所有語言











分享
零一萬物Yi-1.5來了,國產開源大模型排行榜再次刷新
巴比特_AIcore340天前
文章來源:機器之心

圖片來源:由無界AI生成
在 OpenAI 發布會的前一天,來自中國的大模型公司零一萬物,讓開源大模型社區活躍了起來:Yi 大模型家族新成員「Yi-1.5」模型正式開源。
在項目主頁可以看到,Yi-1.5 包括一系列預訓練和微調模型,分為 6B、9B、34B 三個版本,採用 Apache 2.0 許可證。

- GitHub 地址:https://github.com/01-ai/Yi-1.5
- Hugging Face 模型下載地址:https://huggingface.co/01-ai
據了解,Yi-1.5 是 Yi-1.0 的持續預訓練版本,使用 500B 個 token 來提高編碼、推理和指令執行能力,並在 300 萬個指令調優樣本上進行了精細調整。
剛一發布,就已經有開發者躍躍欲試:
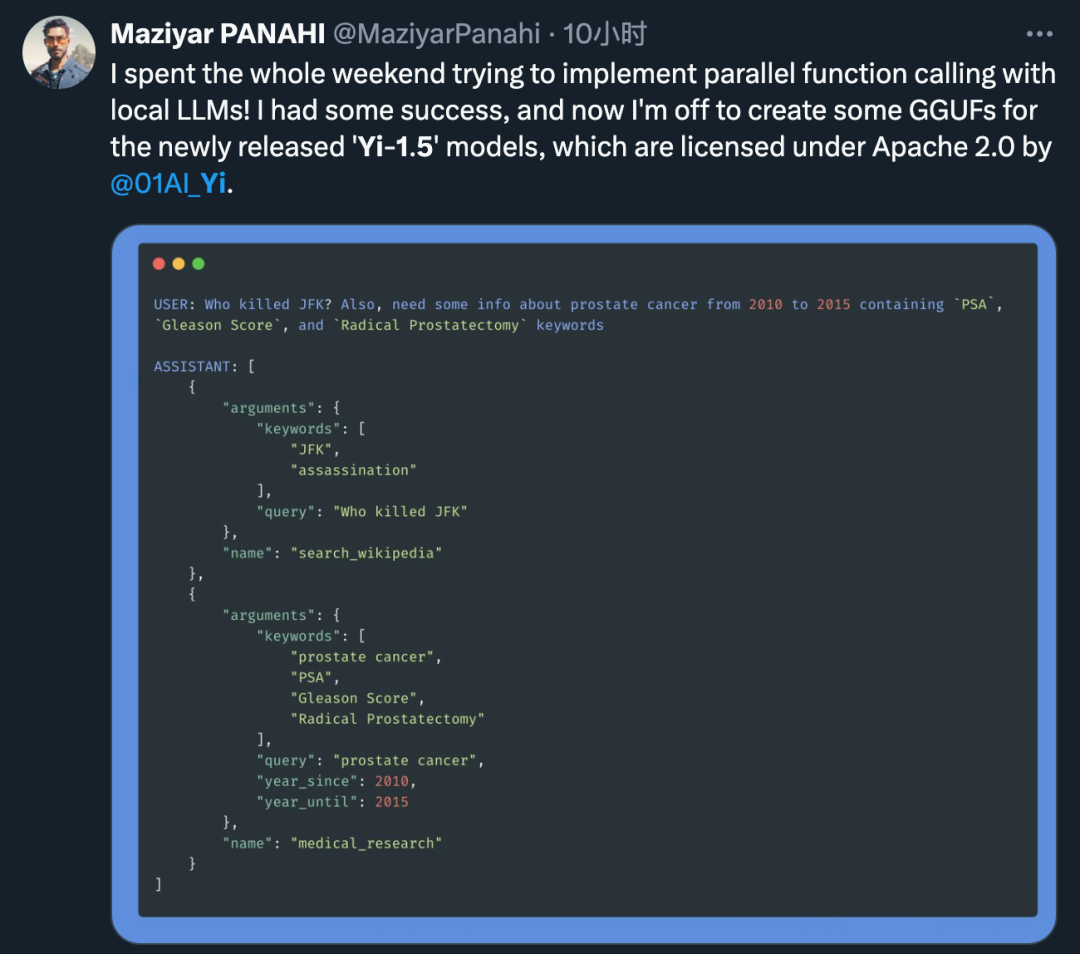
並收穫了好評:
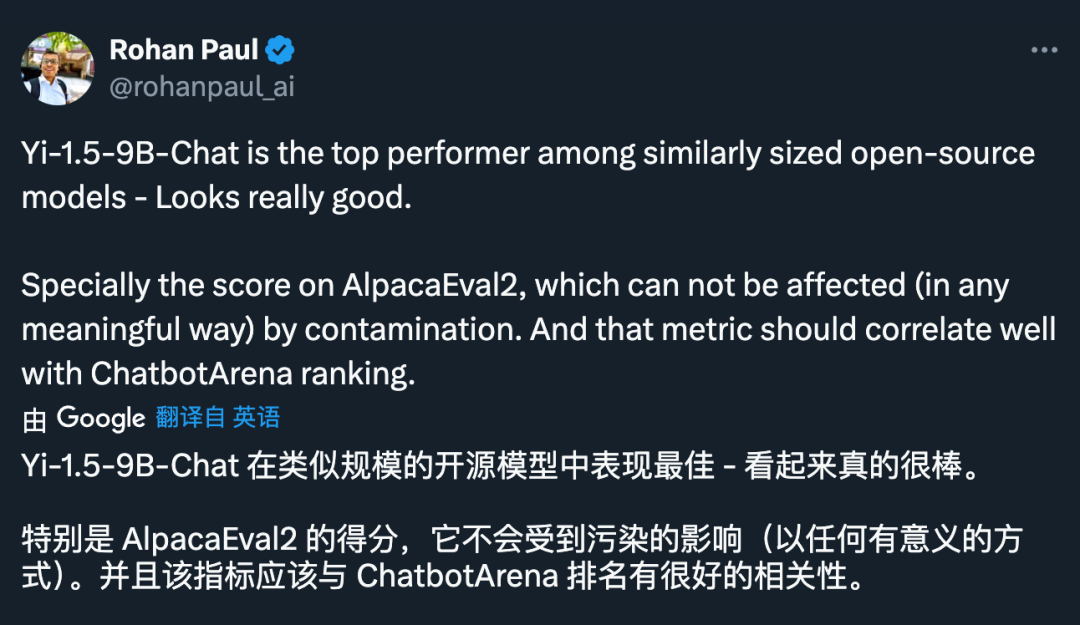
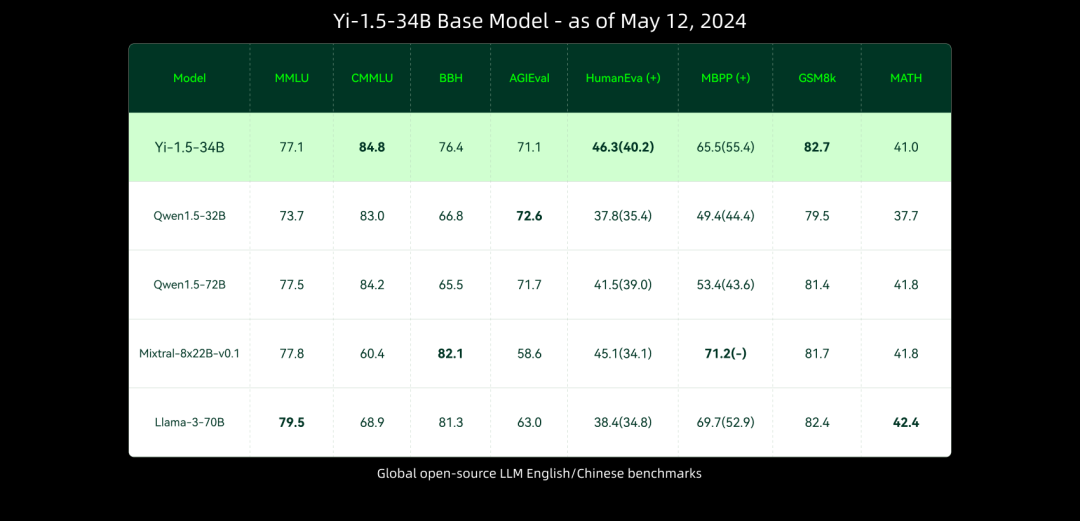
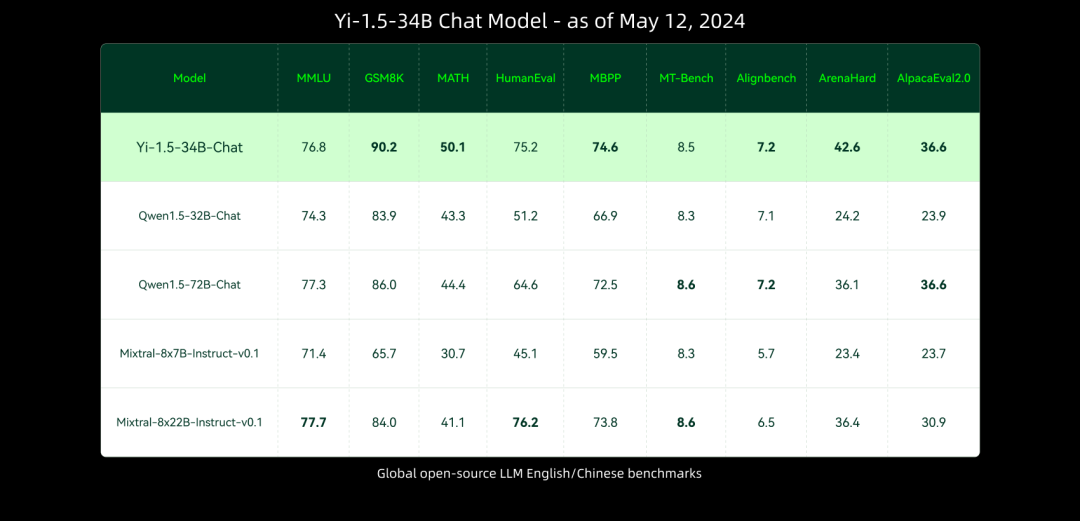
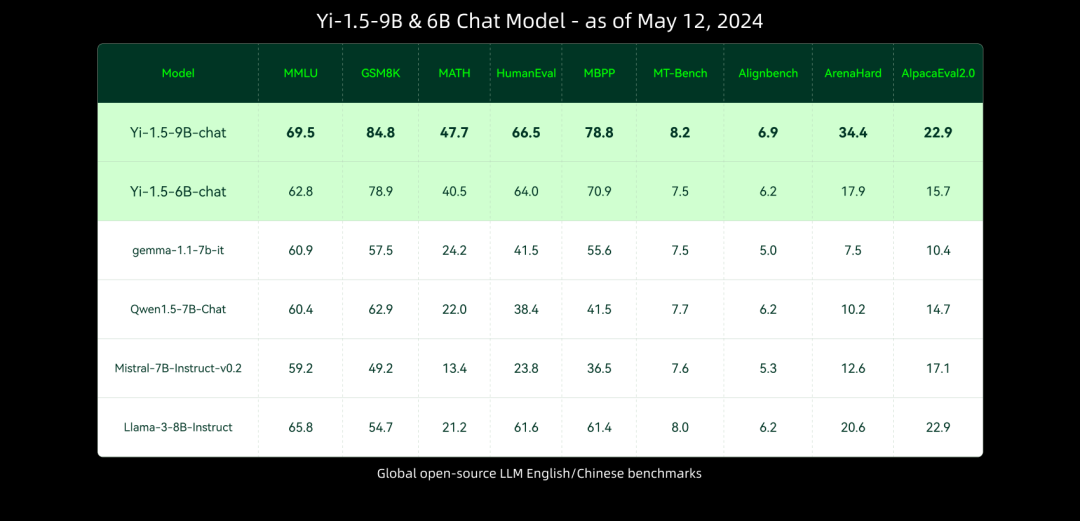
與前序模型相比,Yi-1.5 系列模型進一步提升了編碼、數學、推理和指令遵循能力。從下方多個基準測試結果可以看出,Yi-1.5 34B 型號的一些指標超過了 Qwen 的 72B,幾乎與 Meta Llama 3 的 70B 相當。6B 和 9B 型號也成功超越了 Mistral 的 7B v0.2 版和 Gemma 的 7B 型號。

重磅消息當然不止這一個。
在成立一周年之際,零一萬物宣布面向國內市場一次性發布了包含 Yi-Large、Yi-Large-Turbo、Yi-Medium、Yi-Medium-200K、Yi-Vision、Yi-Spark 等多款模型 API 接口,保證客戶能夠在不同場景下都能找到最佳性能、最具性價比的方案,Yi API Platform 英文站同步對全球開發者開放試用申請。

Yi 大模型 API 開放平台 (https://platform.lingyiwanwu.com/)
其中,千億參數規模的 Yi-Large API 具備超強文本生成及推理性能,適用於複雜推理、預測,深度內容創作等場景,每百萬 token 的價格是 20 元,是 GPT-4-turbo 的三分之一。
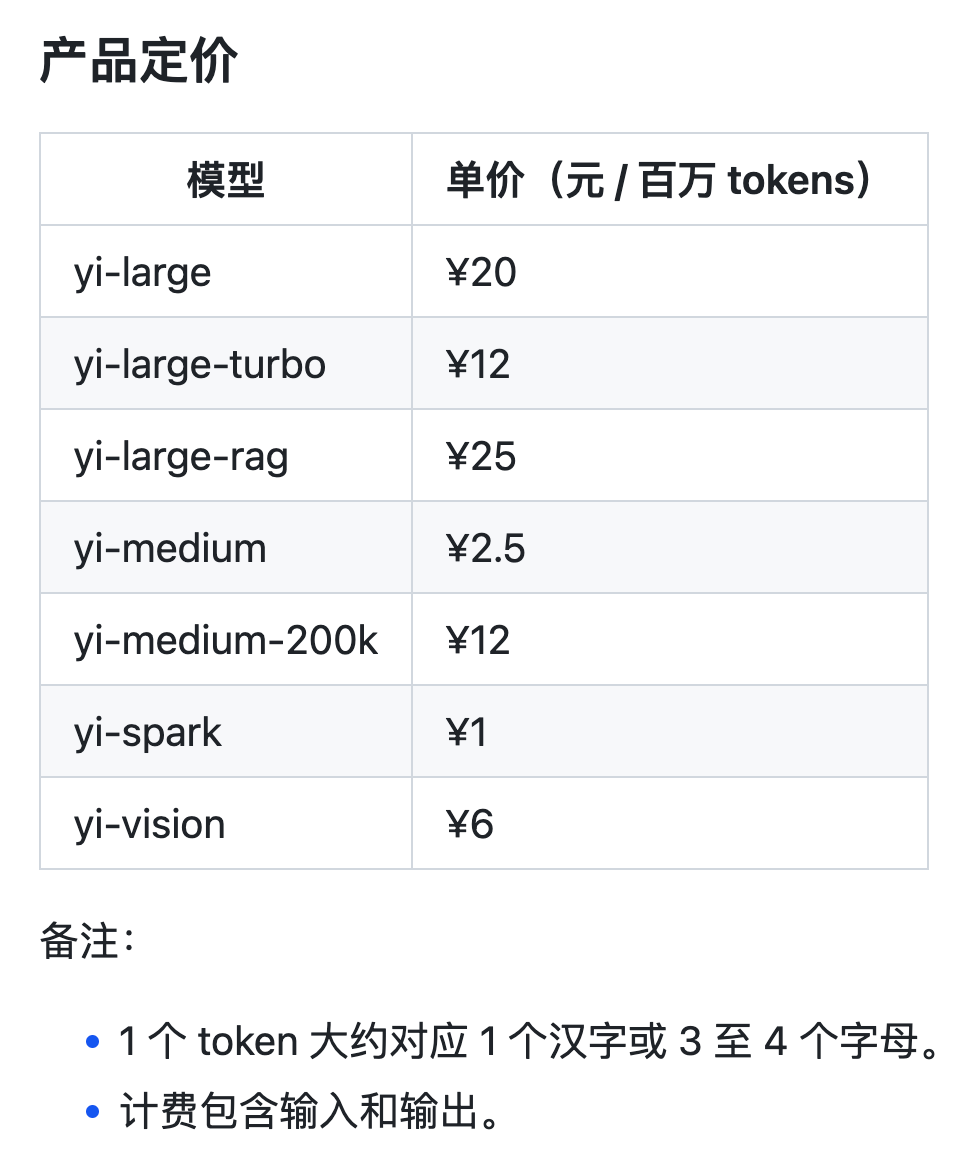
Yi-Large-Turbo API 則根據性能和推理速度、成本,進行了平衡性高精度調優,適用於全場景、高品質的推理及文本生成等場景。Yi-Medium API 優勢在於指令遵循能力,適用於常規場景下的聊天、對話、翻譯等場景;如果需要超長內容文檔相關應用,也可以選用 Yi-Medium-200K API,一次性解讀 20 萬字不在話下;Yi-Vision API 具備高性能圖片理解、分析能力,可服務基於圖片的聊天、分析等場景;Yi-Spark API 則聚焦輕量化極速響應,適用於輕量化數學分析、代碼生成、文本聊天等場景。
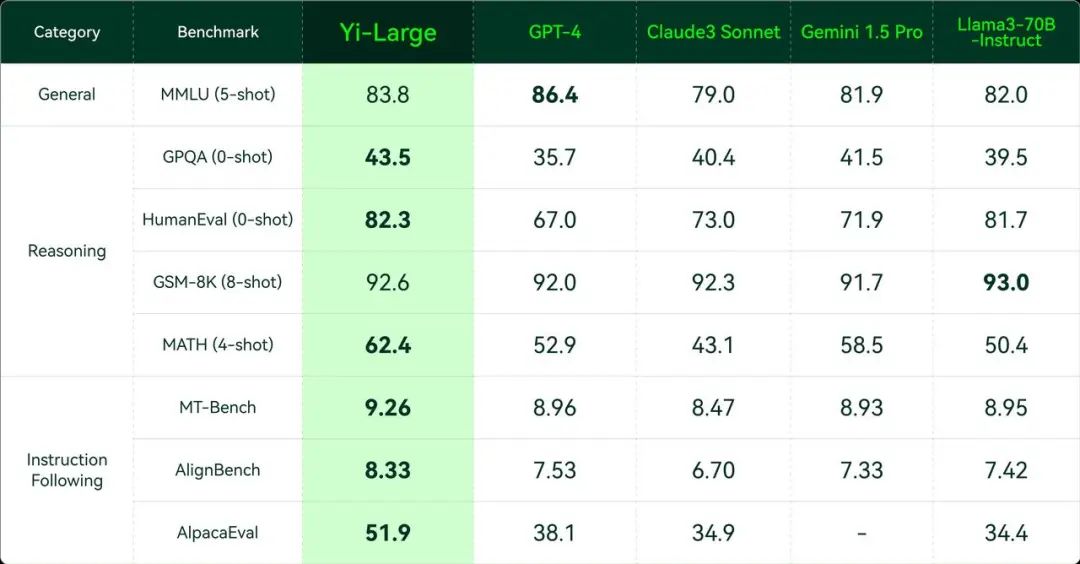
其中特別要提到的是發布會現場正式亮相的千億參數 Yi-Large 閉源大模型。Yi-Large 面世的同時即正式進軍全球 SOTA 頂級大模型之首。可以看到,與 GPT-4、Claude3 Sonnet、Gemini 1.5 Pro 以及 Llama 3-70B-Instruct 等當前頂級模型的較量中,Yi-Large 在絕大多數情況下取得了優勢。
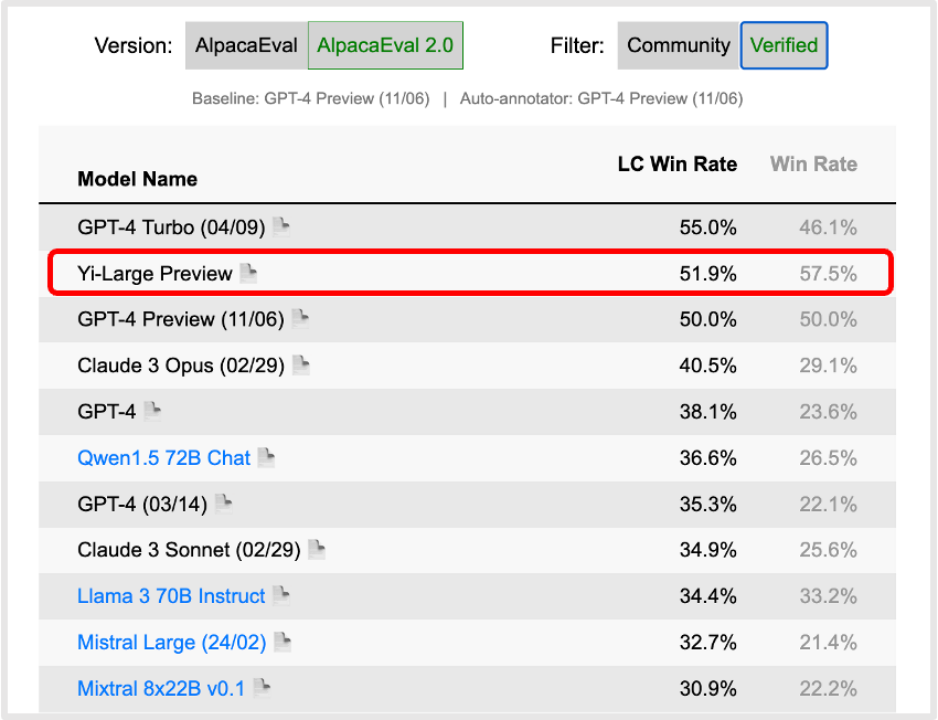
同時,在斯坦福大模型排行榜 AlpacaEval 的英語評測中,Yi-Large 達到全球大模型 Win Rate 第一。在中文通用大模型綜合性基準 SuperCLUE 的中文語言理解排名中,Yi-Large 一躍成為國產大模型 No. 1。
中文能力方面,SuperCLUE 更新的四月基準表現中,Yi-Large 也位列國產大模型之首,Yi-Large 的綜合中英雙語能力皆展現了卓越的性能。
在發布會上,李開復還宣布,零一萬物已啟動下一代 Yi-XLarge MoE 模型訓練,將衝擊 GPT-5 的性能與創新性。從 MMLU、GPQA、HumanEval、MATH 等權威評測集中,仍在初期訓練中的 Yi-XLarge MoE 已經與 Claude-3-Opus、GPT4-0409 等國際廠商的最新旗艦模型互有勝負。
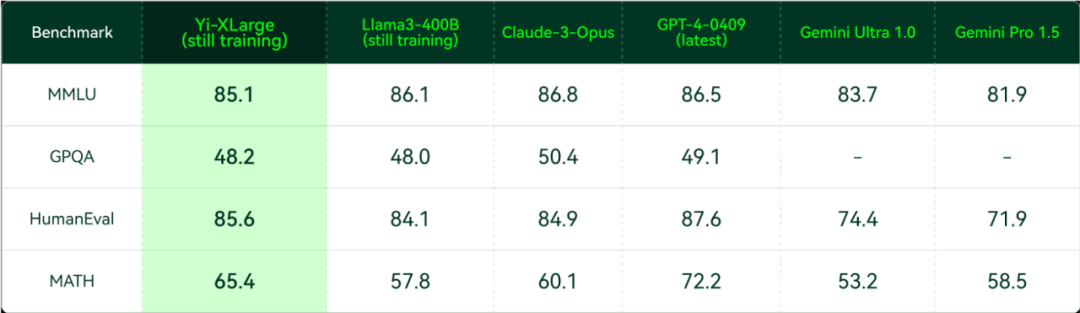
Yi-XLarge 初期訓練中評測(2024 年 5 月 12 日)。
至此,零一萬物已經建立了「雙軌模型策略」。

近期上線的一站式 AI 工作站「萬知」(wanzhi.com/ 微信小程序「萬知 AI」)則是零一萬物基於世界領先的閉源模型 Yi-Large 所做出的「模應一體」生產力應用。
而對於大眾和行業最關心的「大模型落地如何產生價值」的命題,李開復指出,國內大模型賽道的競跑從狂奔到長跑,終局發展將取決於各個选手如何有效達到「TC-PMF」(Product-Market-Technology-Cost Fit,技術成本 X 產品市場契合度)。大模型從訓練到服務都很昂貴,算力緊缺是賽道的集體挑戰,行業應當共同避免陷入不理性的 ofo 式流血燒錢打法,讓大模型能夠用健康良性的 ROI 蓄能長跑。
在李開復博士看來,自研 AI Infra 是零一萬物必然要走的路,零一萬物也自成立起便將 AI Infra 設立為重要方向,着力於實現計算效率的優化。AI Infra(AI Infrastructure 人工智能基礎架構技術)主要涵蓋大模型訓練和部署提供各種底層技術設施。這也基於一個既定事實,很多大模型公司沒有美國大廠的 GPU 數量,因此要採取更務實的戰術和戰略。
零一萬物着力於實現計算效率的優化,經過多方面優化后,零一萬物千億參數模型的訓練成本同比降幅達一倍之多。