所有語言











分享
iPhone動嘴10秒P圖!UCSB蘋果全華人團隊發布多模態MGIE,官宣開源人人可玩
巴比特_AIcore439天前
文章來源:新智元

圖片來源:由無界AI生成
幾天前,庫克在蘋果電話會上證實,「今年晚些時候會發布生成式AI」。
ChatGPT掀起全球熱潮之後,蘋果也在悄悄發力AI,曾曝出的大模型框架Ajax、AppleGPT等AI工具讓業界充滿了期待。
6月舉辦的WWDC上,這家曾霸佔全球市值第一公司,將會宣布各種AI能力整合到iOS 18、iPadOS 18等軟件產品中。
而在此之前,你在iPhone可以搶先用上AI超能力了!
隨意拍攝一張餐桌圖,然後說一句「在餐桌上添加一份披薩」。披薩瞬間就出現在桌子上了。

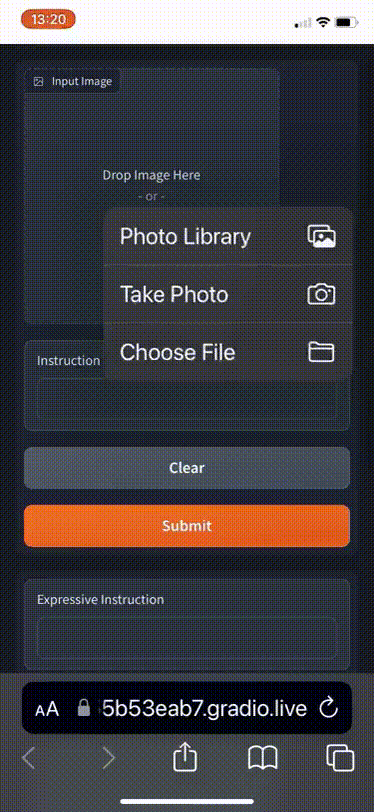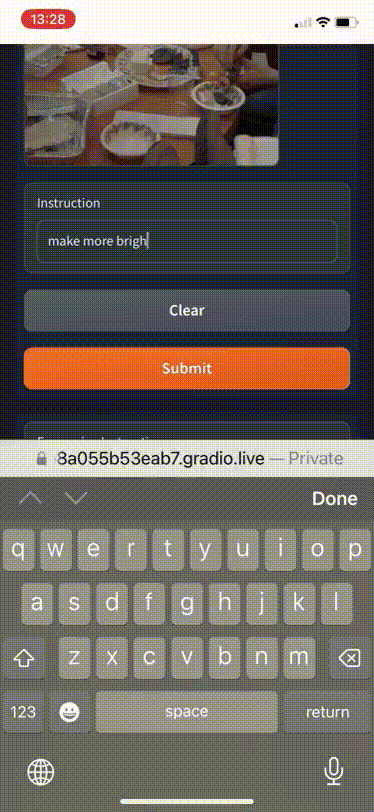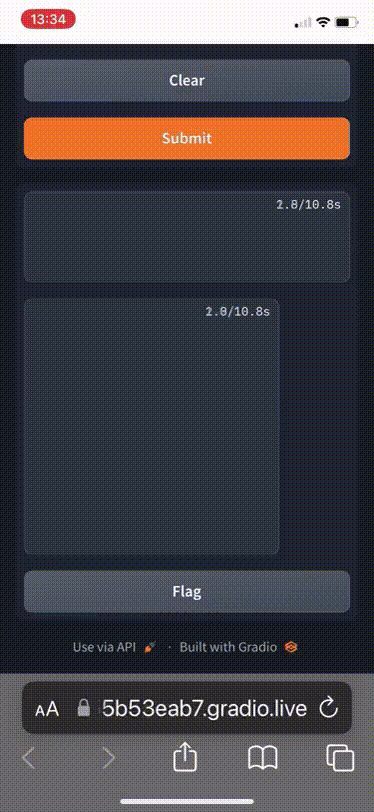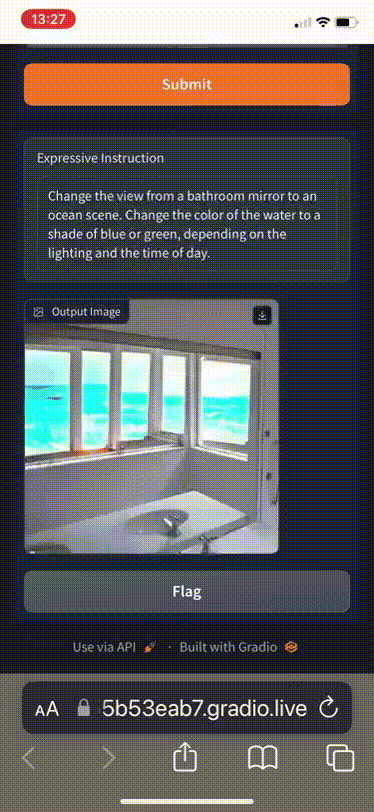
此外,你還可以隨意選一張圖,可以讓圖片中哭臉變成笑臉、照片提亮、移除背景人物,甚至可以將綠植景色更換成海洋。
這些魔法實現,只需你動動嘴,立刻完成P圖。
這項神奇的技術背後是由一個基於自然語言修改圖片的新模型——MGIE加持,由UCSB和蘋果全華人團隊共同完成。
具體就是,通過多模態模型,去引導圖像進行編輯。

論文地址:https://arxiv.org/pdf/2309.17102.pdf
從上面例子中看的出,MGIE最大的特點便是,用簡短的話,就能實現出色的圖像編輯能力。
目前,這篇論文已被ICLR 2024錄用為spotlight,並且在今天正式開源。
所有人都可以上線試玩。

地址:http://128.111.41.13:7122/
MLLM理解,擴散模型生成
文本引導的圖像編輯,在近來的研究中逐漸得到了普及。
因其對真實圖像進行建模擁有的強大能力,擴散模型也被用於圖像編輯。
大模型在各種語言任務中,包括機器翻譯、文本摘要和問答,展現出強大的能力。LLM通過從大規模語料庫中學習,包含潛在的視覺知識和創造力,可以協助各種視覺和語言任務。
另外,多模態大模型(MLLM)可以自然地將圖片作為輸入,在提供視覺感知響應,以及充當多模態助手展現出強大的能力。
受MLLM的啟發,研究人員將其合併以解決指令引導不足的問題,並引入MLLM引導圖像編輯(MGIE)。
如圖2所示,MGIE由MLLM和擴散模型組成。MLLM學習導出簡潔的表達指令,並提供明確的視覺相關指導。
通過端到端訓練,擴散模型會聯合更新,並利用預期目標的潛在想象力執行圖像編輯。
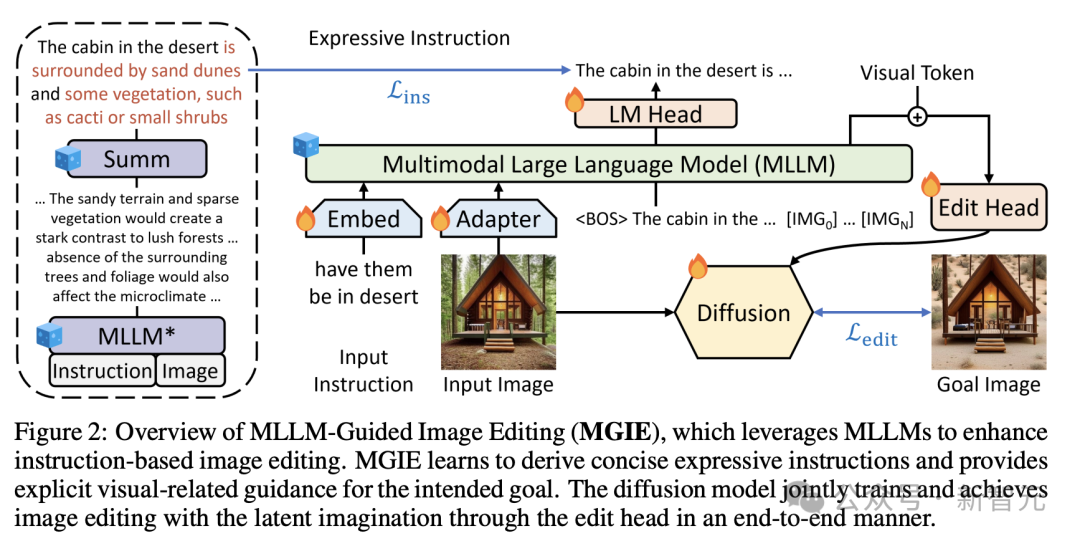
具體來說,通過給定的指令X將輸入圖像V,編輯為目標圖像Ο。為了處理不精確的指令,MGIE包含MLLM並學習導出明確而簡潔的表達指令Σ。
為了橋接語言和視覺的模態,研究人員在Σ之後添加特殊的 [IMG] token,並採用編輯頭T對其進行轉換。
它們將指導擴散模型F實現預期的編輯目標。然後,MGIE能夠通過視覺相關感知來理解模糊命令,以進行合理的圖像編輯。
這樣,MGIE就能從固有的視覺推導中獲益,並解決模糊的人類指令,從而實現合理的編輯。
比如,下圖中在沒有額外的語境情況下,很難捕捉到「健康」的含義。
而MGIE模型可以將「蔬菜配料」與披薩精確地聯繫起來,並按照期望進行相關編輯。

即便用蒙版遮住人臉,MGIE也能準確理解背景中的女人並移除。

照片提亮,也做的很出色。

圖片中,MGIE在具體某塊區域的精準編輯。

實驗結果
為了學習基於指令的圖像編輯,研究中採用了IPr2Pr作為預訓練數據集。
它包含 1M CLIP過濾數據,其中指令由GPT-3提取,圖像由Prompt-to-Prompt合成。
為了進行全面評估,研究人員考慮了編輯的各個方面,包括EVR、GIER、MA5k、MagicBrush,並發現MGIE可進行Photoshop風格的修改、全局照片優化和局部對象修改。
基線
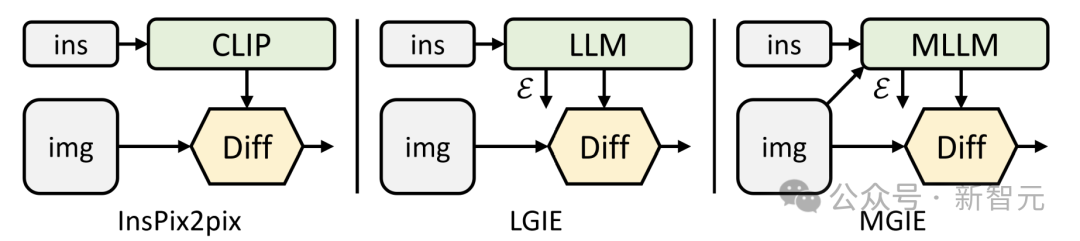
研究人員將InsPix2Pix作為基線,它建立在CLIP文本編碼器上,具有用於基於指令的圖像編輯的擴散模型。
另外,還考慮了類似的LLM引導圖像編輯(LGIE)模型,其中採用LLaMA-7B來表達來自僅指令輸入但沒有視覺感知的表達指令Σ。
實施細節
MLLM 和擴散模型£從LLaVA-7B和 StableDiffusion-v1.5初始化,並共同更新圖像編輯任務。請注意,MLLM中只有詞嵌入和LM head是可訓練的。
按照GILL的方法,研究人員使用N =8個視覺token。編輯頭T是一個4層的Transformer,它將語言特徵轉化為編輯指導。我們採用批大小為128的AdamW來優化 MGIE。
MLLM和£的學習率分別為5e-4和1e-4。所有實驗均在PyTorch中在8個A100 GPU上進行。
定量結果
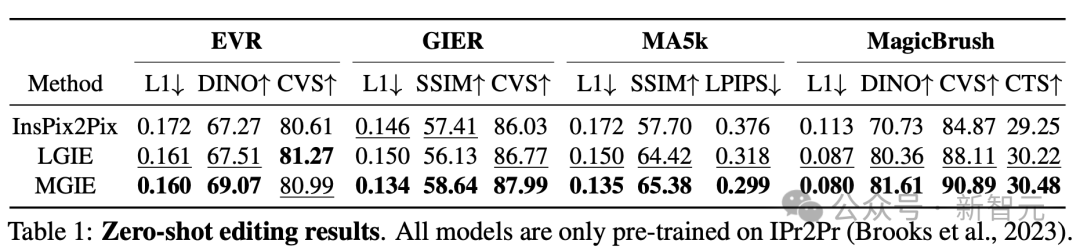
表一显示了零樣本編輯結果,其中模型僅在IPr2Pr上進行訓練。
對於涉及Photoshop風格修改的EVR和GIER,表達性指令可以揭示具體目標,而簡短但模糊的命令去無法讓編輯更接近意圖。
對於MA5k上的全局照片優化,由於相關訓練三元組的稀缺,InsPix2Pix很難處理。
LGIE和MGIE雖然是同一來源的訓練,但可以通過LLM的學習提供詳細的解釋,但LGIE仍然局限於其單一的模式。
通過訪問圖像,MGIE可以得出明確的指令,例如哪些區域應該變亮,或哪些對象更加清晰。
它可以帶來顯著的性能提升,另外在MagicBrush也發現了類似的結果。MGIE也在精確的視覺上獲得了最佳的表現。
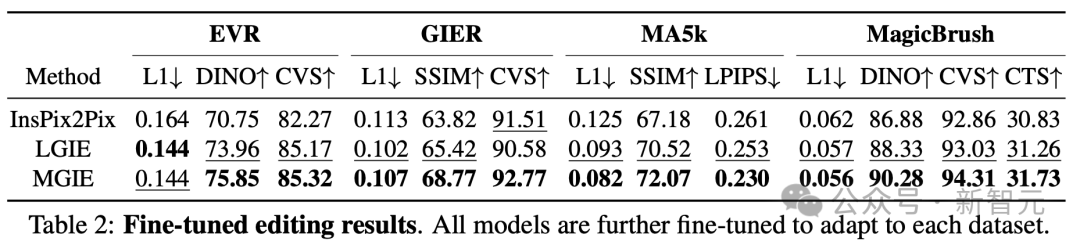
為了研究針對特定目的的基於指令的圖像編輯,表2對每個數據集上的模型進行了微調。
對於EVR和GIER,所有模型在適應Photoshop風格的編輯任務后都獲得了改進。由於微調也使表達指令更加針對特定領域,因此MGIE通過學習領域相關指導來增加最多。
從上面的實驗中,說明了使用表達指令進行學習,可以有效地增強圖像編輯,而視覺感知在獲得最大增強的明確指導方面起着至關重要的作用。
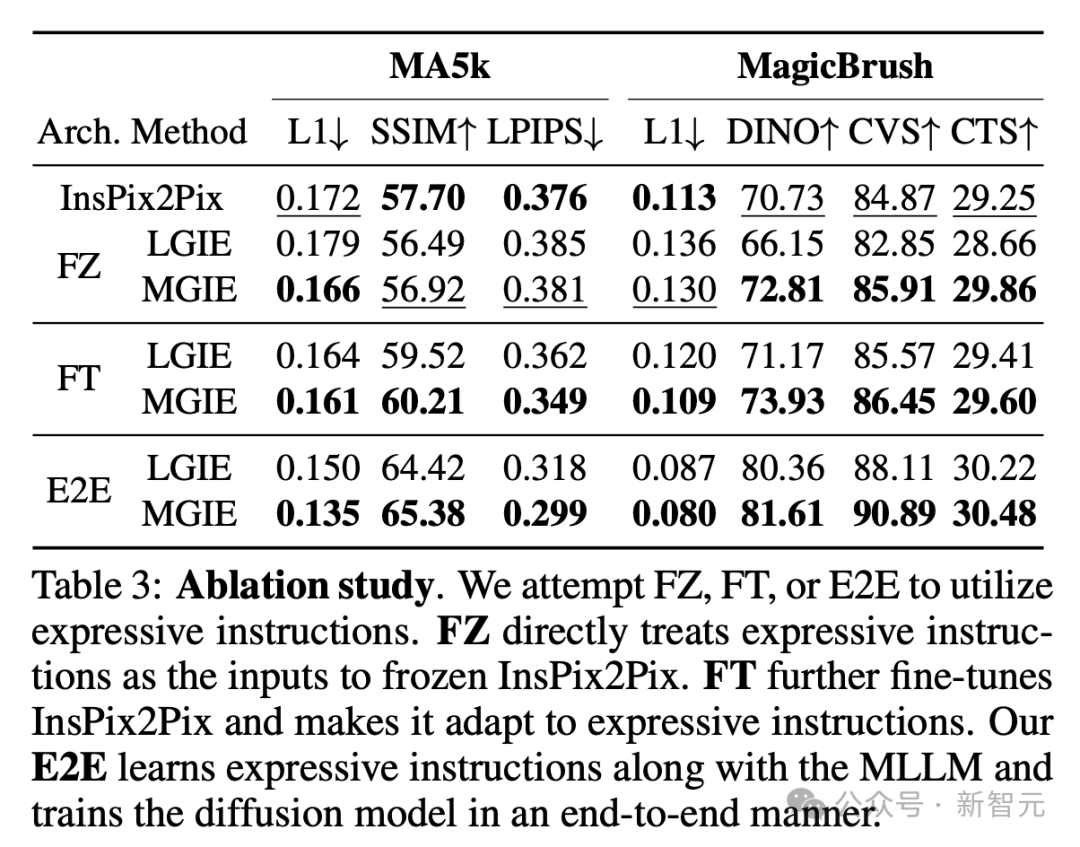
消融研究
MLLM引導圖像編輯在零樣本和微調場景中,都表現出了巨大的改進。
現在,團隊還研究了不同的架構來使用表達指令。
表3中,研究人員將FZ、FT和E2E架構進行了對比,結果表明,圖像編輯可以從LLM/MLLM指令推導過程中的明確指導中受益。
E2E與LM一起更新編輯擴散模型,LM學習通過端到端的隱藏狀態,同時提取適用的指導,並丟棄不相關的敘述。
此外,E2E還可以避免表達指令可能傳播的潛在錯誤。
因此,研究人員觀察到全局優化(MA5k)和本地編輯(MagicBrush)方面的增強最多。在FZ、FT、E2E中,MGIE持續超過LGIE。這表明具有關鍵視覺感知的表達指令,在所有消融設置中始終具有優勢。
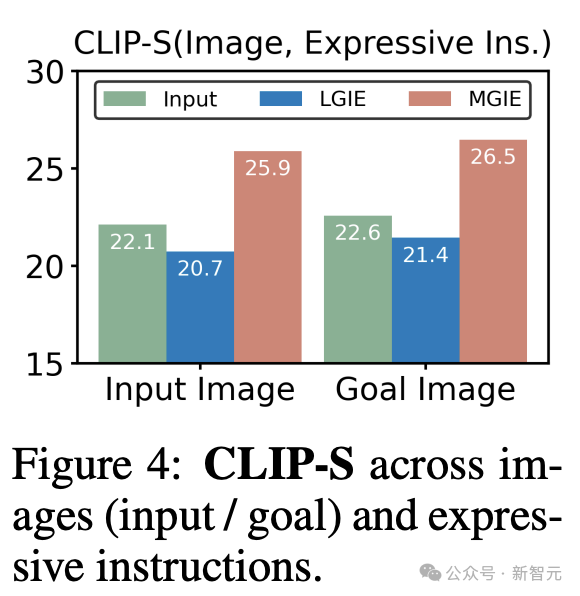
為什麼MLLM的指導有很大幫助?
圖4显示了輸入或真實目標圖像與表達指令之間的CLIP-Score值。
輸入圖像的CLIP-S分數越高,說明指令與編輯源相關。更好地與目標圖像保持一致可提供明確、相關的編輯指導。
由於無法獲得視覺感知,LGIE的表達式指令僅限於一般語言想象,無法針對源圖像量身定製。CLIP-S甚至低於原始指令。
相比之下,MGIE更符合輸入/目標,這也解釋了為什麼表達性指令很有幫助。有了對預期結果的清晰敘述,MGIE可以在圖像編輯方面取得最大的改進。
人工評估
除了自動評估指標外,研究還進行了人工評估,以研究生成的表達指令和圖像編輯結果。
研究人員具體為每個數據集隨機採樣25個示例(共100個),並考慮由人類對基線和MGIE進行排名。
為避免潛在的排名偏差,研究人員為每個示例聘請了3名標註者。
圖5显示了生成的表達性指令的質量。
首先,超過53%的人支持MGIE提供更實用的表達式指導,這有助於在明確的指導下完成圖像編輯任務。
同時,有57%的標註者表示,MGIE可以避免LGIE中由語言衍生的幻覺所產生的不相關描述,因為它認為圖像有一個精確的編輯目標。
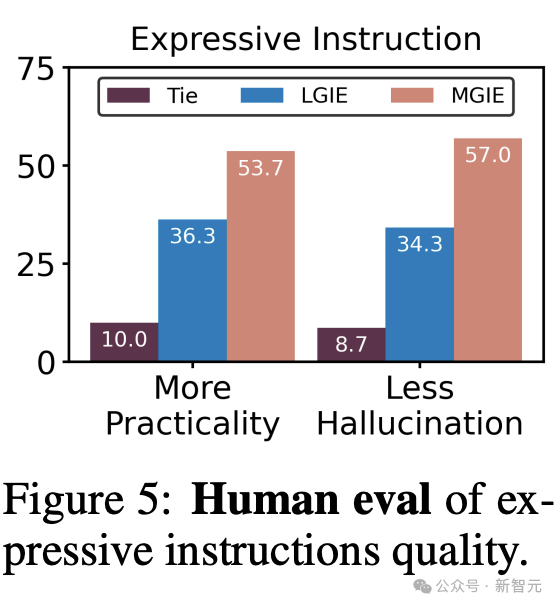
圖6比較了InsPix2Pix、LGIE和MGIE在指令遵循、地面真值相關性和整體質量方面的圖像編輯結果。排名分數從1-3不等,越高越好。
利用從LLM或MLLM派生的表達式指令,LGIE和MGIE的表現均優於基線,其執行的圖像編輯與指令相關,並與地面真值目標相似。
此外,由於研究中的表達式指令可以提供具體的視覺感知指導,因此MGIE在包括整體編輯質量在內的各個方面都具有較高的人類偏好。這些性能趨勢也與自動評估結果一致。

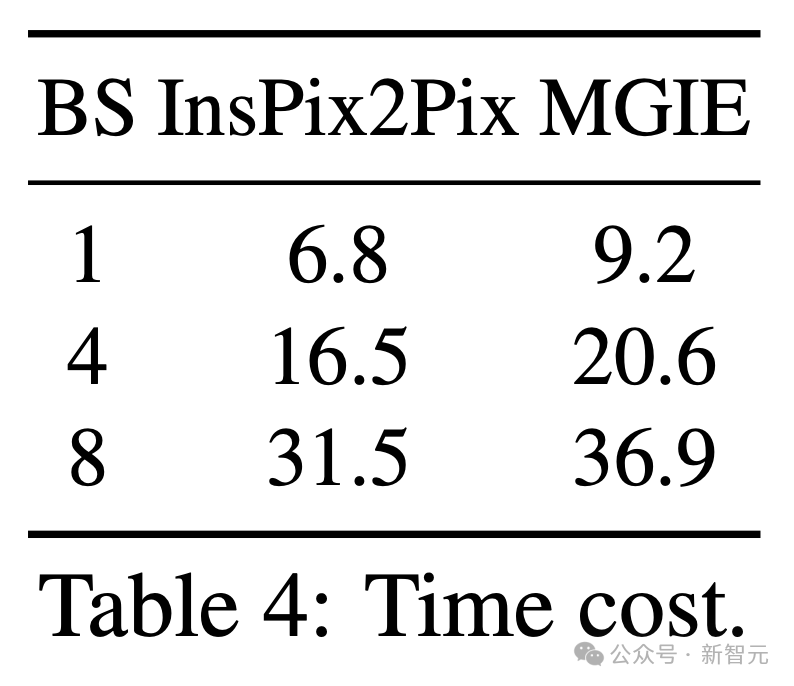
推理效率
儘管依靠MLLM來促進圖像編輯,MGIE僅給出了簡潔的表達指令(少於32個token)並包含與InsPix2Pix一樣的可行效率。
表4显示了NVIDIA A100 GPU上的推理時間成本。
對於單次輸入,MGIE可以在10秒內完成編輯任務。隨着數據并行化程度的提高,我們花費了相似的時間(例如,當批大小為8時,需要37秒)。
整個過程只需一個GPU(40GB)就可以負擔得起。
總之,MGIE超越了質量基準,同時保持了有競爭力的效率,從而實現了有效且實用的圖像編輯。
定性比較
圖7展示了所有使用的數據集的可視化比較。

圖8進一步比較了LGIE或MGIE的表達指令。

總之,在最新研究中,UCSB和蘋果團隊提出了MLLM引導圖像編輯(MGIE),通過學習生成表達指令來增強基於指令的圖像編輯。
參考資料:
https://github.com/apple/ml-mgie