所有語言











分享
卷價格的風還是吹到了AI大模型
巴比特_AI领航员345天前
文章來源:硬AI
AI“快進”到價格戰階段?從Deepseek-V2定價看大模型降本新風向

圖片來源:由無界AI生成
卷價格的風還是吹到了AI大模型。
近日,大模型DeepSeek-V2將每百萬tokens輸入/輸出價格分別卷至1/2元,遠低於行業平均水平。
對此,華福證券發布報告稱,大模型成本優化與算力需求並不是直接的此長彼消,而是互相搭台、相互成就。定價的持續走低有望帶來更快的商業化落地,進而會衍生出更多的微調及推理等需求,將逐步盤活國內AI應用及國產算力發展。
DeepSeek-V2是知名私募巨頭幻方量化旗下AI公司深度求索(DeepSeek)發布的全新第二代MoE大模型。
華爾街見聞此前文章提到,DeepSeek-V2擁有2360億參數,其中每個token210億個活躍參數,相對較少,但仍然達到了開源模型中頂級的性能。
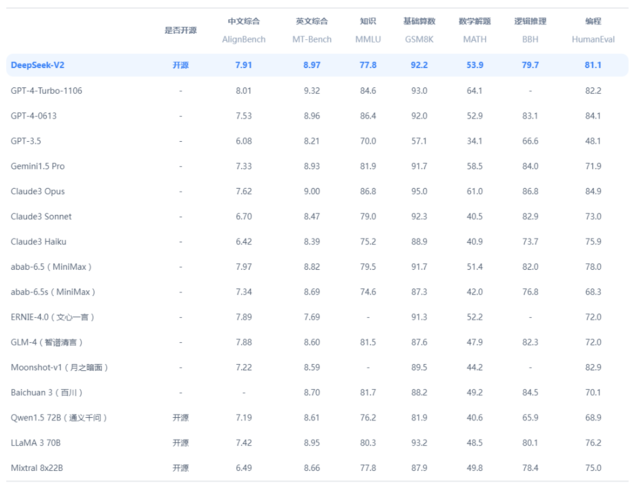
華福證券則在報告中寫道,從綜合性能方面來看,DeepSeek-V2位列第一梯隊。在AlignBench、MT-Bench、MMLU等多個benchmark上表現出色,其中AlignBench在開源模型中居首位,與GPT-4-Turbo,文心4.0比肩。MTBench超過最強MoE開源模型Mixtral 8x22B。
01
DeepSeek-V2定價將至冰點
大模型價格戰拉開序幕
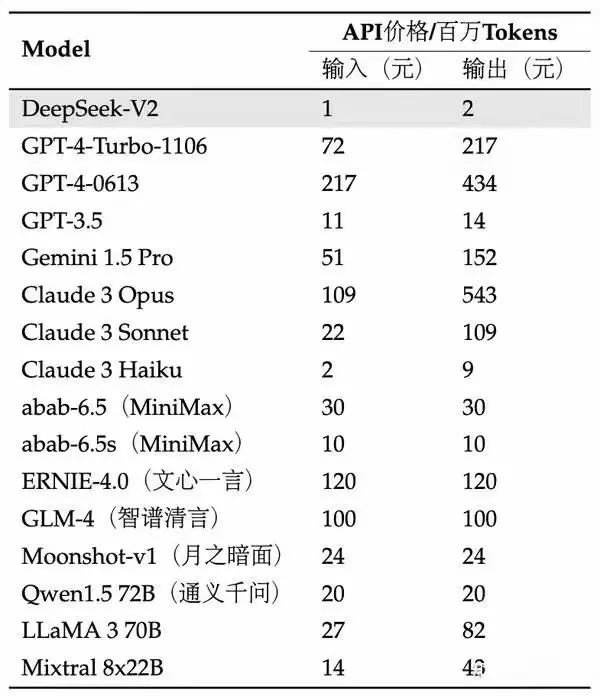
DeepSeek-V2(32k)每百萬tokens輸入/輸出價格分別為1/2元,而GPT-4-Turbo-1106分別為72/217元,DeepSeek-V2性價比顯著。
相對於Claude 3 Haiku,DeepSeek-V2每百萬tokens輸入/輸出價格也僅為其50%/22.2%。除此之外,同為32k上下文版本的moonshot-v1、SenseChat-32K、Qwen1.5 72B每百萬tokens輸入/輸出價格分別為24/24、36/36、20/20元。
DeepSeek表示,採用8xH800 GPU的單節點峰值吞吐量可達到每秒50000多個解碼token。如果僅按輸出token的API的報價計算,每個節點每小時的收入就是50.4美元,假設利用率完全充分,按照一個8xH800節點的成本為每小時15美元來計算,DeepSeek每台服務器每小時的收益可達35.4美元,甚至能實現70%以上的毛利率。
有分析人士指出,即使服務器利用率不充分、批處理速度低於峰值能力,DeepSeek也有足夠的盈利空間,同時顛覆其他大模型的商業邏輯。
華福證券也認為,此次DeepSeek-V2定價發布有望掀起新一輪大模型價格戰,api定價有望持續走低。
02
大模型定價下降的背後離不開成本的優化
價格是怎麼被打下去的?來自DeepSeek-V2的全新架構。
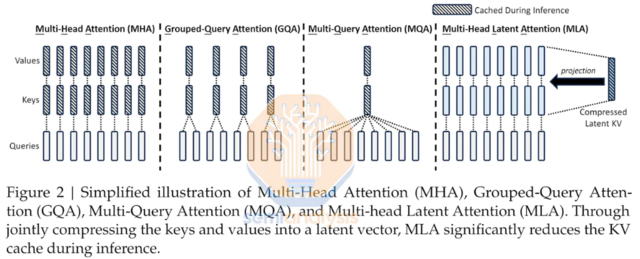
據悉,DeepSeek-V2採用Transformer架構,其中每個Transformer塊由一個注意力模塊和一個前饋網絡(FFN)組成,並且在注意力機制和FFN方面,研究團隊設計並採用了創新架構。
華福證券指出,目前眾多大模型已經通過多種方式降低成本。
從模型壓縮的方向看,可以通過量化的形式將浮點表徵為低位寬模型來壓縮模型存儲空間,加速模型推理;從模型架構的方向看,MoE架構由於其內部的專家模型能夠分配到不同設備,並可以執行并行計算,其計算效率較稠密模型顯著提升,進而帶來更低的成本。
從tokens量的方向來看,可以通過prompt壓縮等方式直接降低輸入端tokens,進而降低成本。除此之外,多種新的方案已出現在相關論文中,未來多種成本優化方案的融合將進一步加速模型成本的下降。
本文主要觀點來自華福證券錢勁宇(執業證書編號:S0210524040006)5月9日發布的報告《計算機行業跟蹤:從 Deepseek-V2 定價看大模型降本新風向》