所有語言











分享
個性經濟時代,MiniMax 語音大模型如何 To C?
巴比特_AI梦工厂440天前
文章來源:AI科技評論
作者:王悅

圖片來源:由無界AI生成
大約一個月前,距離 GPT Store 上線還有兩周,一位名為 Kyle Tryon 的國外開發者在個人博客上分享了其基於 ChatGPT Plus 開發的三個 Agent(又稱“GPTs”),其中一個 Agent 是關於美國費城旅遊出行的個人指南“PhillyGPT”,它能訪問當地 SEPTA 公共交通 API,為個人提供費城當地的實時天氣、旅遊資訊、文藝演出活動、出行路線、公交車站與地標數據、預計抵達時間等等。
具體可訪問 PhillyGPT 鏈接:https://chat.openai.com/g/g-GlYMtkbse-phillygpt
費城個人指南的開發背後,實際是人們對於 GPT 時代 C 端個性消費產品的真正想象。無獨有偶,1 月 11 日 OpenAI 正式上線 GPT Store 后,公布 300 萬個 GPTs 之餘,也將與用戶日常消費活動息息相關的徒步路線指南“AllTrails”放在推薦榜單上。與國內對大模型前景頗有微詞的情況不同,海外大量的個性化應用開發正如火如荼。
個性經濟時代,國內大模型經濟的發展,實則要改變舊的解題思路。
在國內一眾大模型廠商中,MiniMax 就是一家堅持產品創新、追求個性應用的“少數者”。從這一初衷出發,自去年 3 月初亮相起,當大多數團隊還處於語言大模型起步階段時,MiniMax 就以多模態大模型的定位在擁擠的賽道中出類拔萃,估值突飛猛進,成為國內估值最高的大模型廠商之一。
尤為值得注意的是,MiniMax 也是極少數下注語音大模型的團隊之一。
區別於文本、圖像,語音大模型的研發由於方向小眾,社區數據生態並不繁榮,難以獲得大量的高質量數據進行模型訓練。但在社交、互娛、教育等具有大量個人用戶的場景中,聲音又往往是許多 To C 與 B2B2C 產品的重要構成,是大模型商業化的兵家必爭之地。
近日,MiniMax 也推出了新一代語音大模型,在多項性能指標上超越了傳統的語音技術。
語音模型的能力在 MiniMax 自家產品星野中有廣泛運用。在近期星野 APP 內發起的 AI 挑戰賽中 , MiniMax 語音模型的能力得到充分展示。不僅能語音合成得很自然,還能模擬真人 rap,花樣百出,逼近真人 rapper 水準。
(有想在星野 AI 戰賽中跟 AI battle rap 的朋友可點擊:https://m.xingyeai.com/share/chat?npc_id=64236&share_user_id=54072629321819 進行體驗):
據 AI 科技評論了解,MiniMax 最新語音大模型基於長達數百萬小時的高質量音頻數據進行訓練,效果不輸 ElevenLabs 和 OpenAI。
同時,MiniMax 也在积極推進語音能力的落地應用,在 To B 側面打造了開放平台,不斷迭代 B 端用戶所需要語音能力,在 To C 側面上線了 AI 語音對話產品「海螺問問」,僅需 6 秒音頻即可進行音色復刻。
GPT 時代,MiniMax 的大模型經濟打破了單一文本的局限,從“聲”出發,定義了個性化應用的新內涵。
1、每個硅基用戶都能有自己的聲音
AIGC 時代,語音生成的需求實際並不亞於文本與圖像。
從 AI 落地的角度來看,大語言模型能夠預測出文字序列,是 AIGC 產品工程化的第一步,但在實際應用中,單一的文字呈現效果往往不佳,聲音的表現力能為文字內容的情感色彩、個性表達提供有力加持。
以 AI 視頻生成為例。在用 AI 技術生成短視頻的場景中,“齣戲”是用戶體驗減分的主要短板,而聲音則往往是用戶齣戲的“罪魁禍首”。在 AIGC 產品的應用中,人物音色的還原度、語流語調的流暢度、說話停頓的自然度是語音合成技術的主要挑戰,且必須“打包”解決,不能顧此失彼,任一短板都會降低用戶的產品體驗。
不同場景對語音合成效果的要求也不同。例如,数字人直播帶貨要求主播與觀眾的語音互動時效性高、延時性低,復刻有聲書需要快速批量生成多角色的音色和語音內容,教育教學場景要求達到對一些特殊字詞和生僻字的精準發音。
因此,在傳統語音合成技術的基礎上,面向用戶提供高品質、個性化的語音體驗與服務,成為語音生成的下一道難題。
過去,市面上的語音合成技術痛點明顯:
- 机械感較強,原因是犧牲部分人聲的自然度,聲音無法傳遞出情感;
- 音色較單一,以至於無法提供多種音色供用戶選擇,也就不能滿足不同場景的多樣化需求;
- 成本高且效率低下,需要專業的設備且耗時較長。
為了解決這一系列痛點,國內外不少頭部大廠也進行過相關探索。
谷歌的多模態大模型 Gemini 嘗試對當下流行的文本、圖像與語音三種模態的輸入內容進行無縫理解和推理,但在實際應用中,Gemini 的文本、視覺、音頻被認為是一種“僵硬的拼接狀態”。更多關於海內外大模型廠商的信息歡迎添加作者:s1060788086 來聊。
初創企業 ElevenLabs 的語音合成效果驚艷,但更適合英文文本,中文語音合成能力稍遜。
還有諸如 Tortoise 和 Bark 的開源 TTS 模型也積累了一定量的用戶,但根據使用反饋,Tortoise 生成速度慢,Bark音質參差,目前較難商用。
與同行爭相競技,MiniMax 也在不斷迭代其自研的語音大模型,最新語音大模型使 MiniMax 成為國內第一個開放多角色配音商用接口的大模型公司。
依託新一代大模型能力,MiniMax 語音大模型能夠根據上下文智能預測文本的情緒、語調等信息,並生成超自然、高保真、個性化的語音,以滿足不同用戶的個性化需求。
相較於傳統語音合成技術,MiniMax 的語音大模型以更精準、快速的方式,在音質、斷句氣口、韻律節奏等方面達到以“AI”亂真的合成新高度。
通過結合標點符號以及上下文語境,MiniMax 語音大模型能全方位解讀文字背後隱藏的情感、語氣,甚至是笑聲,都能把握得恰如其分。
在一些特殊語境下,它還能展示出極富戲劇性的聲音張力,比如,當說話者被朋友的笑話逗得捧腹大笑時,它也能配合上這種誇張的情緒,同時開懷大笑。
除了超自然的 AI 語音生成效果外,MiniMax 語音大模型的另一個亮點是多樣化、高延展——它能夠精確捕捉到數千種音色的獨特特徵,並自由組合,輕鬆創造出無限的聲音變化、情感和風格。這一優勢能夠靈活地滿足社交、播客、有聲書、新聞資訊、教育、数字人等多種場景中。
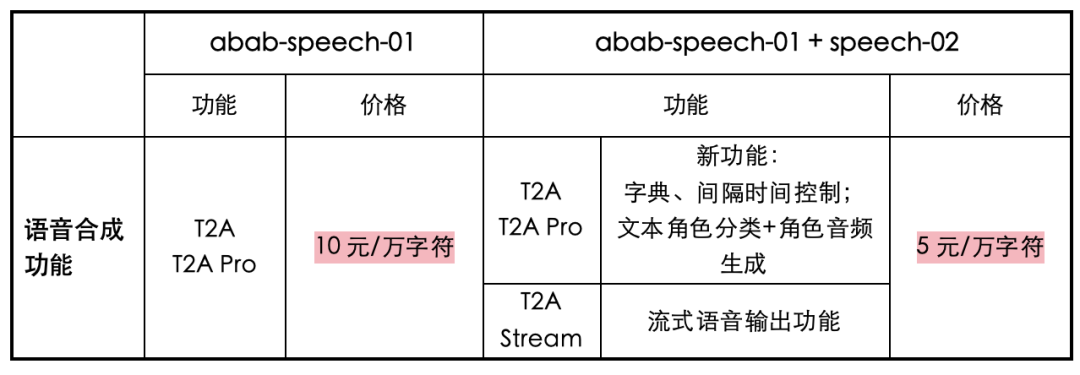
2、長文本語音生成,API 價格降一半
2023 年下半年開始,大模型行業出現兩個短兵相接的戰場,一是長文本,二是商業化。前者的競爭同樣集中在文本領域,從 32k 到 200k 的競爭均已白熱化,語音生成則還是一片藍海;而後者的商業化則主要體現在價格上。
一位大模型從業者告訴 AI 科技評論,“大模型的技術壁壘在降低,到最後就是拼誰能最先將模型訓練與部署的成本降下來。”市場對大模型的需求,不再是 ChatGPT 剛火時的二選一,而是既要高性能的模型質量、又要有行業競爭力的產品服務。
在語音生成領域,MiniMax 的文本-語音接口也經歷了快速的迭代:
2023 年 9 月 12 日,MiniMax 發布了長文本-語音合成接口 T2A pro,單次語音合成最高可輸入 35000 字符,可以調整語調、語速、音量、比特率、採樣率等相關參數,主要適用於長文本有聲化。
2023 年 11 月 15 日,MiniMax 異步長文本接口 T2A large 上線,支持用戶每次上傳文本篇幅長達 1000 萬字符。
2023 年 11 月 17 日,MiniMax 發布語音大模型 abab-speech-01,其韻律節奏、情感表現、風格多樣性、中英混、多語言等能力等整體效果都得到了明顯提升。
模型性能提升的同時,MiniMax 也將 API 的價格打了下來:據官方消息,近日 MiniMax 的三個文本-語音接口 T2A pro、T2A、T2A Stream 的價格都已下調為原有價格的一半,從 10 元/萬字符降至 5 元/萬字符。
基於其自研多模態大模型底座,MiniMax 語音大模型在語音助手、資訊播報、IP 復刻、CV 配音等領域也做了布局。
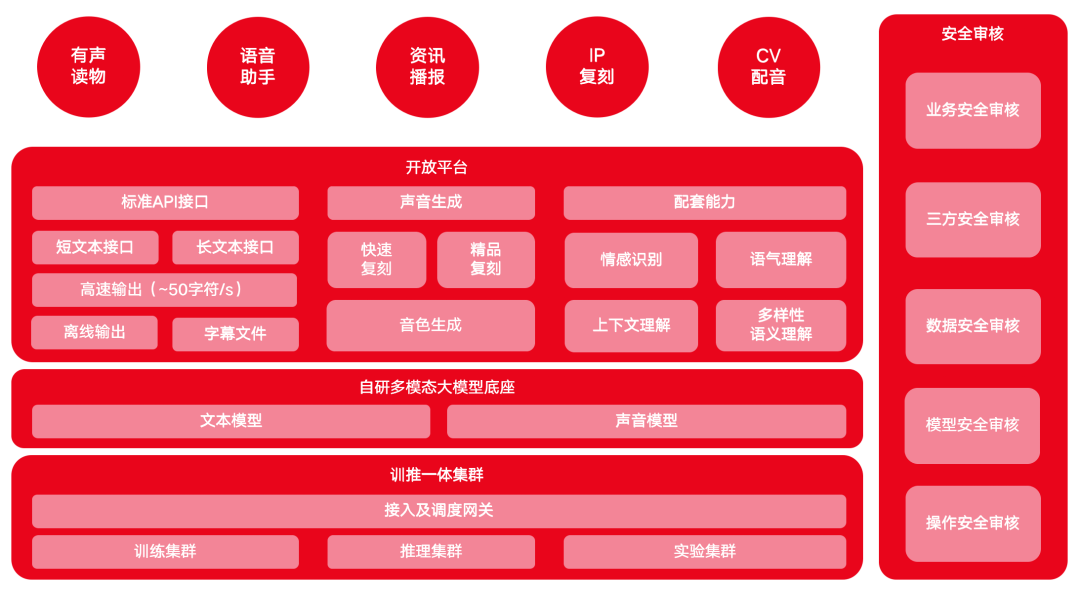
MiniMax語音大模型產品架構
為了精進模型能力以滿足用戶對語音的高優需求,2024 年 1 月, Mini Max 開放平台在原有接口能力的基礎上新增了以下產品功能:
- 新增三個 API 接口,分別是多角色音頻生成API、文本角色分類 API 和快速復刻 API,主要適用於自主批量生成、克隆多角色音頻的場景;
- 增加 T2A Stream (流式語音輸出)能力,減少用戶生成語音的等待時間,實現語音生成與輸出同步;
- 增加多語種能力、字典功能、間隔時長控制功能,滿足用戶豐富的定製化需求。
具體來說,文本角色分類 API 可以快速分辨出不同角色對應的不同對話,角色音頻生成 API 可實現多角色區分、多角色播報,快速復刻 API 可以讓用戶線上快速完成音色復刻。三個 API 結合使用,提供了一整套基於文本的角色聲音生產方案——更高效的角色劃分,多角色的語音生成,全自助的音色復刻。
MiniMax 告訴 AI 科技評論,該開放平台新增的 3 個 API 接口是為了較好應對篇幅較大的文本內容。
在長文本的語音生成上,過去的一貫做法是用人工標註每段對話的角色歸屬,再由語音模型生成虛擬聲音,缺點是費時費力。而 MiniMax 的語音大模型開放平台使用接口調用,能夠更高效地幫助用戶生成多角色聲音。
以有聲書的製作為例。MiniMax 語音開放平台的三個 API 功能接口結合,能省略人工劃分文本角色的步驟,自動理解文本、劃分角色、為不同角色創造不同聲音。聯合起點打造有聲讀物的 AI 新音色"說書先生"與"狐狸小姐",即通過三個接口在線上自主完成高質的聲音復刻。這樣既能保證人物音色的一致性,又能高效、快捷地對多角色進行配音。
T2A Stream (流式語音輸出)能夠以 500 字符的輸入處理能力迅速響應。針對需要即時反饋的情景,在互動形式的對話中實時生成語音,用戶無需等待即可獲得語音回復。
同時,T2A Streaming 有混音功能和字符檢查功能保障輸出內容質量,並提供語調、語速、音量等參數供用戶隨時調節。它還支持多種音頻格式(MP3、 WAV、PCM等)和返回參數(音頻時長、大小等),開發者能夠依據特定應用的需求來定製化語音服務。
在滿足用戶定製化需求方面,MiniMax 的語音大模型也升級了三項新功能:
一是多語種能力,使中英文混合輸出的聲音更自然。
多語種混雜的文本是語音生成的一大難點,頻繁的語言切換會導致發音不自然。MiniMax 的語音模型提高了多語言處理能力,在外語教學、口語對話等場景中能夠為用戶提供更真實的語音體驗。
例如,輸入文本:“你可以說'In winter, the trees are bare and all the leaveshave fallen off. 這樣形容就很形象地傳達出那種空空蕩蕩、沒有恭弘=叶 恭弘子的樹木的冬季景象了。
二是字典功能,允許用戶自定義文本讀音。
語音模型在根據文本生成聲音時會出現發音不準確、讀音有偏差的情況,尤其是面對含多音字、特殊符號、文字簡寫、用戶自創的文本內容。為提高發音準確度,MiniMax 語音大模型增加了字典功能,允許用戶自主定義文本的讀音。
例如:"text" (文本) : omg,單田芳的評書可真是模仿得惟妙惟肖啊。
"char_ to pitch" (標註) : ["單田芳/(shan4)(tian2)(fang1)","omg/oh my god"]
通過這一字典功能,“ 單田芳”和“omg”等多音字和縮略語能夠在生成的語音中被正確發音。
三是間隔時長控制功能,可以精細地改善停頓節奏。
MiniMax 語音大模型增加了間隔時長控制功能,讓開發者自由在文本中添加不同長度的停頓,精細地調整語句之間的間隔時間、改善停頓節奏,生成語音會更符合真實的教學場景。
這一功能更多被運用在教育教學場景中,其中與高途合作打造的 AI 考研数字人“文勇老師”可以通過這一功能更好地進行聽課、答疑,使學生獲得更流暢的學習體驗。
此外,這一間隔時長控制功能也同樣讓有聲書角色或数字人配音更自然,可以有效扭轉傳統生成語音無停頓的机械感,增加語音的節奏,更加貼近真人的表達習慣。
教學場景中經常會遇到這樣的對話:
老師說:小朋友們,大家好!我是你們的數學老師,我給大家出一個小小的挑戰。請聽題:小明有7個蘋果,如果給了小華 3 個蘋果,那麼小明還剩下多少個蘋果呢?給你們 10 秒鐘的時間思考,去找出答案吧!< <#10#> 時間到!大家能告訴我答案是什麼嗎?對了,小明還剩下4個蘋果,那麼恭喜你,答對了!因為 7 減去 3 等於 4,所以小明還有 4 個蘋果。
在這裏,使用控制代碼<#X#> (其中 X 是一個数字變量, 單位為秒,取值範圍從 0.01 到 99.99 秒)添加間隔標識,就可以在文本中加入用戶想要的語音停頓時長。
3、海螺問問 To C,語音拉近人與 AI 的距離
自創立以來,MiniMax 就以 To C 產品形態創新聞名於世。
據 MiniMax 透露,他們在商業化上用 To B 與 To C 兩條腿同時走路;而在投資人與市場的眼中,其 C 端產品的創新在國內一眾大模型廠商中一騎絕塵,從 Glow 到星野,MiniMax 的 C 端產品一直為人矚目。
To C 層面,MiniMax 的語音大模型也發揮了獨特的優勢,這首先體現在其對話產品海螺問問上。

在這款以大語言模型技術為基礎的語音對話產品中,MiniMax 自研語音大模型的加持讓海螺問問在同類產品中脫穎而出。AI 科技評論一手評測后,最為其超自然、高保真的語音效果所驚訝。單從聽感上來講,海螺問問輸出的問答聲音難以區分是真人發聲還是其語音大模型合成。
例如,在被問到「周末去哪玩?」時,海螺問問輸出的語音條就像是一個朋友的口吻和身份,輕輕鬆松地與對方對話、交流、討論,而不是如傳統 AI 合成語音那般机械地、一字一字蹦出來生成的內容。
聽到有趣的問題,海螺問問會發笑;遇到不好回答的問題時,海螺問問會沉吟、會停頓,彷彿在“思考”。如果不是向 MiniMax 求證其在海螺問問上接入了語音大模型,用戶大概率會以為機器的另一端是真人對答。
為了達到實時對話的效果,海螺問問在低延時上表現突出,無需傳統大模型 5 - 10 秒的思考時間,通過 T2A Stream 能力即時輸出。除了語音條的交互形式,也可以點擊 UI 界面中右下角的電話小圖標,開啟實時語音通話。
在正式通話前,用戶可以自主選擇想要 AI 輸出的音色。其中,既有「模仿熊二」的卡通風格,也有「心悅」這般具有親和力的女聲,也有「子軒」低沉有磁性的男聲,更有「胖橘」這種類似於古裝影視劇中的皇室代表性音色。
除了系統預置的幾十種不同風格的聲音之外,海螺問問還可以創建自己的聲音,在較短時間內通過低樣本迅速進行語音復刻。只需要根據界面的指令,朗讀一段 40 字左右的給定文本,等待幾秒,即可聽到高還原度的自己的聲音。

如此一來,使用海螺問問的每個普通用戶都可以輕鬆實現無限復刻聲音的需求。
但其實,語音復刻的能力在當下的市場中往往是需要付費使用的。很多 AIGC 應用層的廠商會將其視作自家兜售的商品之一,使用者需費時費力地錄製自己的音頻,再花大幾千甚至是幾萬的價格,為逼真的語音復刻效果買單。在此基礎上,還需要限制使用的次數、時長、主體,是個妥妥的賺錢生意。
而海螺問問則免費對用戶開發聲音復刻的功能,不僅不收費,也不對使用的時長和次數進行限制。同時,操作的流程也很簡單,只需 6 秒即可獲得克隆音頻,這無疑降低了人們使用 AI 改變生活、生產的門檻,在很大程度上方便自己使用。
很多用戶反饋,會在海螺問問中錄入媽媽的聲音,這樣在向 APP 諮詢生活中的問題時,就彷彿媽媽在旁邊為自己答疑解惑,在想要搜索菜譜的時候,就像媽媽在教自己做飯;更有人將失去親人的聲音保留在海螺問問中,通過聲音緬懷過去。
另外,海螺問問的意義也不止於用戶提問、智能體回答,它在更大程度上是一個能夠隨意交談的聊天軟件。無需像書面表達一樣特別在意語句的準確性、規範性等問題,想說什麼即說什麼,想怎麼說就怎麼說,海螺問問都能接招,甚至有時候還會引導話題,主動發問。
更值得期待的是,這两天分享聲音的功能將要在海螺問問上線。AI 科技評論獨家獲悉,通過這一功能,用戶之間便可以通過類似口令紅包的方式,在微信等社交媒體上相互分享自己克隆出來的聲音,進一步實現「語音社交」。
讓 AI 聲音像人一樣自然好聽動人,MiniMax 語音大模型在海螺問問上的技術突圍和一系列嘗試,是向消除人與人工智能隔閡邁出的一個大步子。
過去,人工智能賽道對於語音的理解,是提高語音輸入、輸出的準確率。現在, MiniMax 則不忘把一縷目光放在影響用戶體驗的語音交互效果上,這反映的是這家“年輕”公司的戰略眼光和執行能力。
2024年,MiniMax 打響語音大模型第一槍,或許值得每一個同行業的探索者思考:當下的世界究竟要向什麼方向迭代技術?究竟需要怎樣的大模型?究竟要做什麼樣的產品?