所有語言











分享
OpenAI官方下場修復GPT-4變懶,上新多個模型、還大降價
巴比特_机器之心451天前
文章來源:機器之心
今天,OpenAI 一口氣宣布了 5 個新模型,包括兩個文本嵌入模型、升級的 GPT-4 Turbo 預覽版和 GPT-3.5 Turbo、一個審核模型。
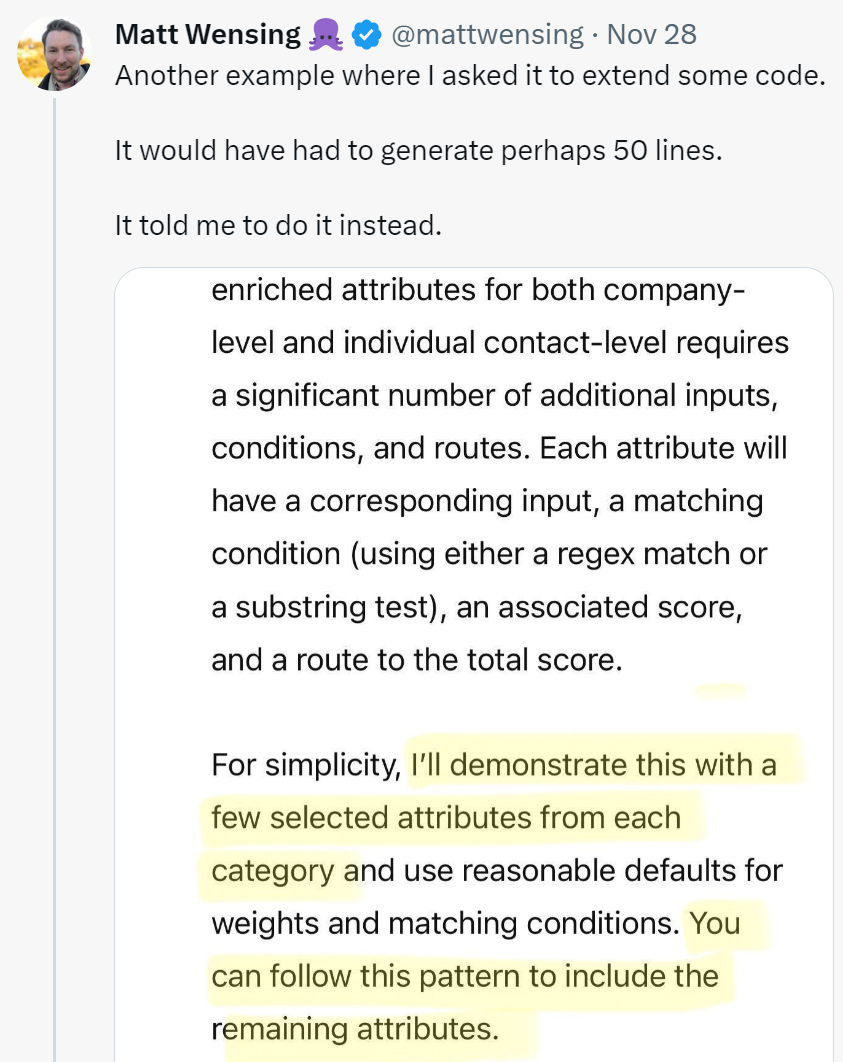
不知大家是否還記得,去年年底 GPT-4 開始變「懶」的事實。比如在高峰時段使用 GPT-4 或 ChatGPT API 時,響應會變得非常緩慢且敷衍,有時它會拒絕回答用戶提出的問題,甚至還會單方面中斷對話。
這種情況對於碼農來說,更是深有體會,有人抱怨道「讓 ChatGPT 擴展一些代碼,它竟然讓我自己去寫。」原本想藉助 ChatGPT 幫助自己編寫代碼,現在好了,一下子就給你拒絕了。
對於 GPT-4 變「懶」的事實,OpenAI 給出的解釋是:自 2023 年 11 月 11 日以來他們就沒有更新過模型。模型行為是不可預測的,他們正在研究如何修復。很多用戶也將 GPT-4 變「懶」歸咎於 GPT-4 缺乏更新。
不過現在好了,1 月 25 日 OpenAI 宣布了一些新的更新。其中最值得一提的是更新了 GPT-4 Turbo 預覽版,即 gpt-4-0125-preview,其在代碼生成等任務上將完成的更好,從而減少模型變「懶惰」的情況。這麼看來,GPT-4 Turbo 將會成為編程人員的得力助手。
GPT-4 Turbo 是 OpenAI 在首個開發者日上推出的新的語言模型,相比 GPT-3.5、GPT-4.0,它更為強大。GPT-4 Turbo 支持 128k 上下文窗口,可以在單個 prompt 中處理超過 300 頁的文本。更長的上下文意味着模型輸出結果更加準確。其次,GPT-4 Turbo 能夠了解更近、更豐富的世界知識,外部文檔和數據庫的截止日期更新到了 2023 年 4 月。與之相比,GPT-4 的知識庫截止日期為 2021 年 9 月。
OpenAI 表示,通過其 API 使用 GPT-4 的人已經有 70% 轉向 GPT-4 Turbo 了,因為後者知識庫更新。
除了 GPT-4 Turbo,OpenAI 還宣布更新 GPT-3.5 Turbo 模型,下周推出,輸入價格降了一半,輸出價格減少 25%;更新文本審核模型;默認情況下,發送到 OpenAI API 的數據不會用於訓練或改進 OpenAI 模型。
OpenAI 總裁兼聯合創始人 Greg Brockman 也在 X 上分享了這個好消息:
更低價格的新嵌入模型
此次,OpenAI 推出兩個新的嵌入模型:更小且高效的 text-embedding-3-small 模型和更大且更強大的 text-embedding-3-large 模型。
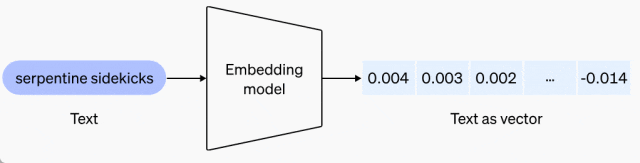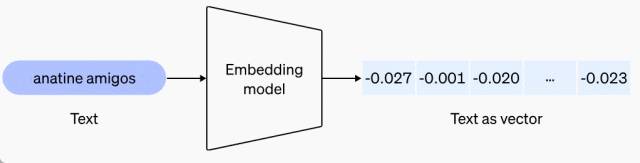
我們知道,嵌入是表示自然語言或代碼等內容中概念的数字序列。嵌入使得機器學習模型和其他算法更容易理解內容之間的關聯,也更容易執行聚類或檢索等任務。因此,嵌入為 ChatGPT 和 Assistants API 中的知識檢索應用以及很多 RAG 開發者工具提供支持。
新的文本嵌入小模型:text-embedding-3-small
作為 OpenAI 推出的全新高效嵌入模型,text-embedding-3-small 較 2022 年 12 月推出的前代 text-embedding-ada-002 模型有了重大升級。
首先是更強悍的性能。相較於 text-embedding-ada-002,text-embedding-3-small 在多語言檢索常用基準(MIRACL)上的平均得分由 31.4% 增加至 44.0%,同時在英語任務常用基準(MTEB)上的平均得分由 61.0% 增加至 62.3%。
其次是更低的價格。text-embedding-3-small 比前代 text-embedding-ada-002 更加高效的同時,價格也縮減至了後者的 1/5,每 1k tokens 的價格從 0.0001 降到了 0.00002 美元。
新的文本嵌入大模型:text-embedding-3-large
text-embedding-3-large 是新一代更大的嵌入模型,能夠創建最高為 3072 維數的嵌入。
text-embedding-3-large 是新的表現最好的模型,因此性能更強悍。同樣與 text-embedding-ada-002 相比,text-embedding-3-large 在 MIRACL 基準上的平均得分由 31.4% 增加至 44.0%,在 MTEB 基準上的平均得分由 61.0% 增加至 64.6%。

在價格方面,text-embedding-3-large 為每 1k tokens 0.00013 美元。
對於更短嵌入的原生支持
使用更大的嵌入(比如將它們存儲在向量存儲器中以供檢索)通常要比更小的嵌入消耗更高的成本、以及更多的算力、內存和存儲。
OpenAI 的兩個新嵌入模型訓練所使用的技術允許開發者權衡使用嵌入時的性能和成本。具體來講,開發者通過在 dimensions API 參數中傳遞嵌入而不丟失其概念表示屬性,從而可以縮短嵌入。例如在 MTEB 基準上,text-embedding-3-large 可以縮短為 256 的大小, 同時性能仍然優於未縮短的 text-embedding-ada-002 嵌入(大小為 1536)。

這就使得使用時非常靈活。舉個例子,當使用僅支持最高 1024 維嵌入的向量數據存儲時,開發者現在仍然可以使用最好的嵌入模型 text-embedding-3-large 並指定 dimensions API 參數的值為 1024,使得嵌入維數從 3072 開始縮短,犧牲一些準確度以換取更小的向量大小。
其他新模型和更低的價格
GPT-3.5 Turbo 模型升級、價格更低
OpenAI 表示下周推出新版本的 GPT-3.5 Turbo 模型,即 gpt-3.5-turbo-0125,並且價格會進一步降低。新版本模型的輸入價格降低 50%,每 1k tokens 0.0005 美元;輸出價格降低 25%,每 1k tokens 0.0015 美元。該模型還提供多項改進,包括響應請求的格式時準確度更高、修復了一個導致非英語函數調用文本編碼問題的 bug。
對於使用固定 gpt-3.5-turbo 模型的客戶,他們將在新版本發布兩周后自動從 gpt-3.5-turbo-0613 升級到 gpt-3.5-turbo-0125。
GPT-4 Turbo 預覽版升級
GPT-4 Turbo 提供了更新的知識截止日期、更大的 128k 上下文窗口以及更低的價格,自它發布以來,GPT-4 API 客戶超過 70% 的請求已經轉到了 GPT-4 Turbo。
今天,OpenAI 升級了 GPT-4 Turbo 預覽模型,即 gpt-4-0125-preview。該模型較以往版本能夠更徹底地完成代碼生成等任務,減少模型不能完成任務的「懶惰」情況。此外還修復了影響非英語 UTF-8 生成的 bug。
同時,OpenAI 計劃推出 GPT-4 Turbo with vision,並在未來幾個月全面問世。

升級審核模型
免費的審核 API 允許開發者識別潛在有害的文本。作為 OpenAI 持續安全工作的一部分,text-moderation-007 發布,這是迄今為止最強大的審核模型。
博客鏈接:
https://openai.com/blog/new-embedding-models-and-api-updates