所有語言











分享
效果超越Gen-2!字節最新視頻生成模型,一句話讓綠巨人戴上VR眼鏡
巴比特_AIGC465天前
原文來源:量子位

圖片來源:由無界 AI生成
一句話,就讓綠巨人戴上VR眼鏡。
4K畫質那種。

熊貓的奇幻漂流~

這是字節最新的AI視頻生成模型MagicVideo-V2,各種奇思妙想的想法都能實現。它不僅支持4K、8K超高分辨率,輕鬆hold各種繪圖風格。

△從左往右:油畫風、賽博風、設計風
測評效果超過Gen-2、Pika以及現有AI視頻生成工具。
結果上線不到24小時就引發眾人圍觀,比如一條推文就有近20萬瀏覽量。
不少網友驚訝其效果,甚至直言:比runway和pika還要好。
“比runway和pika還要好”
研究人員也的確進行了實際的效果比較。选手分別為:MagicVideo-V2、StabilityAI的SVD-XT,新潛力玩家Pika1.0,以及Runway的Gen-2。
第一輪:光影效果。
夕陽西下,旅行者獨自行走在迷霧森林中。

(從左到右依次是:MagicVideo-V2、SVD-XT,右上Pika,右下Gen-2,下同)
可以看到,MagicVideo-V2、Gen-2和Pika都有明顯的光影。不過Pika看不出是為旅行者,MagicVideo-V2的色調更為豐富。
第二輪:情境劇情的表達。
1910 年代的情景喜劇,講述社會中的日常生活和瑣事

這一輪明顯也是MagicVideo-V2、Gen-2更勝一籌。SVD-XT呈現的中景構圖,雖然年代體現出來了,但表達不夠。
第三輪:寫實。
小男孩在公園的小路上騎着自行車,車輪踩在碎石上發出嘎吱嘎吱的聲音.

這次對比就更為明顯了。MagicVideo-V2和SVD-XT是完整體現出句子意思的,不過MagicVideo-V2可以看到小孩明顯腳在動的細節。
除此之外,研究人員還將MagicVideo-V2與當下最先方法進行一對一的人類評估。
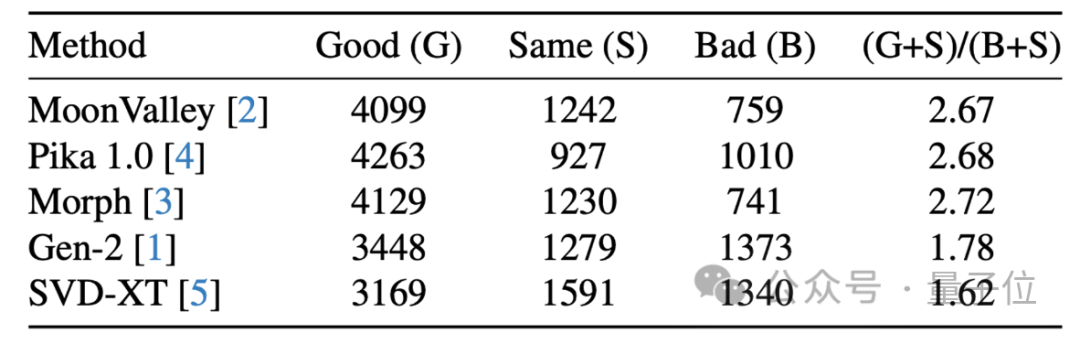
結果显示,相較於其他方法,人們認為MagicVideo-V2的效果更好。
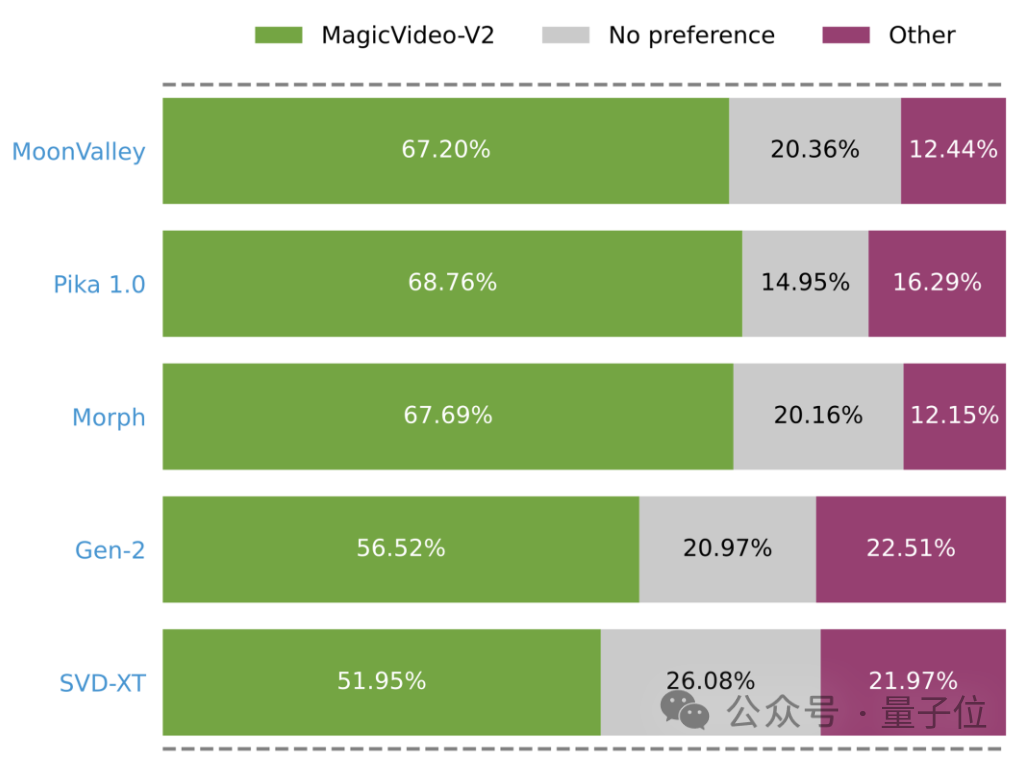
(綠色、灰色和粉色條分別代表 MagicVideo-V2 被評價為更好、相當或較差的試驗效果。)
如何實現?
簡單來說,MagicVideo-V2是一條視頻生成流水線,集成了文本到圖像模型、視頻運動生成器、參考圖像嵌入模塊、插值模塊。
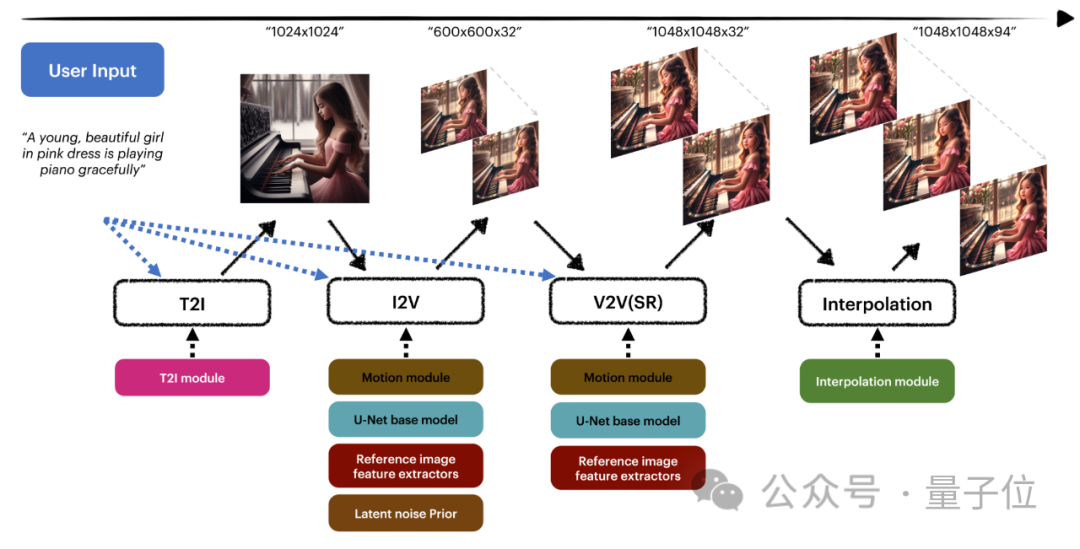
首先是有T2I模塊首先根據文字生成1024×1024圖像,隨後I2V模塊對該靜態圖像進行動畫處理,生成600×600×32的幀序列,然後再用V2V模塊增強,並完善視頻內容,最後再用插值模塊將序列擴展到94個幀。
這樣一來,既保證了高保真,時間上也有連續性。
不過早在2022年11月字節曾推出了MagicVideo V1版。


不過,當時更強調的是高效性,它能在單個GPU卡上生成256x256分辨率的視頻。
參考鏈接:
https://twitter.com/arankomatsuzaki/status/1744918551415443768?s=20
項目鏈接:
https://magicvideov2.github.io/
論文鏈接:
https://arxiv.org/abs/2401.04468
https://arxiv.org/abs/2211.11018