所有語言











分享
畫個框、輸入文字,麵包即刻出現:AI開始在3D場景「無中生有」了
巴比特_机器之心452天前
原文來源:機器之心

圖片來源:由無界 AI生成
現在,通過文本提示和一個 2D 邊界框,我們就能在 3D 場景中生成對象。
看到下面這張圖了沒?一開始,盤子里是沒有東西的,但當你在托盤上畫個框,然後在文本框中輸入文本「在托盤上添加意大利麵包」,魔法就出現了:一個看起來美味可口的麵包就出現在你的眼前。

房間的地板上看起來太空蕩了,想加個凳子,只需在你中意的地方框一下,然後輸入文本「在地板上添加一個矮凳」,一張凳子就出現了:

相同的操作方式,在圓桌上添加一個茶杯:

玩具旁邊擺放一隻手提包統統都可以:

我們可以從以上示例看出,新生成的目標可以插在場景中的任意位置,還能很好地與原場景進行融合。
上述研究來自蘇黎世聯邦理工學院和谷歌,在論文《InseRF: Text-Driven Generative Object Insertion in Neural 3D Scenes》中,他們提出了一種名為 InseRF 的 3D 場景重建方法。InseRF 能基於用戶提供的文本描述和參考視點中的 2D 邊界框,在 3D 場景中生成新對象。

- 論文地址:https://arxiv.org/pdf/2401.05335.pdf
- 項目地址:https://mohamad-shahbazi.github.io/inserf/
- 項目主頁:https://mohamad-shahbazi.github.io/inserf/
在與其他方法的比較中,對於要求在玩具旁邊渲染出一個杯子,I-N2N 直接改變了玩具原來的模樣, MV-Inpainting 給出的結果更加糟糕,只有 InseRF 符合要求。

從左到右分別是原場景、 I-N2N 方法、 MV-Inpainting 以及 InseRF
這項研究重點關注在 3D 場景中插入生成對象(generative object insertion),這種方式在跨多個視圖的同時還能保持一致,並且新生成的對象可以擺放在場景中的任意位置上。
一般來講,使用 2D 生成模型在 3D 場景中插入生成對象是一項特別具有挑戰性的任務,因為它需要在不同視點中實現 3D 一致的對象生成和放置。一種簡單的方法是使用 3D 形狀生成模型單獨生成所需的對象,並使用 3D 空間信息將它們插入場景中。
然而,這種方法需要 3D 對象的準確位置、方向和比例。此外,與場景無關的對象生成可能會導致場景的樣式和外觀與插入對象之間的不匹配。
本文提出的 InseRF 很好地解決了上述問題,能夠使用對象的文本描述和單視圖 2D 邊界框作為空間指導,在 3D 場景中進行場景感知生成和插入對象。
方法介紹
本文將 3D 場景的 NeRF 重建、要插入目標對象的文本描述以及 2D 邊界框作為輸入。輸出結果會返回同一場景的 NeRF 重建,並且還包含在 2D 邊界框里生成的目標 3D 對象。
值得注意的是,由於研究者還會用擴散模型先驗來進行精確的 2D 定位,InseRF 只需要一個粗略的邊界框就可以了。
InseRF 由五個主要步驟組成:
1)基於文本提示和 2D 邊界框,在選定的場景參考視圖中創建目標對象的 2D 視圖;
2) 根據生成的參考圖像中的 2D 視圖重建 3D 對象 NeRF;
3) 藉助單目深度估計來估計場景中對象的 3D 位置;
4) 將對象和場景 NeRF 融合成一個包含估計放置物體的單個場景;
5) 對融合的 3D 表示應用細化步驟以進一步改進插入的對象。
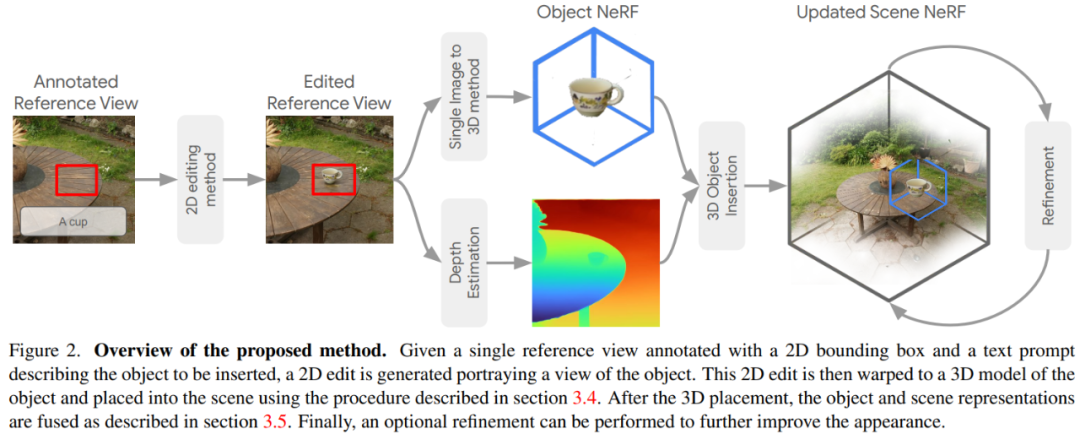
編輯參考視圖
編輯 pipeline:首先選擇場景的一個渲染視圖作為參考,並根據用戶提供的文本提示和 2D 邊界框插入目標對象的 2D 視圖。參考視圖用於提供參考外觀和位置來為 3D 插入奠定基礎。
為了確保輸入邊界框中的局部 2D 插入,本文選擇掩碼條件修復方法作為 2D 生成模型。具體來說,他們選擇 Imagen,這是一種強大的文本到圖像擴散模型,並通過使用 RePaint(一種使用擴散模型進行掩碼條件修復的方法)進一步使其適應掩碼條件。
單視圖對象重建
獲得參考編輯視圖后,本文提取邊界框內生成對象的 2D 視圖並構建其 3D 重建。本文建議利用最新的單視圖對象重建範式,即使用 3D 感知擴散模型。此類重建方法通常在大規模 3D 形狀數據集(例如 Objaverse )上進行訓練,因此包含對 3D 對象的幾何形狀和外觀的強大先驗。
本文使用最近提出的 SyncDreamer 進行對象重建,它在重建質量和效率之間提供了良好的權衡。
實驗
該研究在 MipNeRF-360 和 Instruct-NeRF2NeRF 數據集上進行了評估。
此外,該研究還將 InseRF 與基線方法進行了比較,包括 Instruct-NeRF2NeRF (I-N2N) 、 Multi-View Inpainting (MV-Inpainting) 。
為了評估 InseRF 生成插入對象的能力,該研究在圖 3 中提供了將 InseRF 應用於不同 3D 場景的可視化示例。如圖所示,InseRF 可以在場景中插入 3D 一致的對象。值得注意的是,InseRF 能夠在不同表面上插入對象,這在缺乏精確 3D 放置信息的情況下是一項具有挑戰性的任務。

圖 4 是與基線方法的比較。由結果可知,使用 I-N2N 會導致場景中的全局更改,並且這種改變是更改現有對象而不是創建新對象,例如 I-N2N 把 4a 中的樂高卡車變成了一個馬克杯,把 4b 中廚房櫃檯上的物品變成了一個餐盤。
