所有語言











分享
Stability AI發布Stable Code 3B模型,沒有GPU也能本地運行
巴比特_机器之心467天前
Stable Code 3B 的性能優於類似大小的代碼模型,並且與 CodeLLaMA 7B 的性能相當,儘管其大小隻有 CodeLLaMA 7B 的 40%。
原文來源:機器之心

圖片來源:由無界 AI生成
在文生圖領域大火的 Stability AI,今天宣布了其 2024 年的第一個新 AI 模型:Stable Code 3B。顧名思義,Stable Code 3B 是一個擁有 30 億參數的模型,專註於輔助代碼任務。
無需專用 GPU 即可在筆記本電腦上本地運行,同時仍可提供與 Meta 的 CodeLLaMA 7B 等大型模型具有競爭力的性能。
2023 年底,Stability AI 便開始推動更小、更緊湊、更強大模型的發展,比如用於文本生成的 StableLM Zephyr 3B 模型。
隨着 2024 年的到來,Stability AI 開年便馬不停蹄的發布 2024 年第一個大型語言模型 Stable Code 3B,其實這個模型早在去年八月就發布了預覽版 Stable Code Alpha 3B,此後 Stability AI 一直在穩步改進該技術。新版的 Stable Code 3B 專為代碼補全而設計,具有多種附加功能。
與 CodeLLaMA 7b 相比,Stable Code 3B 大小縮小了 60%,但在編程任務上達到了與前者相媲美的性能。
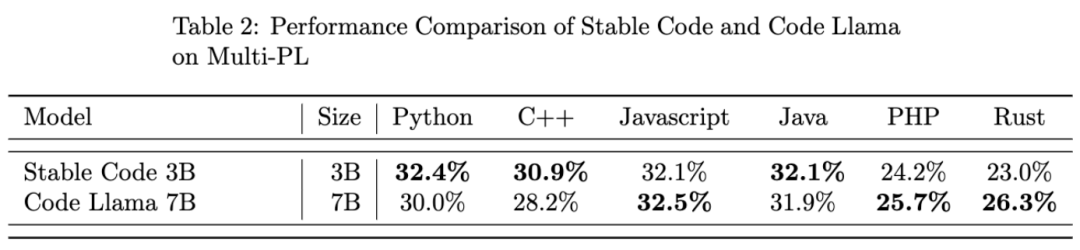
Stable Code 3B 在 MultiPL-E 基準上實現了 SOTA 性能(與類似大小的模型相比),例如 Stable Code 3B 在 Python、C++、JavaScript、Java、PHP 和 Rust 編程語言上的性能優於 StarCoder。
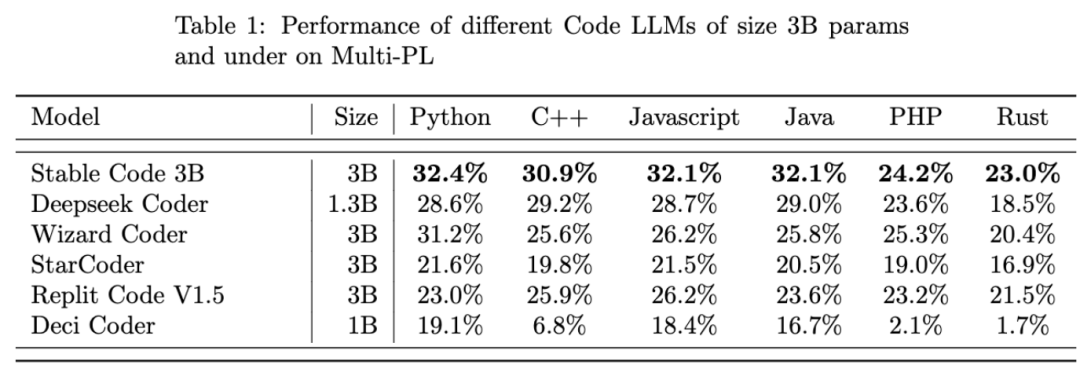
研究介紹
Stable Code 3B 基於 Stable LM 3B 訓練而成,而 Stable LM 3B 訓練 token 數達到 4 萬億,更進一步的,Stable Code 使用了軟件工程中特定的數據(包括代碼)進行訓練。
Stable Code 3B 提供了更多的特性,即使跨多種語言也表現良好,還兼具其他優勢,比如支持 FIM(Fill in the Middle ,一種新的訓練技巧)功能,還能擴展上下文大小。基礎 Stable Code 在多達 16,384 個 token 序列上進行訓練,遵循與 CodeLlama 類似的方法,即採用旋轉嵌入(Rotary Embeddings),這種方法可以選擇性的允許修改多達 1,000,000 個旋轉基(rotary base),進一步將模型的上下文長度擴展到 100k 個 token。
在模型架構方面,Stable Code 3B 模型是一個純解碼器的 transformer,類似於 LLaMA 架構,並進行了以下修改:

- 位置嵌入:旋轉位置嵌入應用於頭嵌入維度的前 25%,以提高吞吐量;
- Tokenizer:使用 GPTNeoX Tokenizer.NeoX 的修改版本,添加特殊 token 來訓練 FIM 功能,例如 < FIM_PREFIX>、 等。
訓練
訓練數據集
Stable Code 3B 的訓練數據集由 HuggingFace Hub 上提供的開源大規模數據集過濾混合組成,包括 Falcon RefinedWeb、CommitPackFT、Github Issues、StarCoder,並進一步用數學領域的數據補充訓練。
訓練基礎設施
- 硬件:Stable Code 3B 在 Stability AI 集群上使用 256 個 NVIDIA A100 40GB GPU 進行訓練。
- 軟件:Stable Code 3B 採用 gpt-neox 的分支,使用 ZeRO-1 在 2D 并行性(數據和張量并行)下進行訓練,並依賴 flash-attention、SwiGLU、FlashAttention-2 的旋轉嵌入內核。
最後,我們看一下 Stable Code 3B 的性能表現:
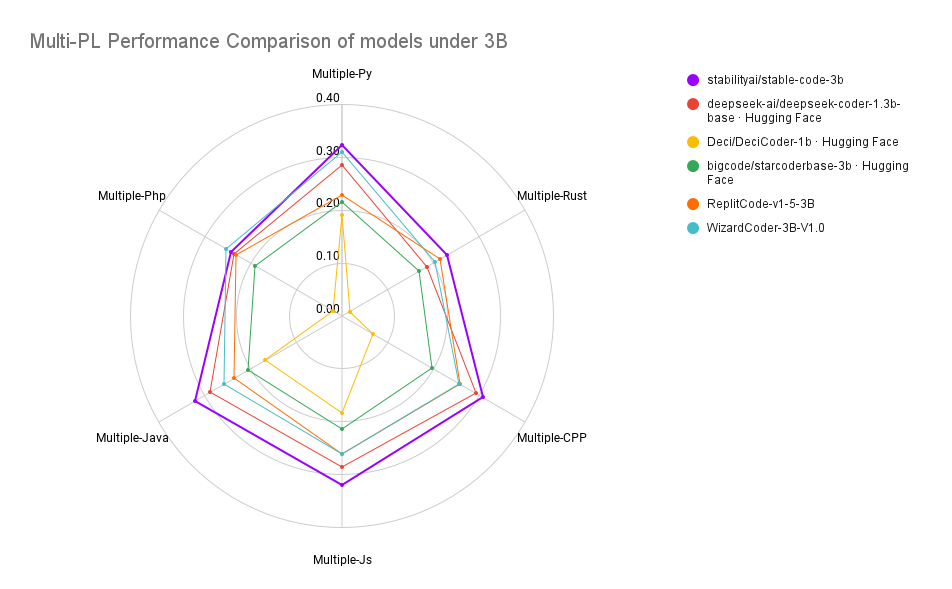
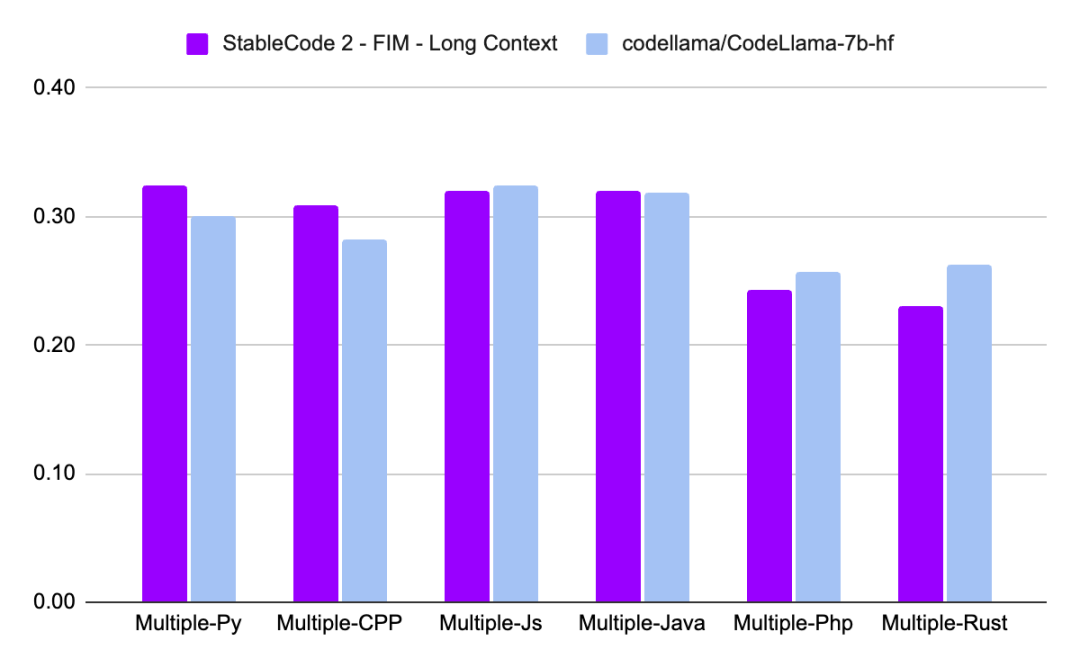
關於 Stable Code 3B 更詳細的技術報告會在之後發布,大家可以期待一下。
參考鏈接:https://stability.ai/news/stable-code-2024-llm-code-completion-release?continueFlag=ff896a31a2a10ab7986ed14bb65d25ea