所有語言











分享
擴散模型更懂複雜提示詞!Pika北大斯坦福開源新框架,利用LLM提升理解力
原文來源:量子位

圖片來源:由無界 AI生成
Pika北大斯坦福聯手, 開源最新文本-圖像生成/編輯框架!
無需額外訓練,即可讓擴散模型擁有更強提示詞理解能力。
面對超長、超複雜提示詞,準確性更高、細節把控更強,而且生成圖片更加自然。
效果超越最強圖像生成模型Dall·E 3和SDXL。
比如要求圖片左右冰火兩重天,左邊有冰山、右邊有火山。
SDXL完全沒有符合提示詞要求,Dall·E 3沒有生成出來火山這一細節。

還能通過提示詞對生成圖像二次編輯。

這就是文本-圖像生成/編輯框架RPG(Recaption,Plan and Generate),已經在網上引起熱議。

它由北大、斯坦福、Pika聯合開發。作者包括北大計算機學院崔斌教授、Pika聯合創始人兼CTO Chenlin Meng等。
目前框架代碼已開源,兼容各種多模態大模型(如MiniGPT-4)和擴散模型主幹網絡(如ControlNet)。
利用多模態大模型做增強
一直以來,擴散模型在理解複雜提示詞方面都相對較弱。
一些已有改進方法,要麼最終實現效果不夠好,要麼需要進行額外訓練。
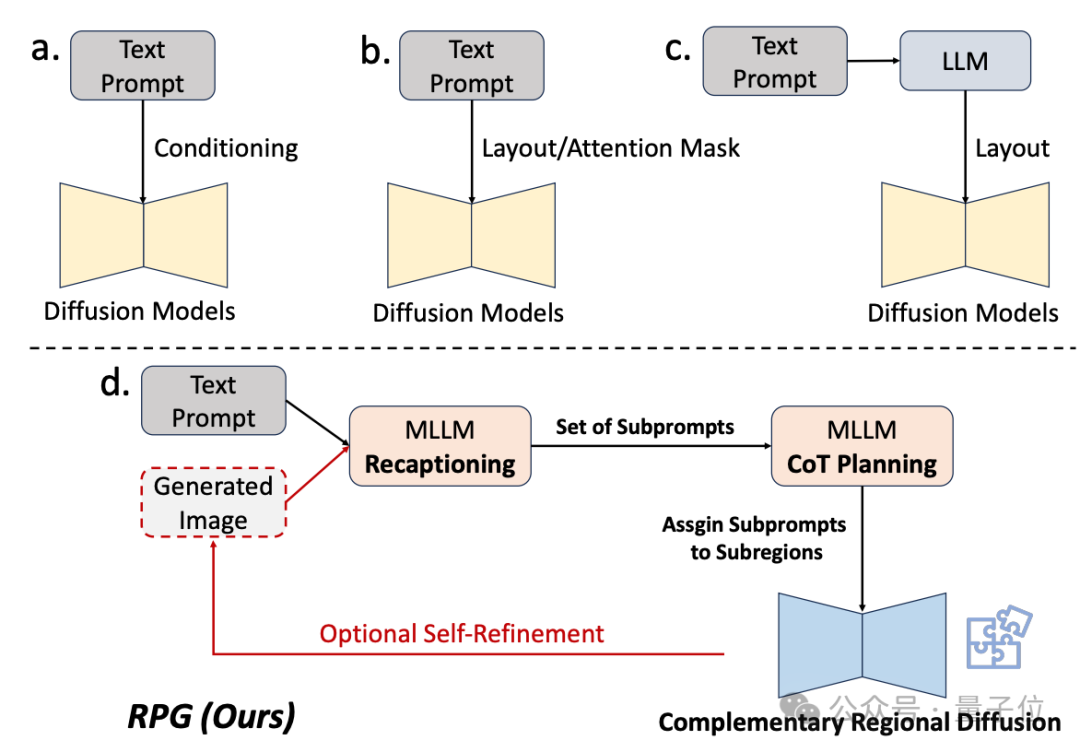
因此研究團隊利用多模態大模型的理解能力來增強擴散模型的組合能力、可控能力。
從框架名字可以看出,它是讓模型“重新描述、規劃和生成”。
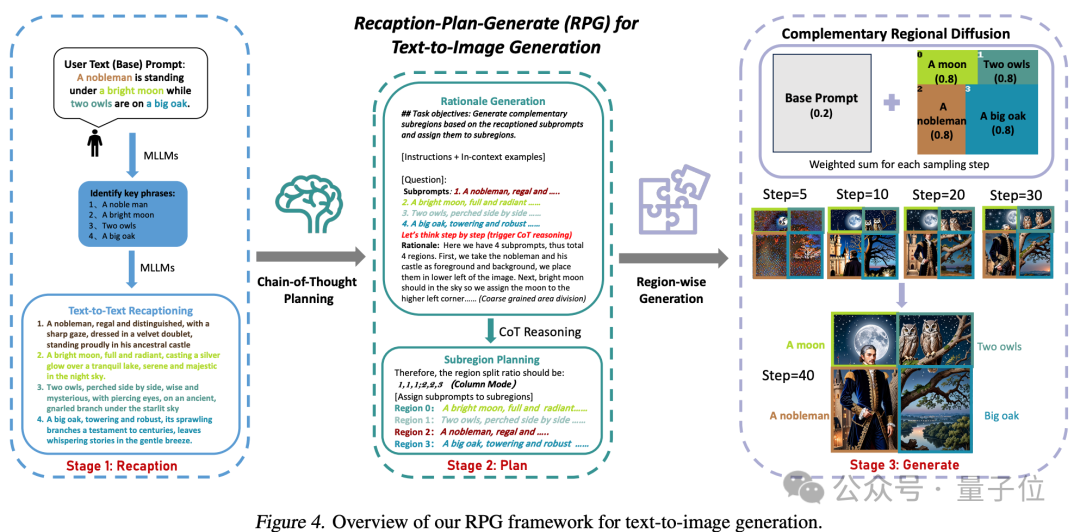
該方法的核心策略有三方面:
1、多模態重新描述(Multimodal Recaptioning):利用大模型將複雜文本提示拆解為多個子提示,並對每個子提示進行更加詳細的重新描述,以此提升擴散模型對提示詞的理解能力。
2、思維鏈規劃(Chain-of-Thought Planning):利用多模態大模型的思維鏈推理能力,將圖像空間劃分為互補的子區域,併為每個子區域匹配不同的子提示,將複雜的生成任務拆解為多個更簡單的生成任務。

3、互補區域擴散(Complementary Regional Diffusion):將空間劃分好后,非重疊的區域各自根據子提示生成圖像,然後進行拼接。
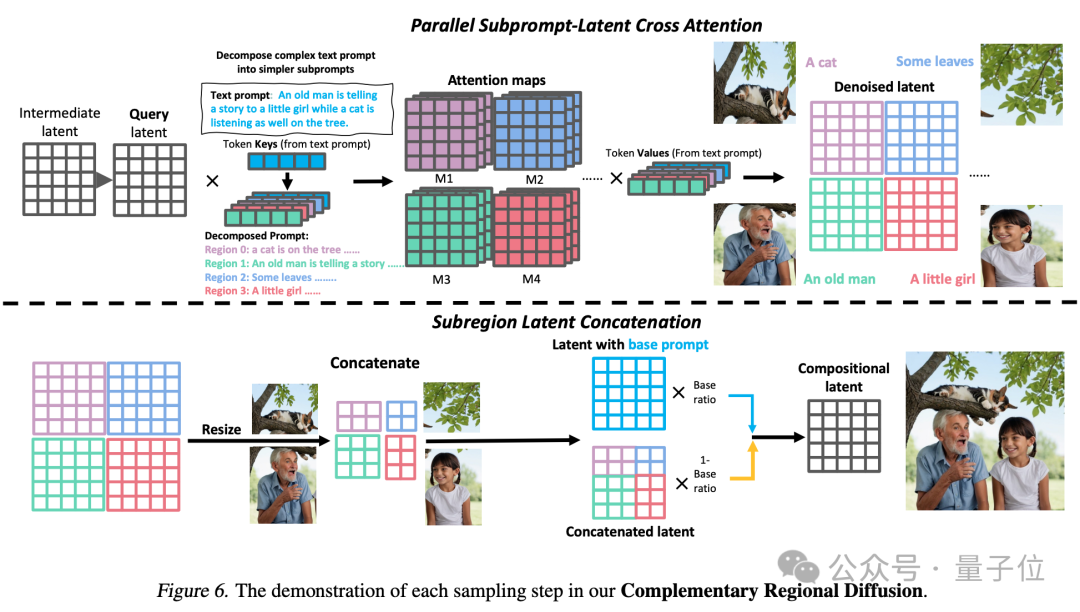
最後就能生成出一張更加符合提示詞要求的圖片。

RPG框架還可以利用姿態、深度等信息進行圖像生成。
和ControlNet對比,RPG能進一步拆分輸入提示詞。
用戶輸入:在一間明亮的房間里,站着一位身穿香檳色長袖正裝、正閉着雙眼的漂亮黑髮女孩。房間左邊放着一隻插着粉色玫瑰花的精緻藍花瓶,右邊有一些生機勃勃的白玫瑰。
基礎提示詞:一個漂亮女孩站在她的明亮的房間里。
區域0:一個裝着粉玫瑰的精緻藍花瓶
區域1:一個身穿香檳色長袖正裝的漂亮黑髮女孩閉着雙眼。
區域2:一些生機勃勃的白玫瑰。

也能實現圖像生成、編輯閉環。
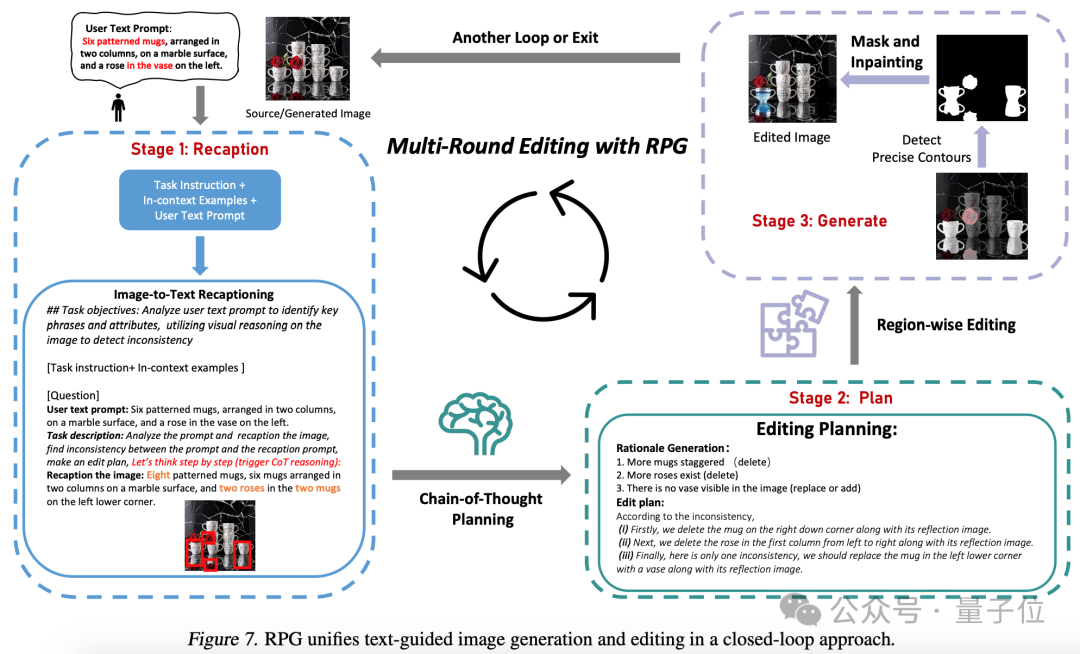
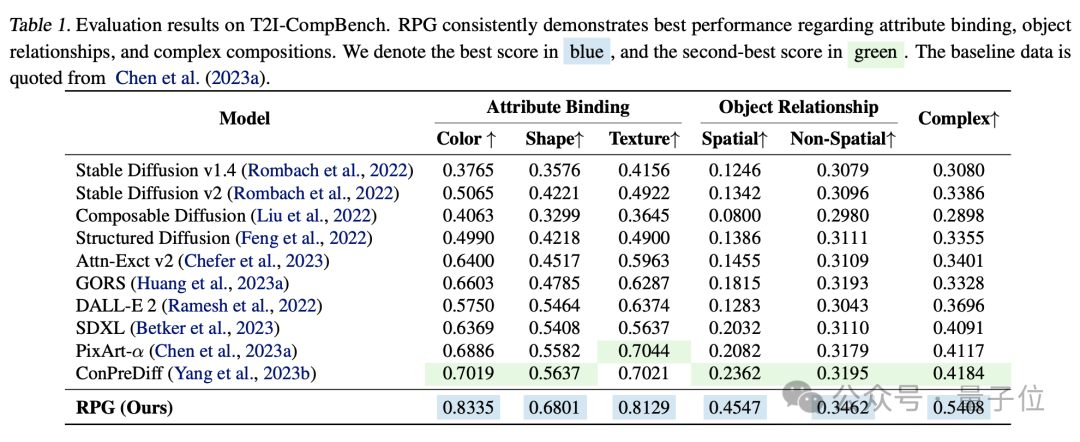
實驗對比來看,RPG在色彩、形狀、空間、文字準確等維度都超越其他圖像生成模型。
研究團隊
該研究有兩位共同一作Ling Yang、Zhaochen Yu,都來自北大。
參与作者還有AI創企Pika聯合創始人兼CTO Chenlin Meng。
她是斯坦福計算機博士,在計算機視覺、3D視覺方面有着豐富學術經歷,參与的去噪擴散隱式模型(DDIM)論文,如今單篇引用已有1700+。並有多篇生成式AI相關研究發表在ICLR、NeurIPS、CVPR、ICML等頂會上,且多篇入選Oral。
去年,Pika憑藉AI視頻生成產品Pika 1.0一炮而紅,2位斯坦福華人女博士創辦的背景,使其更加引人注目。

△左為郭文景(Pika CEO),右為Chenlin Meng
參与研究的還有北大計算機學院副院長崔斌教授,他還是數據科學與工程研究所長。

另外,斯坦福AI實驗室博士Minkai Xu、斯坦福助理教授Stefano Ermon共同參与這項研究。
論文地址:https://arxiv.org/abs/2401.11708
代碼地址:https://github.com/YangLing0818/RPG-DiffusionMaster
參考鏈接:
https://twitter.com/pika_research/status/1749956060868387101