腦子。
這種情況下,就需要讓模型來引導用戶「表達」了。
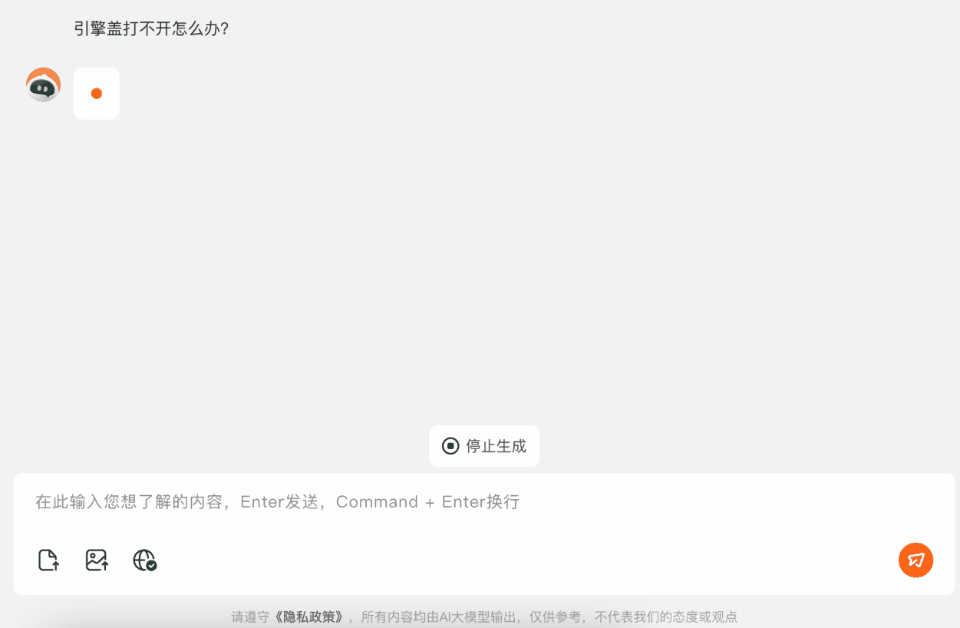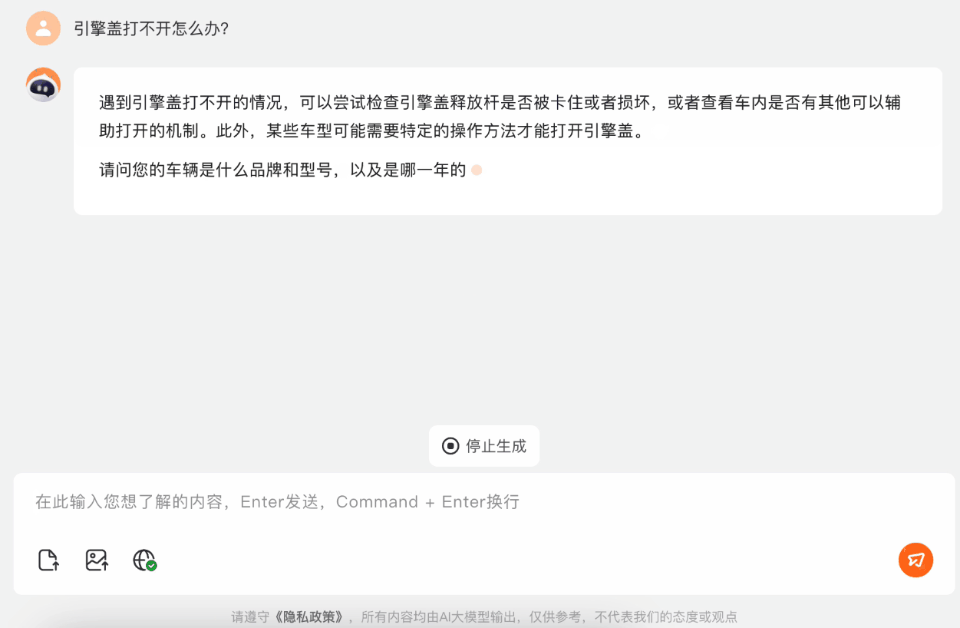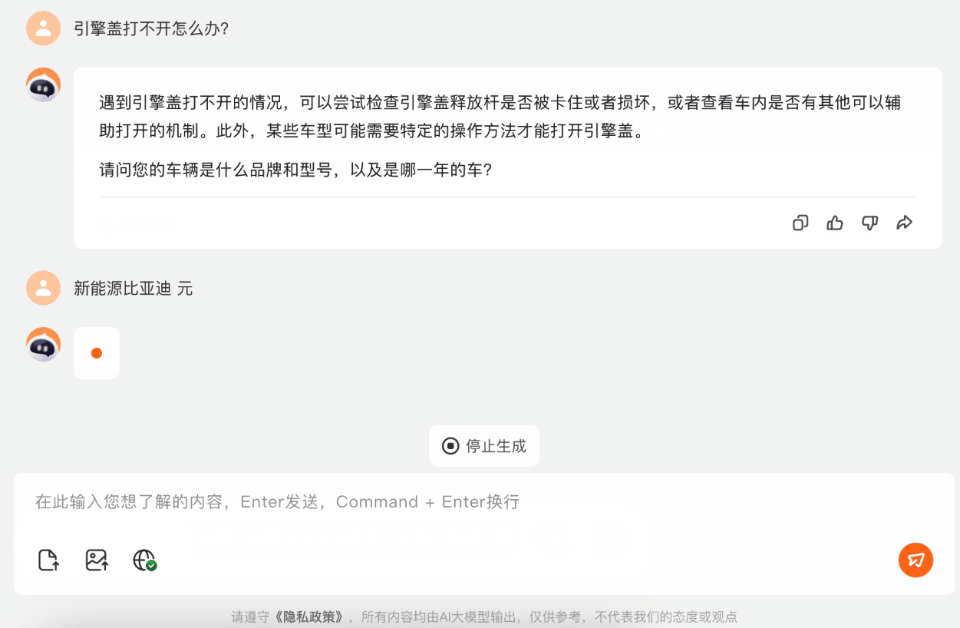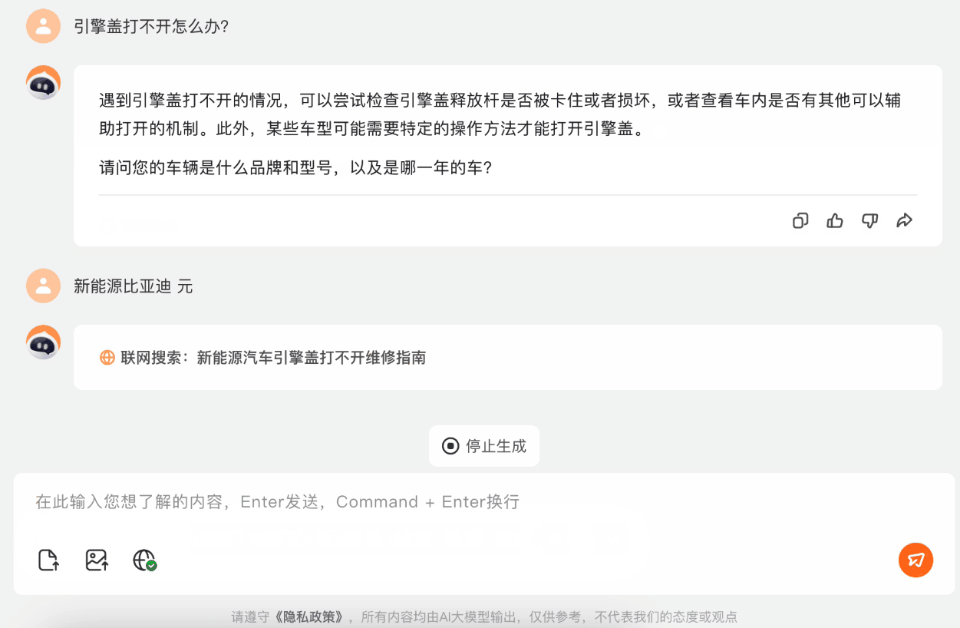
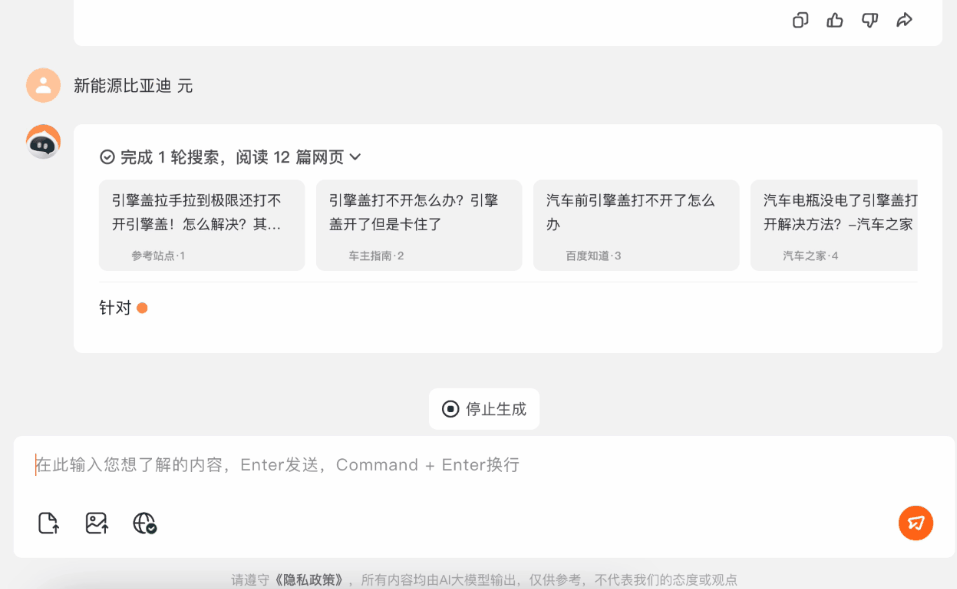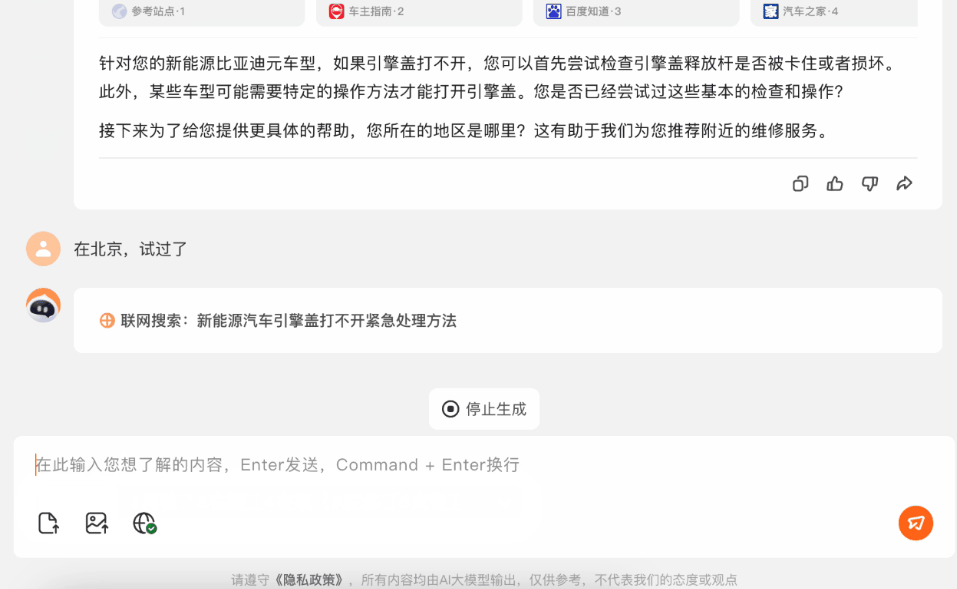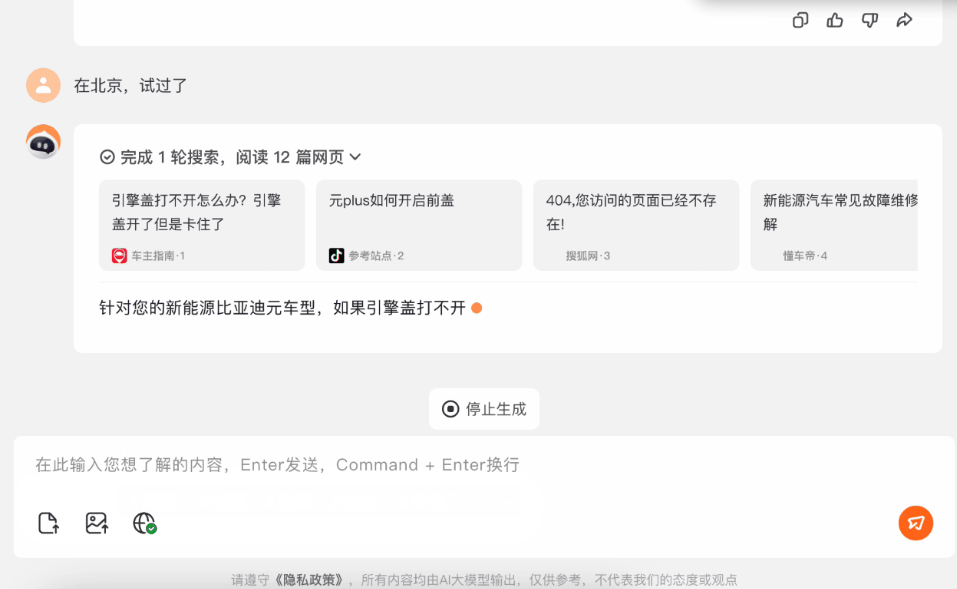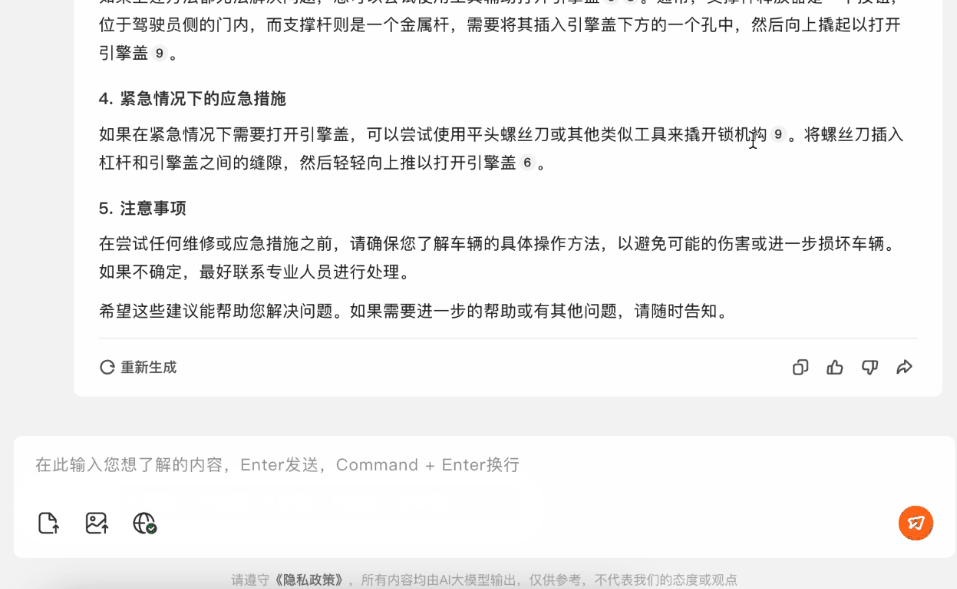
遇到引擎蓋打不開的情況,可以直接問百小應。
不過這個問題的答案,取決於車輛的品牌、型號、出廠年份。一般人去提問,應該是不太可能一開始就提問得這麼周全的。
不用擔心,百小應會通過提問來指導你。
在它的引導下,我們給出了車型的關鍵信息:比亞迪元。
這下百小應給出的信息,就更精準了,在提問了我們所在地區這個信息之後,它甚至給出了北京4S店的聯繫方式和地址。
想要策劃一場浪漫的草坪婚禮,不如讓「百小應」當你的婚禮的私人訂製策劃師。

這時,「百小應」並沒有根據籠統的問題,一通亂答,而是繼續引導我們給出明確的細節。
「為了更好地幫您規劃,我需要了解包括預算,參加人數等一些額外的信息」。

在提供了預算20萬左右,50人參加的信息之後,「百小應」立即給出了非常細緻的定製方案。
從場地選擇推薦、婚禮布置裝飾、婚宴餐飲,再到音樂草坪遊戲,攝影錄像,都為你一併規劃好了。

更驚喜的是,它最後還貼心地為我們做了所有的預算分配。

再來看一個演示,當你想要寫一個「天津之眼」的種草文案,「百小應」同樣先去提問,了解真正需求。
- 您希望這篇文案吸引讀者哪類讀者?(諸如旅遊愛好者、情侶推薦,還是家庭旅遊)
- 您希望通過這篇文案傳達哪些主要內容和情感?(比如,浪漫氛圍、歷史文化、刺激體驗等)

然後,你就可以從這些給定的選擇中進行挑選,或提出自己的想法皆可。
接下來,「百小應」便會根據要求生成文案,簡短的文字着重體現了「天津之眼」獨特魅力所在。

綜上演示,「百小應」之所以能夠輸出精確的結果,主要歸功於「會提問」,通過提問引導、激發用戶清晰表達自身具體需求,為每個人構建出個性化的解決方案。

多模態
在Baichuan 4多模態能力的支持下,「百小應」還可以對圖片內容進行解讀。
又或者,將圖片作為補充材料,獲取更精準的回答。
最近比較火的AI開瓜,看看「百小應」能不能挑出,哪顆是最甜的瓜。

根據「百小應」的判斷,一般西瓜表面條紋越清晰、顏色越深綠,可能代表着西瓜更成熟。
從圖中看,推測得出,6和7看着條紋非常清晰。
不過,它還是提醒我們,僅從外觀上判斷西瓜甜度並不準確。

小編這就去開瓜了。

再來一張經典的重慶地標夜景圖,不知「百小應」能否認得出?

顯然,這個問題根本難不倒它。
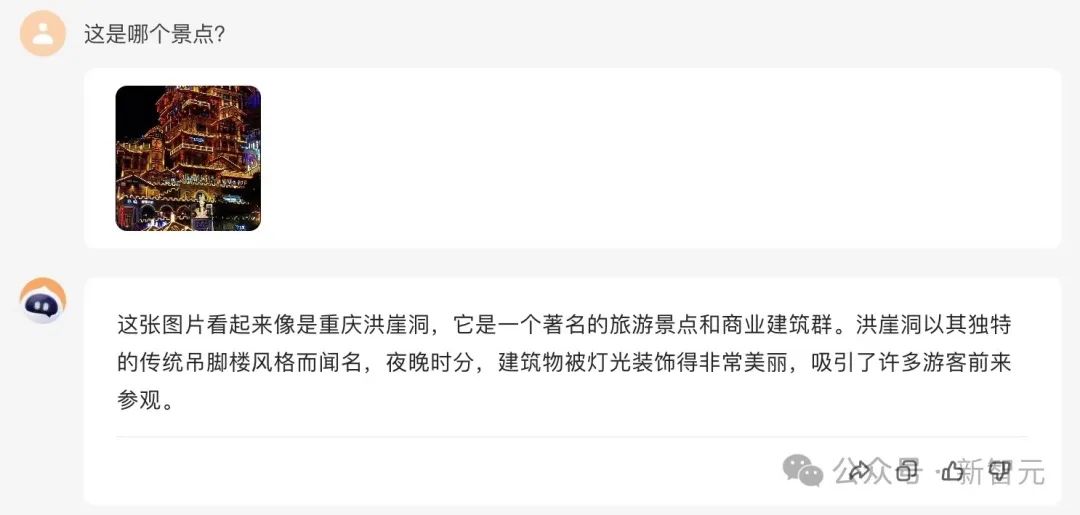
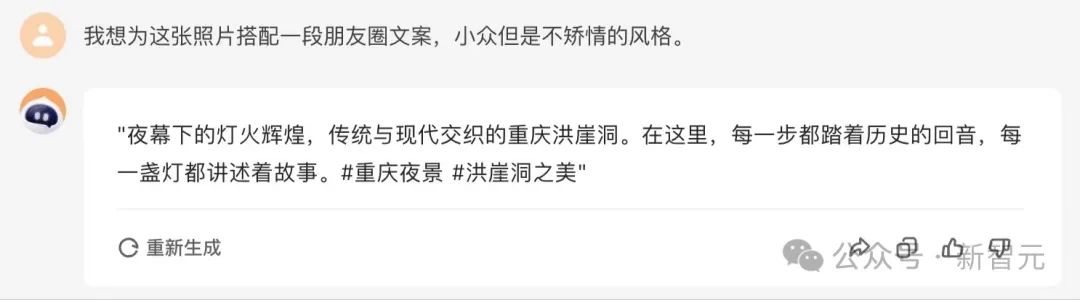
你甚至,可以讓它就這張圖片,生成一份朋友圈文案。
「百小應」真的很會,生成的文案內容非常吸睛,同時還體現出了小眾但不矯情的風格。
文檔速讀
除了以上提到的能力之外,「百小應」還支持上傳PDF、Word文檔,網頁鏈接皆可行。
這就非常適合,需要大量閱讀長篇幅文獻、報告等內容的科研者,或是解析複雜數據表格的金融分析師等。
「百小應」可以做到,僅用1分鐘的時間,讀完上市公司財報。
比如,上傳一份長達31頁的特斯拉2024年第一季度財報文件。
然後要求「百小應」去解讀財報,總結出值得關注的信息,並給出相對應的原文。
沒想到,眨眼的功夫,「百小應」總結出了十個要點,並配上原報告highlights的內容。

再給它po一個鏈接,總結GPT-4o發布會的一些關鍵要點。

「百小應」的輸出結果,基本上覆蓋了全部的要點。

此外,「百小應」還可以支持通過語音的方式進行交互,簡直是「手癌」患者的福音。

大模型時代新物種,AI不再是「工具」
經過一番實測之後,「百小應」已經在長文本閱讀、多模態理解、提問搜索等多方面任務上,表現出強大的能力。
百川智能認為,讓AI從工具變為夥伴,基於大模型打造的AI助手更像是在「造人」。
就像人類能夠利用工具,聽說讀寫看,甚至會思考一樣,AI助手隨着基座模型迭代,也將具備相應的能力。
雖然當下的AI助手還不具有情感、記憶、決策等高階能力,距離「夥伴」還有很長的路要走,但是AI助手已經具備了部分夥伴所需要的能力,比如會思考,會用工具。
而搜索正是當下AI助手最重要的工具。

只有將大模型與搜索相結合,才能發揮出巨大的優勢。甚至,人們普遍認為大模型的第一波應用,就是在搜索。
為什麼這麼說?
大模型飽受詬病的「幻覺」問題,是無法避免的,而植入搜索可以提升LLM回答準確性,早已成為行業共識。
其實,國內外大部分企業,早已給自家AI助手類應用增加了搜索功能。
但同樣的搜索,卻有着不一樣的思路。
一種普遍的做法是收到用戶的指令后,搜索相關信息,然後總結搜索結果進行輸出。
而百川智能認為,大模型+搜索應該是在回答中嵌入搜索結果,用搜索賦能大模型,提高模型回答的鮮活性,讓大模型言之有物,而不是用大模型賦能搜索。
由此,我們所看到的「百小應」,才是APP中懂搜索、會提問的那個應用。

百小應之所以能將大模型與搜索的能力很好地融為一體,是因為搜索一直是百川智能探索LLM的重點方向之一。
這家公司創始人和研發團隊有着多年的前沿搜索經驗,在去年發布首款閉源模型Baichuan 53B時就採用了「搜索增強技術」,大大提升了基座模型的輸出結果的性能。
首款AI助手「百小應」能夠表現不凡,當然也離不開此次基座模型Baichuan 4能力的大升級。
Baichuan 4登頂國內第一
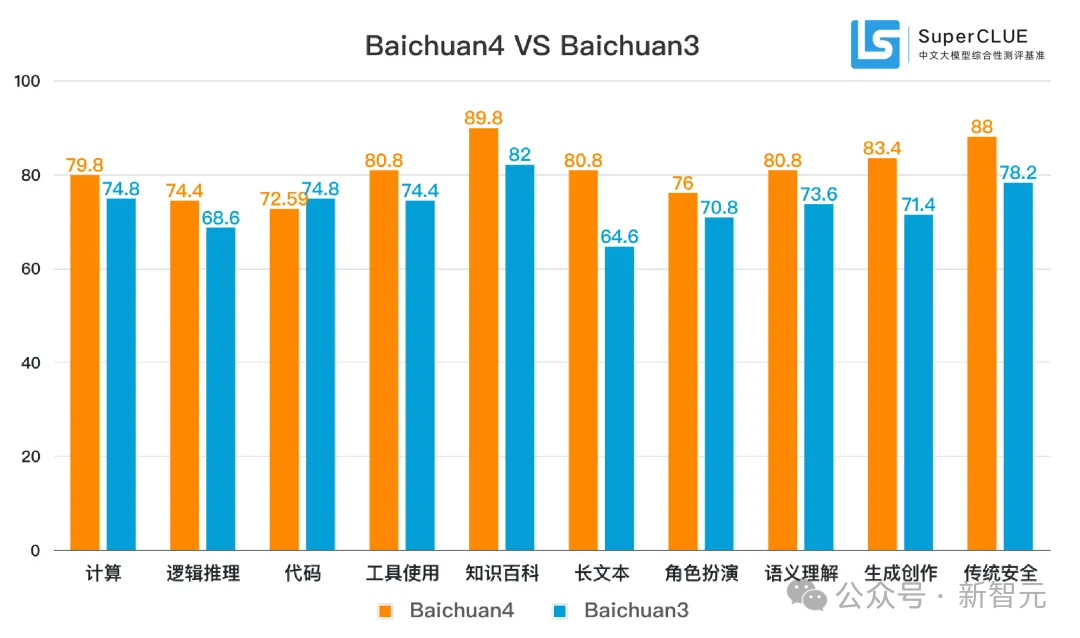
Baichuan 4相較於上一代Baichuan 3,在通用能力上有着顯著提升。
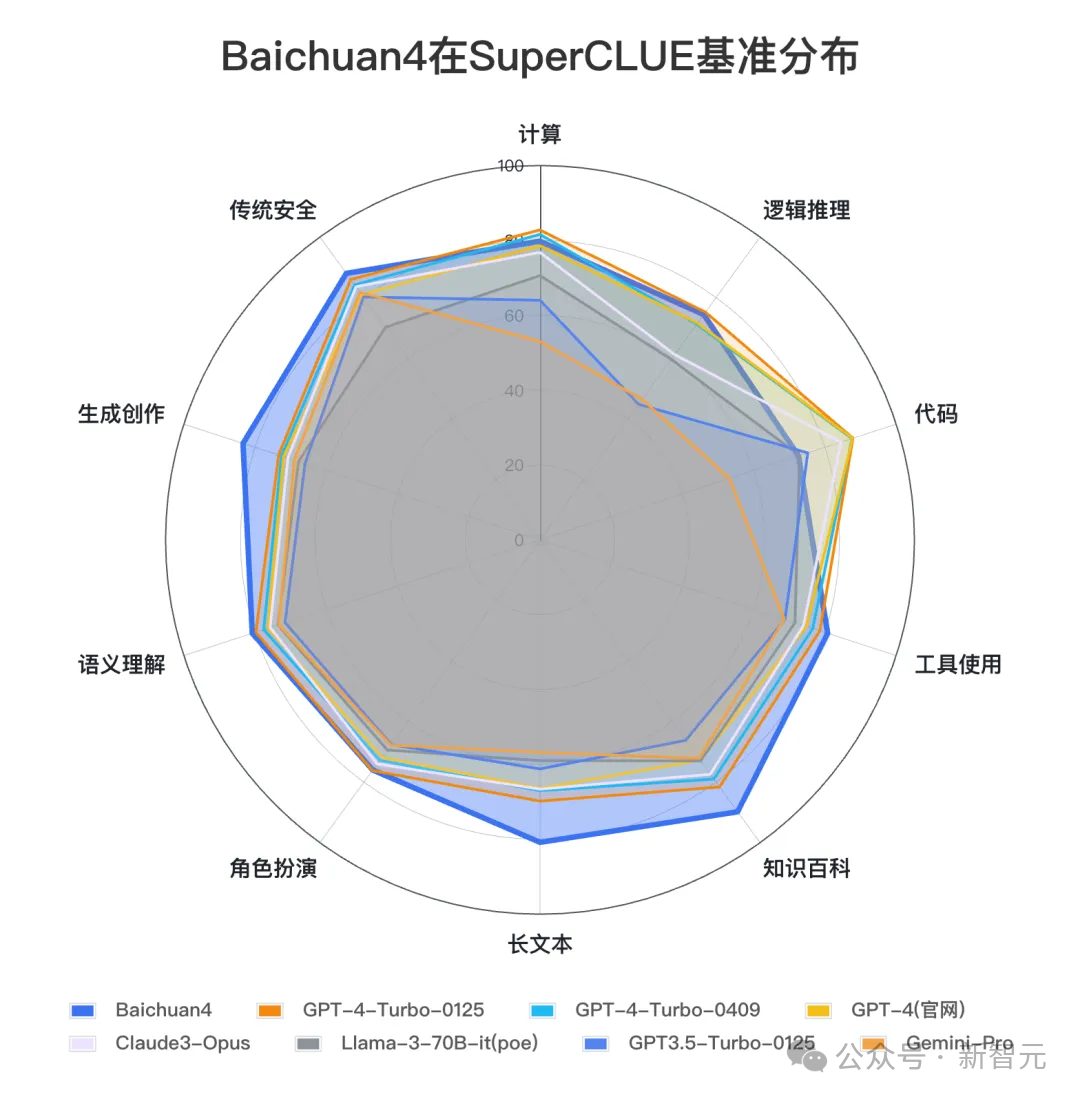
在剛剛發布的SuperCLUE權威中文評測中,Baichuan 4以80.64分成績,登頂國內第一。
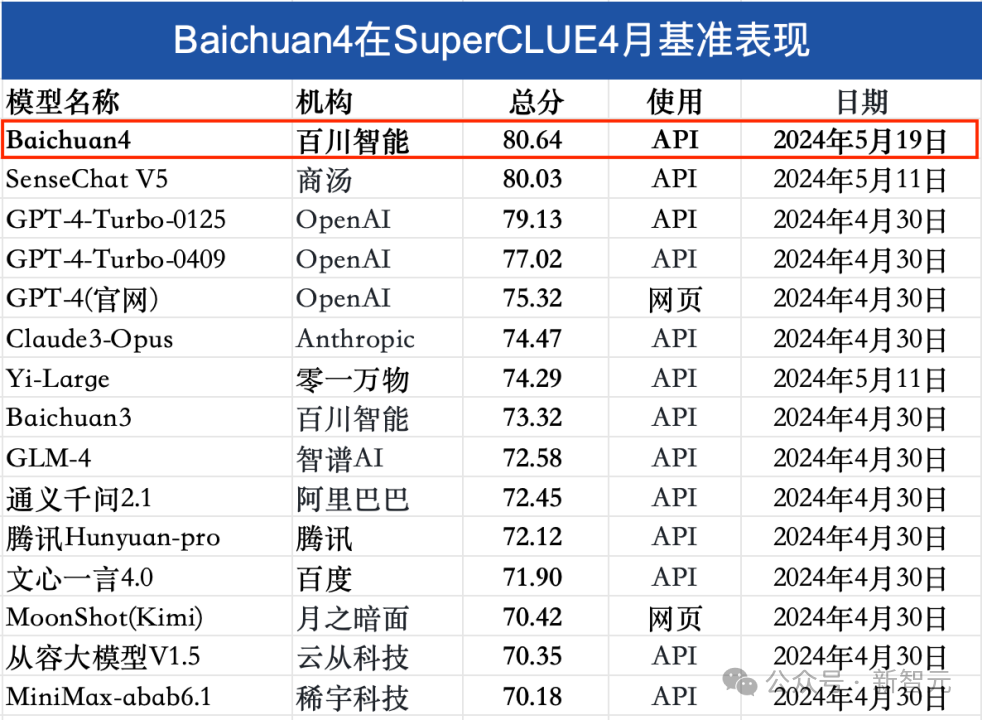
SuperCLUE總榜
具體來看,在理科任務中,Baichuan 4表現不俗,以 76.90 分的成績排名國內第一。
然而,與GPT-4-Turbo-0125相比,相差4.23分,仍有一定的提升空間。
其中,邏輯推理(74.4分)、工具使用(80.8分)這兩項均刷新國內最好成績。
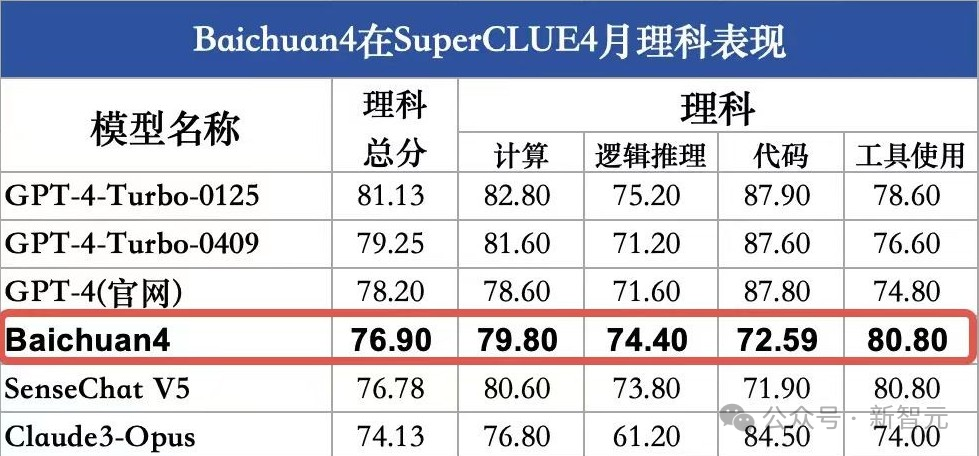
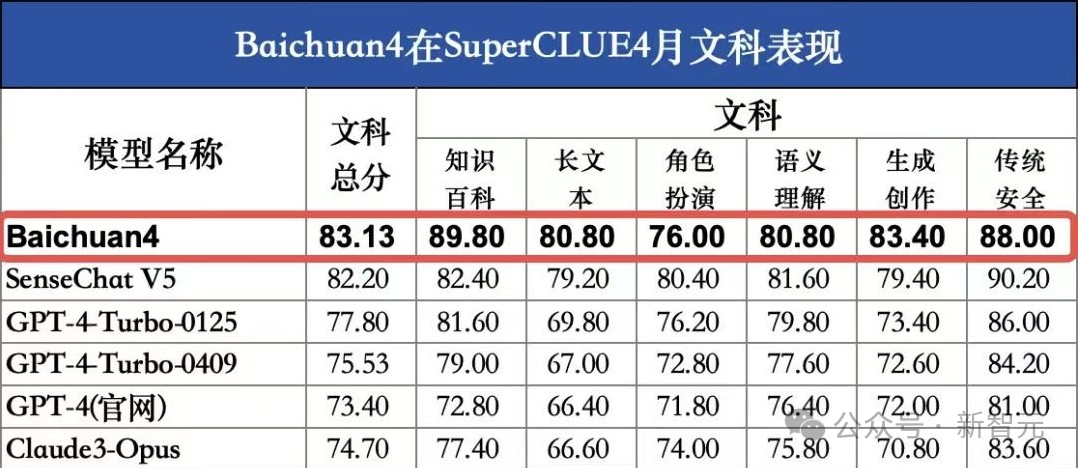
在文科任務中,Baichuan 4取得了83.12高分,文科能力全球第一,比GPT-4-Turbo-0125高出5.33分。
其中,知識百科(89.8分)、長文本(80.8分)、生成創作(83.4分)、傳統安全(90.2分)均刷新國內最好成績。
在與國內大模型平均得分相較下,Baichuan 4在所有能力上均高於平均線,展現了均衡的綜合能力。
尤其是,在邏輯推理(+18.64)、代碼(+18.89)、長文本(+20.77)能力上遠高出平均線15分以上。
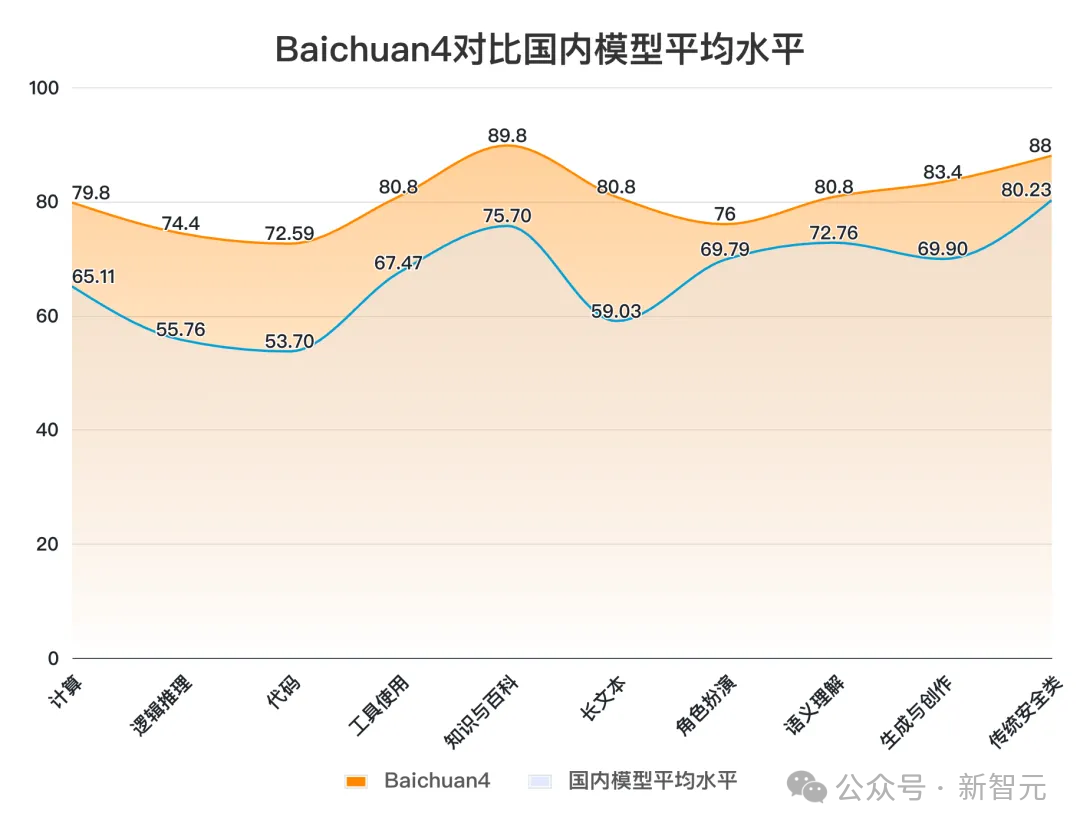
而與國外主流大模型對比,Baichuan 4在文科類任務取得領先優勢。
特別是在知識百科、長文本理解、工具使用、語義理解和創意生成等方面,表現突出。
這使得Baichuan 4非常適合應用於知識運用、智能體、內容創作和長程對話等多種場景。
然而,它在代碼能力方面仍有提升的潛力。

多模態能力僅次於GPT-4V
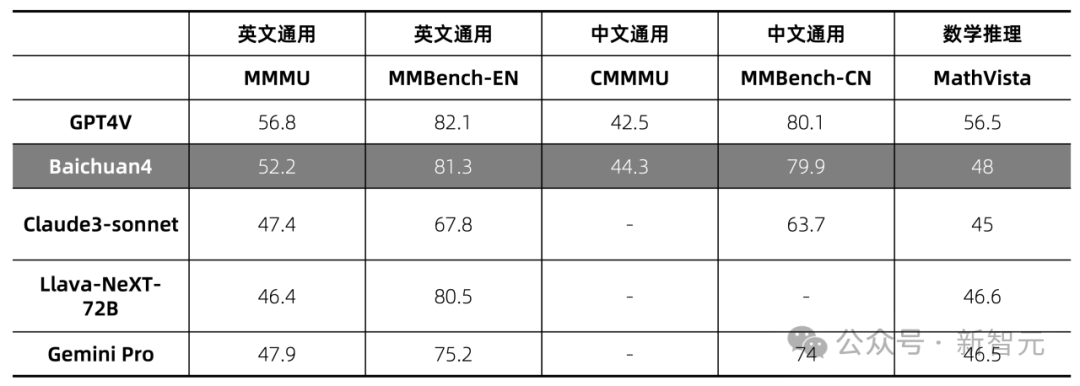
此外,在各大基準測試中,Baichuan 4還具備了行業領先的多模態能力,表現更加亮眼。
具體在MMMU、MMBench-EN、CMMMU、MMBench-CN、MathVista等評測基準上,新模型實力僅次於GPT-4V,完全碾壓Gemini Pro、Claude 3 Sonnet等模型。
技術創新
為什麼Baichuan 4,能夠在4個月這麼短的時間取得突破?
一切都源於,其在訓練過程中引入了很多業界領先的技術優化手段。
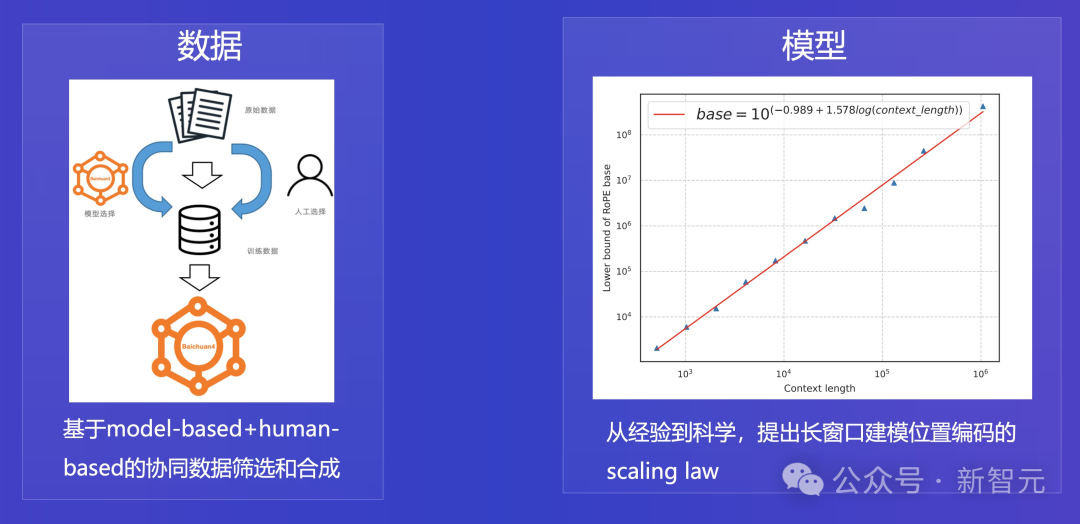
在預訓練階段,為了有效提升LLM對數據的利用,新模型採用了基於Model-based+Human-based的協同數據篩選優化,並對長文本建模位置編碼科學的Scaling Law。
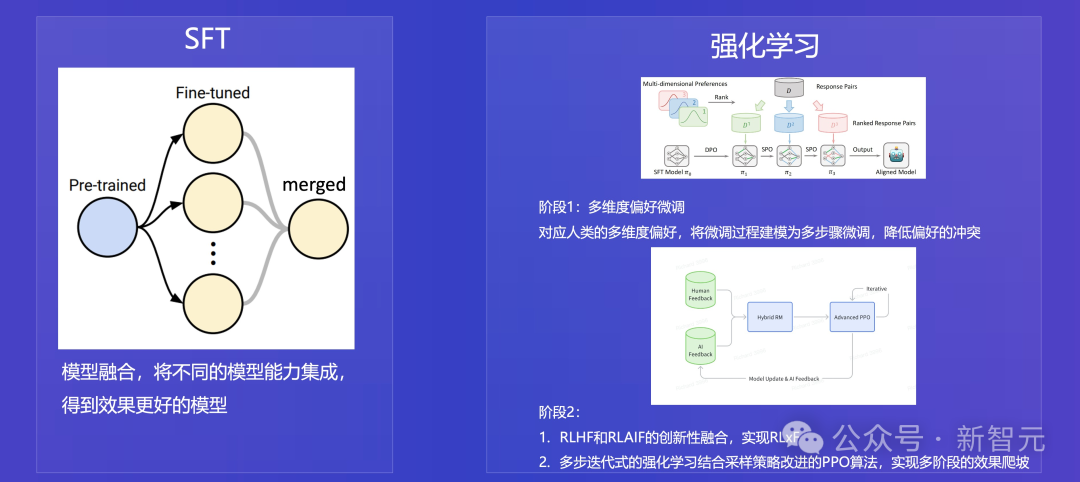
在對齊階段,還重點優化了模型推理、規劃、指令跟隨的能力,通過「損失」驅動數據選取與訓練,階段爬坡,多模型參數融合等方式,有效提升LLM關鍵指標和穩定性。
同時,團隊還採用了RLHF和RLAIF融合后的「RLxF」,強化學習對齊技術,大幅提升模型的指令跟隨等能力。
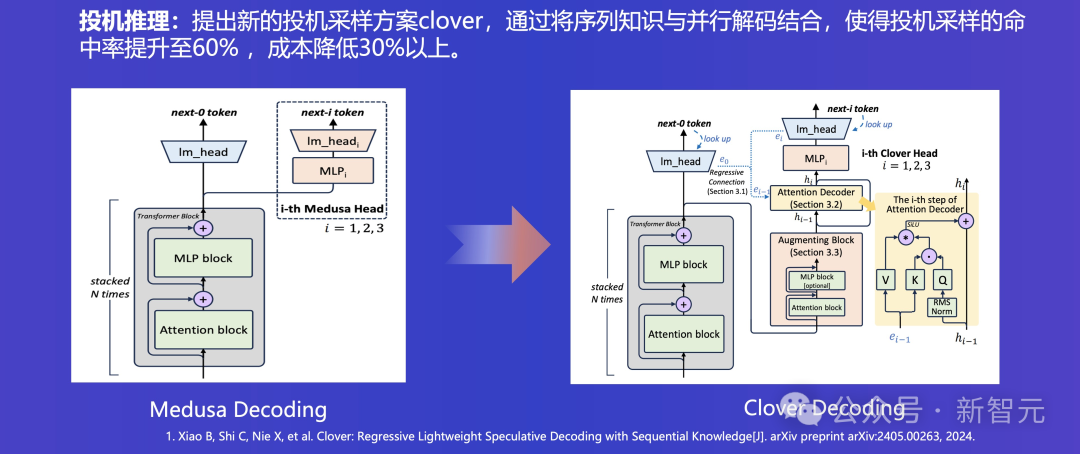
此外,Baichuan 4另一項的技術創新便是為LLM推理提速,提出了全新的投機採樣方案clover。
通過將序列知識與并行解碼結合,使得投機採樣的命中率提升至60% ,同時成本降低30%以上。
1000萬token免費薅,零代碼Agent即將上線
發布會現場,百川智能推出了全新的MaaS+AaaS服務。
對於企業來說,需要的並不是大模型,而是生產力、生產效率的提升。
百川智能認為,擁有MaaS+ AaaS(Agent as a service)雙重能力,企業才能構建出智能化的最佳方案。
MaaS版塊由基座模型組成,分為旗艦版和專業版。
旗艦版將全量開放Baichuan 4的各項能力,Baichuan 4不僅擁有國內第一的中文能力,並且具備行業領先的金融知識和問答能力,在SuperCLUE的金融知識百科能力上,Baichuan 3曾取得了A+的最高評級。
專業版,則包含Baichuan3-Turbo和Baichuan3-Turbo-128K兩款模型,在價格方面相比旗艦版Baichuan 4更實惠。
而且,這些模型均針對企業用的高頻場景進行了針對性優化,綜合測試相比GPT3.5整體效果提升8.9%。
百川智能表示,即日起,MaaS的新用戶可以獲得1000萬免費token!
在Baichuan 4基礎上,百川智能針對Agent構建,推出了Assistan API接口。
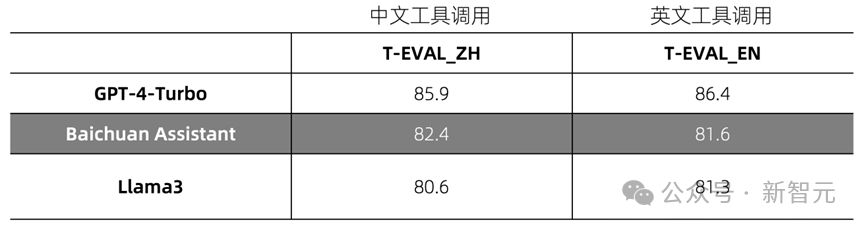
它不僅支持Code interpreter、RAG內建工具,還支持自定義工具調用,方便企業接入各種豐富複雜的API。
評測結果显示,Assistant API的工具調用能力,已經接近了Open AI assistant API的水平。現在,Assistant API已經正式開啟內測邀請,試用免費!
接下來,百川智能還將推出零代碼Agent創建平台產品。
任何業務人員,都可以通過自然語言創建Agent,更好地賦能企業智能化發展。
在生態方面,百川智能的「朋友圈」可以說範圍之廣。
目前已經服務了了數千家客戶,包括完美世界遊戲、愛奇藝、 創夢、什麼值得買等各行業的領軍企業。
同時,還與與信雅達、用友、軟通動力、新致軟件、達觀數據等多家行業生態夥伴,以及華為、曙光等硬件廠商和中國移動、電信、聯通等運營商達成合作,攜手構建百川大模型生態。
順便提一句,百川智能在成立1年多的時間里,以超乎想象的研發速度,共發布了12款大模型。
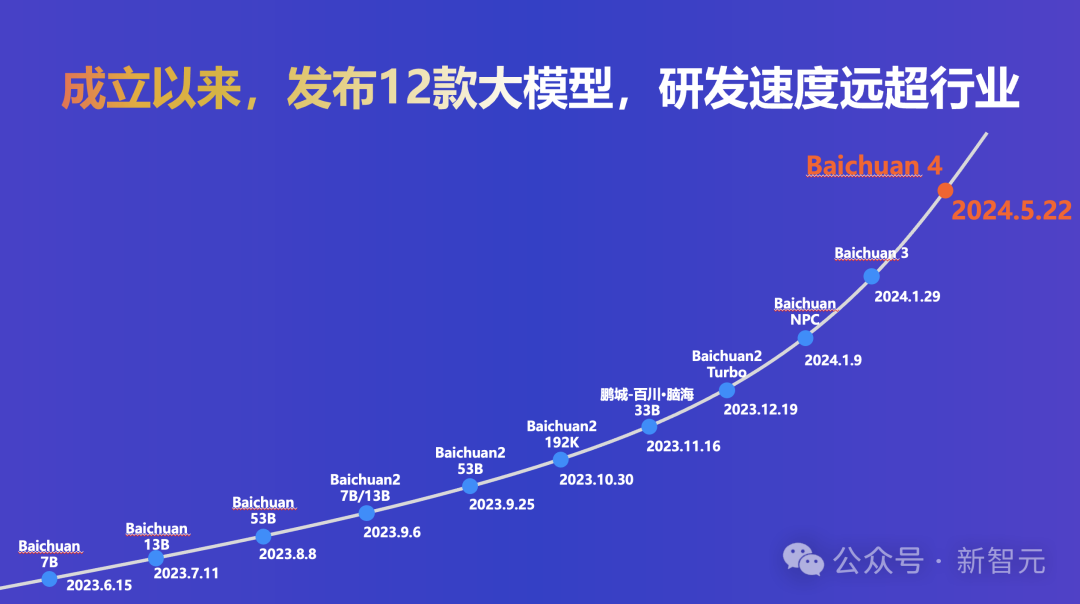
Baichuan 4之後,不知還有什麼樣的驚喜等着我們。
參考資料:
https://ying.baichuan-ai.com/chat