所有語言











分享
蘋果開源OpenELM,大模型開源領域再迎一巨頭!
文章來源:AIGC開放社區

4月24日,蘋果開源了大語言模型OpenELM。這與微軟剛開源的Phi-3 Mini類似,是一款專門針對手機等移動設備的模型。
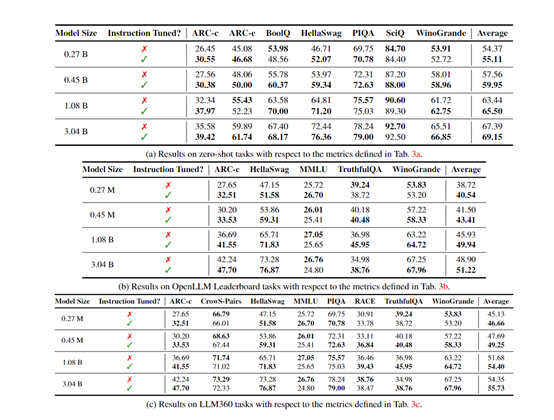
OpenELM有指令微調和預訓練兩種模型,一共有2.7億、4.5億、11億和30億4種參數,提供生成文本、代碼、翻譯、總結摘要等功能。
雖然最小的參數只有2.7億,但蘋果使用了1.8萬億tokens的數據進行了預訓練,這也是其能以小參數表現出超強性能的主要原因之一。
值得一提的是,蘋果還把訓練OpenELM模型的深度神經網絡庫CoreNet也開源了,僅1天多的時間Github就超過1100顆星。蘋果的MobileOne、CVNets、MobileViT、FastVit等知名研究都是基於CoreNet完成的。
開源地址:https://huggingface.co/collections/apple/openelm-instruct-models-6619ad295d7ae9f868b759ca?ref=maginative.com
CoreNet地址:https://github.com/apple/corenet?ref=maginative.com
論文地址:https://arxiv.org/abs/2404.14619

目前,大模型領域主要分為開源和閉源兩大陣營,國內外知名閉源的代表企業有OpenAI、Anthropic、谷歌、Midjourney、Udio、百度、科大訊飛、出門問問、月之暗面等。
開源陣營有Meta、微軟、谷歌、百川智能、阿里巴巴、零一萬物等。蘋果作為手機閉源領域的領導者,本次卻罕見地加入開源大模型陣營,可能在效仿谷歌的方式先通過開源拉攏用戶,再用閉源產品去實現商業化營利。
不管咋說,蘋果選擇開源對於開發者、中小企業來說都是一個不錯的福利。因為,與以往只提供模型權重和推理代碼的做法不同,蘋果發布了完整的訓練、評估框架等。
主要內容包括數據準備、模型訓練、微調以及評估流程,同時提供了多個預訓練檢查點和訓練日誌,可以讓我們深度了解全球頂級科技公司的技術思想和開發流程。
OpenELM架構簡單介紹
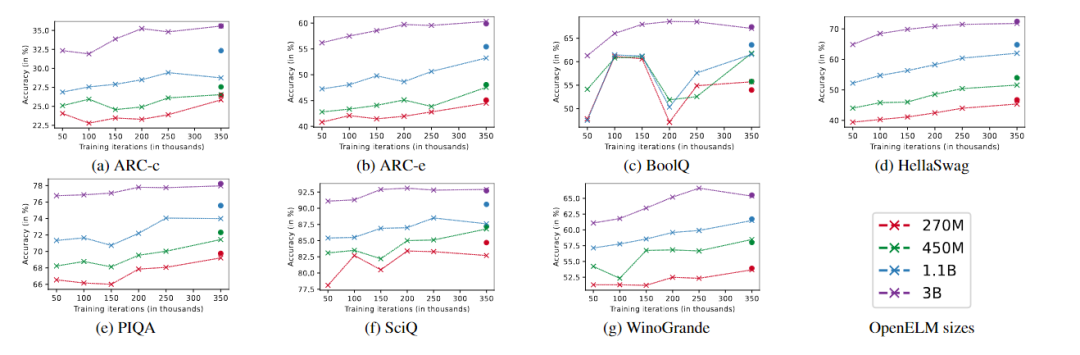
OpenELM採用了無編碼器的transformer架構,並在多個方面進行了技術創新。OpenELM的使用了一種“層級縮放”策略,使得模型能夠跨各個轉換器層更有效地分配參數,能以最少的訓練數據取得了更好的性能,同時極大提升準確率。
例如,11億參數的OpenELM,比12億參數的OLMo模型的準確率高出2.36%,而使用的預訓練數據卻只有OLMo的一半。
此外,OpenELM不使用任何全連接層中的可學習偏置參數,採用RMSNorm進行預歸一化,並使用旋轉位置嵌入編碼位置信息。
OpenELM還通過分組查詢注意力代替多頭注意力,用SwiGLU FFN替換了傳統的前饋網絡,並使用了Flash注意力來計算縮放點積注意力,能以更少的資源來進行訓練和推理。
訓練流程與數據集
在訓練流程中,蘋果採用了CoreNet作為訓練框架,並使用了Adam優化算法進行了35萬次迭代訓練。
蘋果使用了批量大小為4096的小批量隨機梯度下降進行模型參數更新,並設置了適當的學習率和權重衰減。
預訓練數據集方面,OpenELM使用了包括RefinedWeb、去重的PILE、RedPajama的子集和Dolma v1.6的子集在內的公共數據集,一共約1.8萬億tokens數據。
此外,蘋果使用了動態分詞和數據過濾的方法,實現了實時過濾和分詞,從而簡化了實驗流程並提高了靈活性。還使用了與Meta的Llama相同的分詞器,以確保實驗的一致性。
這次蘋果真的是很有誠意的開源,一開到底所有內容都貢獻出來了,家大業大就是敢玩。這也表明蘋果進軍大模型領域的決心,以後開源領域更熱鬧啦~
本文素材來源OpenELM論文,如有侵權請聯繫刪除
END