所有語言











分享
馬斯克開源Grok-1:3140億參數迄今最大,權重架構全開放,磁力下載
巴比特_机器之心398天前
文章來源:機器之心
開源社區有福了。

圖片來源:由無界AI生成
說到做到,馬斯克承諾的開源版大模型 Grok 終於來了!
今天凌晨,馬斯克旗下大模型公司 xAI 宣布正式開源 3140 億參數的混合專家(MoE)模型「Grok-1」,以及該模型的權重和網絡架構。
這也使得Grok-1成為當前參數量最大的開源大語言模型。

封面圖根據 Grok 提示使用 Midjourney 生成的:神經網絡的 3D 插圖,具有透明節點和發光連接,以不同粗細和顏色的連接線展示不同的權重。
這個時候,馬斯克當然不會忘了嘲諷 OpenAI 一番,「我們想了解更多 OpenAI 的開放部分」。
回到模型本身,Grok-1 從頭開始訓練,並且沒有針對任何特定應用(如對話)進行微調。相對的,在 X(原 Twitter)上可用的 Grok 大模型是微調過的版本,其行為和原始權重版本並不相同。
Grok-1 的模型細節包括如下:
- 基礎模型基於大量文本數據進行訓練,沒有針對任何具體任務進行微調;
- 3140 億參數的 MoE 模型,在給定 token 上的激活權重為 25%;
- 2023 年 10 月,xAI 使用 JAX 庫和 Rust 語言組成的自定義訓練堆棧從頭開始訓練。
xAI 遵守 Apache 2.0 許可證來開源 Grok-1 的權重和架構。Apache 2.0 許可證允許用戶自由地使用、修改和分發軟件,無論是個人還是商業用途。項目發布短短四個小時,已經攬獲 3.4k 星標,熱度還在持續增加。
項目地址 https://github.com/xai-org/grok-1
該存儲庫包含用於加載和運行 Grok-1 開放權重模型的 JAX 示例代碼。使用之前,用戶需要確保先下載 checkpoint,並將 ckpt-0 目錄放置在 checkpoint 中, 然後,運行下面代碼進行測試:
pip install -r requirements.txt
python run.py項目說明中明確強調,由於 Grok-1 是一個規模較大(314B 參數)的模型,因此需要有足夠 GPU 內存的機器才能使用示例代碼測試模型。此外,該存儲庫中 MoE 層的實現效率並不高,之所以選擇該實現是為了避免需要自定義內核來驗證模型的正確性。
用戶可以使用 Torrent 客戶端和這個磁力鏈接來下載權重文件:
magnet:?xt=urn:btih:5f96d43576e3d386c9ba65b883210a393b68210e&tr=https%3A%2F%2Facademictorrents.com%2Fannounce.php&tr=udp%3A%2F%2Ftracker.coppersurfer.tk%3A6969&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce看到這,有網友開始好奇 314B 參數的 Grok-1 到底需要怎樣的配置才能運行。對此有人給出答案:可能需要一台擁有 628 GB GPU 內存的機器(每個參數 2 字節)。這麼算下來,8xH100(每個 80GB)就可以了。

知名機器學習研究者、《Python 機器學習》暢銷書作者 Sebastian Raschka 評價道:「Grok-1 比其他通常帶有使用限制的開放權重模型更加開源,但是它的開源程度不如 Pythia、Bloom 和 OLMo,後者附帶訓練代碼和可復現的數據集。」
DeepMind 研究工程師 Aleksa Gordié 則預測,Grok-1 的能力應該比 LLaMA-2 要強,但目前尚不清楚有多少數據受到了污染。另外,二者的參數量也不是一個量級。

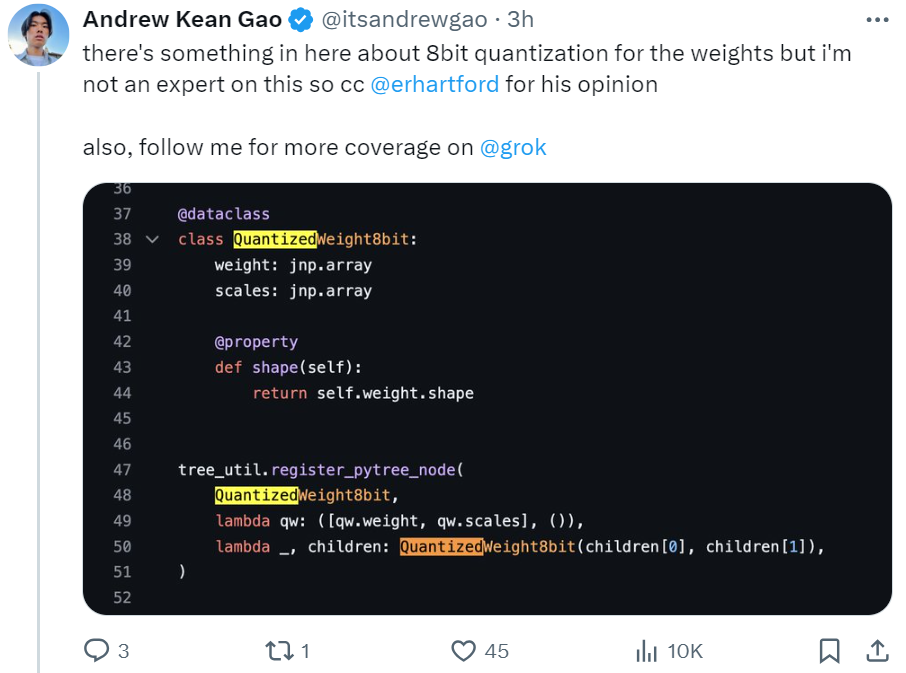
還有一位推特用戶 @itsandrewgao 詳細分析了 Grok-1 的架構細節,並做出了一下幾點總結。

首先 Grok-1 是 8 個專家的混合(2個活躍)、860億激活參數(比Llama-2 70B還多),使用旋轉嵌入而非固定位置嵌入。
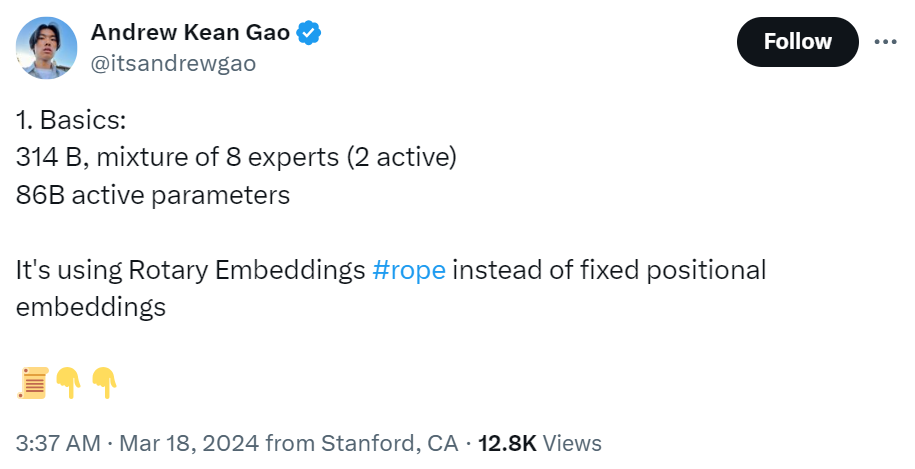
tokenizer 詞彙大小為 131,072(類似於 GPT-4)2^17,嵌入大小 6,144 (48*128),64 個 transformer 層(sheesh), 每層都有一個解碼器層:多頭注意力塊和密集塊,鍵值大小 128。
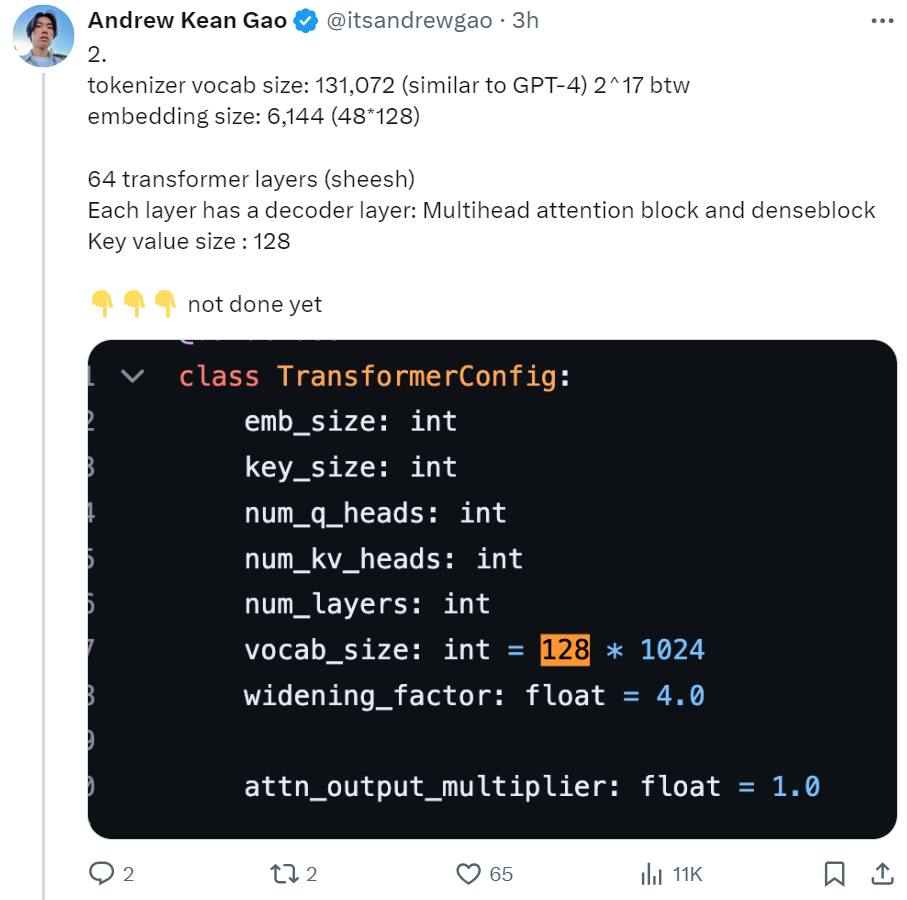
多頭注意力塊:48 個 head 用於查詢,8 個用於鍵 / 值(KV)。KV 大小為 128。密集塊(密集前饋塊):加寬因子 8,隱藏層大小 32768。每個 token 從 8 個專家中選擇 2 個。
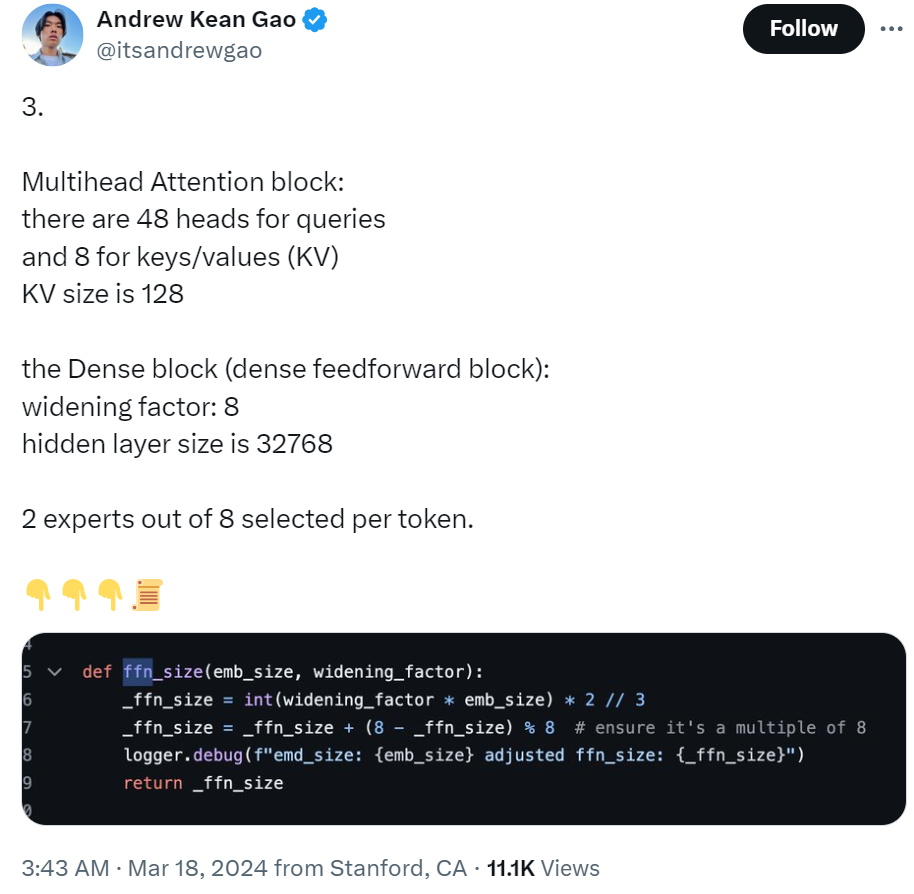
旋轉位置嵌入大小為 6144,與輸入嵌入大小相同。上下文長度為 8192 tokens,精度為 bf16。
此外還提供了一些權重的 8bit 量化內容。
當然,我們還是希望 xAI 官方能夠儘快公布 Grok-1 的更多模型細節。
Grok-1 是個什麼模型?能力如何?
Grok 是馬斯克 xAI 團隊去年 11 月推出的一款大型語言模型。在去年 11 月的官宣博客中(參見《馬斯克 xAI 公布大模型詳細進展,Grok 只訓練了 2 個月》), xAI 寫道:
Grok 是一款仿照《銀河系漫遊指南》設計的 AI,可以回答幾乎任何問題,更難能可貴的是,它甚至可以建議你問什麼問題!
Grok 在回答問題時略帶詼諧和叛逆,因此如果你討厭幽默,請不要使用它!
Grok 的一個獨特而基本的優勢是,它可以通過 X 平台實時了解世界。它還能回答被大多數其他 AI 系統拒絕的辛辣問題。
Grok 仍然是一個非常早期的測試版產品 —— 這是我們通過兩個月的訓練能夠達到的最佳效果 —— 因此,希望在您的幫助下,它能在測試中迅速改進。
xAI 表示,Grok-1 的研發經歷了四個月。在此期間,Grok-1 經歷了多次迭代。
在公布了 xAI 創立的消息之後,他們訓練了一個 330 億參數的 LLM 原型 ——Grok-0。這個早期模型在標準 LM 測試基準上接近 LLaMA 2 (70B) 的能力,但只使用了一半的訓練資源。之後,他們對模型的推理和編碼能力進行了重大改進,最終開發出了 Grok-1,這是一款功能更為強大的 SOTA 語言模型,在 HumanEval 編碼任務中達到了 63.2% 的成績,在 MMLU 中達到了 73%。
xAI 使用了一些旨在衡量數學和推理能力的標準機器學習基準對 Grok-1 進行了一系列評估:
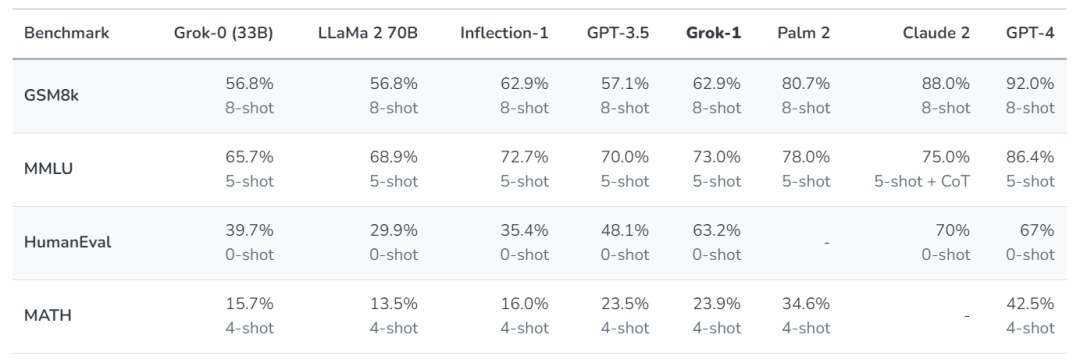
在這些基準測試中,Grok-1 显示出了強勁的性能,超過了其計算類中的所有其他模型,包括 ChatGPT-3.5 和 Inflection-1。只有像 GPT-4 這樣使用大量訓練數據和計算資源訓練的模型才能超越它。xAI 表示,這展示了他們在高效訓練 LLM 方面取得的快速進展。
不過,xAI 也表示,由於這些基準可以在網上找到,他們不能排除模型無意中在這些數據上進行了訓練。因此,他們在收集完數據集之後,根據去年 5 月底(數據截止日期之後)公布的 2023 年匈牙利全國高中數學期末考試題,對他們的模型(以及 Claude-2 和 GPT-4 模型)進行了人工評分。結果,Grok 以 C 級(59%)通過考試,Claude-2 也取得了類似的成績(55%),而 GPT-4 則以 68% 的成績獲得了 B 級。xAI 表示,他們沒有為應對這個考試而特別準備或調整模型。

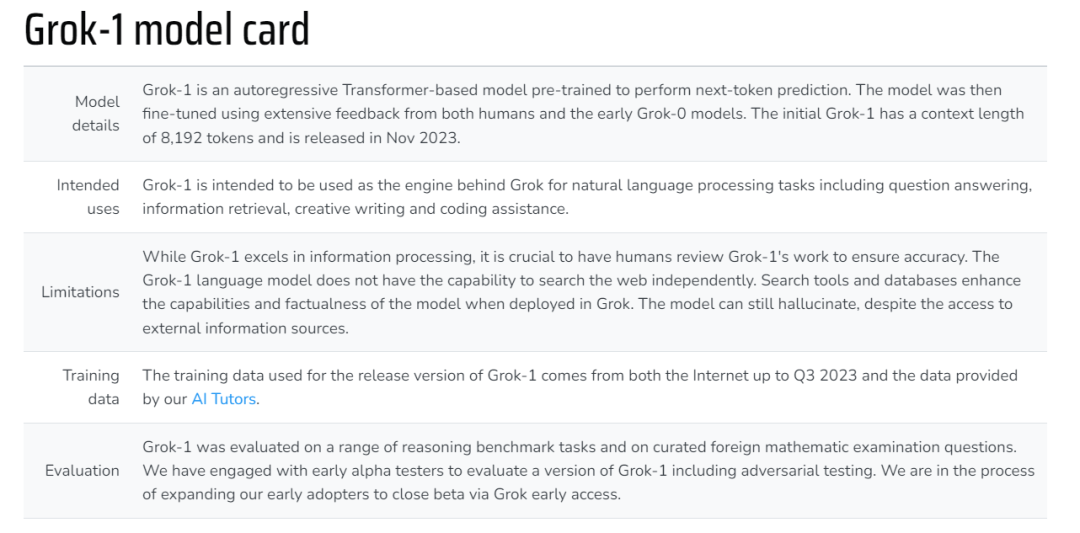
下面這個表格展示了 Grok-1 的更多信息(來自 2023 年 11 月的博客,部分信息可能存在更新):
- 模型細節:Grok-1 是一個基於 Transformer 的自回歸模型。xAI 利用來自人類和早期 Grok-0 模型的大量反饋對模型進行了微調。初始的 Grok-1 能夠處理 8192 個 token 的上下文長度。模型於 2023 年 11 月發布。
- 預期用途:Grok-1 將作為 Grok 背後的引擎,用於自然語言處理任務,包括問答、信息檢索、創意寫作和編碼輔助。
- 局限性:雖然 Grok-1 在信息處理方面表現出色,但讓人類檢查 Grok-1 的工作以確保準確性至關重要。Grok-1 語言模型不具備獨立搜索網絡的能力。在 Grok 中部署搜索工具和數據庫可以增強模型的能力和真實性。儘管可以訪問外部信息源,但模型仍會產生幻覺。
- 訓練數據:Grok-1 發布版本所使用的訓練數據來自截至 2023 年第三季度的互聯網數據和 xAI 的 AI 訓練師提供的數據。
- 評估:xAI 在一系列推理基準任務和國外數學考試試題中對 Grok-1 進行了評估。他們與早期 alpha 測試者合作,以評估 Grok-1 的一個版本,包括對抗性測試。目前,Grok 已經對一部分早期用戶開啟了封閉測試訪問權限,進一步擴大測試人群。
在博客中,xAI 還公布了 Grok 的構建工程工作和 xAI 大致的研究方向。其中,長上下文的理解與檢索、多模態能力都是未來將會探索的方向之一。
xAI 表示,他們打造 Grok 的願景是,希望創造一些 AI 工具,幫助人類尋求理解和知識。
具體來說,他們希望達到以下目標:
- 收集反饋,確保他們打造的 AI 工具能夠最大限度地造福全人類。他們認為,設計出對有各種背景和政治觀點的人都有用的 AI 工具非常重要。他們還希望在遵守法律的前提下,通過他們的 AI 工具增強用戶的能力。Grok 的目標是探索並公開展示這種方法;
- 增強研究和創新能力:他們希望 Grok 成為所有人的強大研究助手,幫助他們快速獲取相關信息、處理數據並提出新想法。
他們的最終目標是讓他們的 AI 工具幫助人們尋求理解。
在 X 平台上,Grok-1 的開源已經引發了不少討論。值得注意的是,技術社區指出,該模型在前饋層中使用了 GeGLU,並採用了有趣的 sandwich norm 技術進行歸一化。甚至 OpenAI 的員工也發帖表示對該模型很感興趣。

不過,開源版 Grok 目前還有些事情做不到,比如「通過 X 平台實時了解世界」,實現這一功能目前仍需要訂閱部署在 X 平台上的付費版本。
鑒於馬斯克對開源的积極態度,有些技術人員已經在期待後續版本的開源了。