所有語言











分享
蘋果的封閉生態為大模型打開!發布開源多模態大模型、每天為AI燒百萬美元,零碎的Android 生態打得過嗎?
巴比特_AI之势481天前
原文來源:元宇宙新聲

圖片來源:由無界 AI生成
“蘋果公司在 LLM 方面一直表現不佳,但他們一直在不斷髮展‘硬件 + 軟件人工智能’堆棧,沒有太多耀眼的廣告。我認為,如果新的 iOS 版本突然讓 OpenAI/Bard 聊天框看起來可笑地過時,他們可能會擊敗微軟 /OpenAI 和谷歌。如果大量人工智能使用轉向蘋果硬件,它們也會對英偉達構成威脅,Arm 和台積電將獲勝。”有網友說到蘋果在大模型發展上的狀況。
也有網友認為,蘋果在大模型上的發力將為其在未來的手機市場競爭中帶來優勢。他們認為,開源模型加上移動設備的本地數據,即本地化的原生 LLM,才是關鍵,誰在設備上運行得好,誰就賣得好。具體來說,iPhone/iPad/Mac 擁有最多、最一致的本地數據生態,許多開源大模型已經可以在 iPhone 上運行,社區也對 M1/M2/M3 芯片進行了大量優化。而反觀 Android 生態,情況卻不容樂觀:三星佔據了大部分市場份額,國內五大廠商也佔據了相當大的份額,谷歌所佔份額極少,碎片化的局面讓通用模型運行面臨困難。
相比微軟等其他巨頭在大模型上的高歌猛進,蘋果顯得很是安靜,尤其蘋果和哥倫比亞大學的研究人員於在 2023 年 10 月低調發布的一個名為 Ferret 的開源多模態大模型也沒有收到太多關注。當時,該版本包含代碼和權重,但僅供研究使用,而非商業許可。
但隨着 Mistral 開源模型備受關注、谷歌 Gemini 即將應用於 Pixel Pro 和 Android,關於本地大模型為小型設備提供支持的討論越來越多。而蘋果公司也宣布啦在 iPhone 上部署大模型方面取得了重大突破:該公司發布了兩篇新的研究論文,介紹了 3D 頭像和高效語言模型推理的新技術,被認為可能帶來更身臨其境的視覺體驗,並允許複雜的人工智能系統在 iPhone 和 iPad 等消費設備上運行。
AI 社區中的許多人後來才注意到 Ferret 的發布,他們很開心蘋果公司出人意料地進入了開源 LLM 領域,因為蘋果公司歷來由於封閉的生態而被稱為“圍牆花園”。下面我們看下這個才開始被熱議的項目。
多模態大語言模型 Ferret
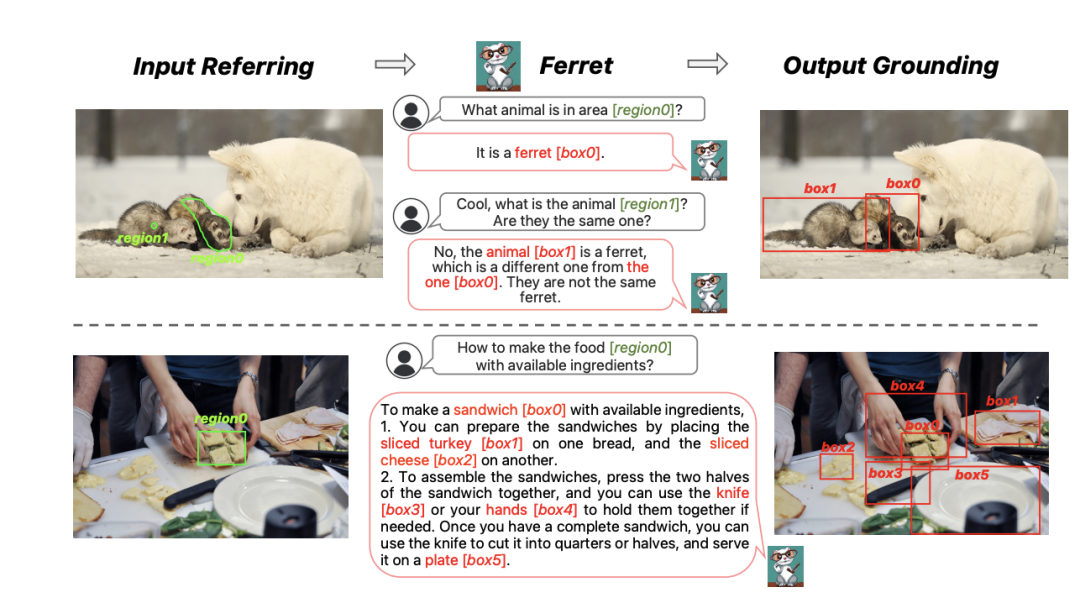
“據我們所知,Ferret 是首個能夠在多模態大模型中處理自由形式區域輸入的成果。”項目研發團隊在論文中寫道。Ferret 是一種新穎的引用與定位多模態大語言模型(MLLM)。之所以選擇多模態大模型作為 Ferret 的設計前提,是因為其擁有強大的視覺語言全局理解能力。
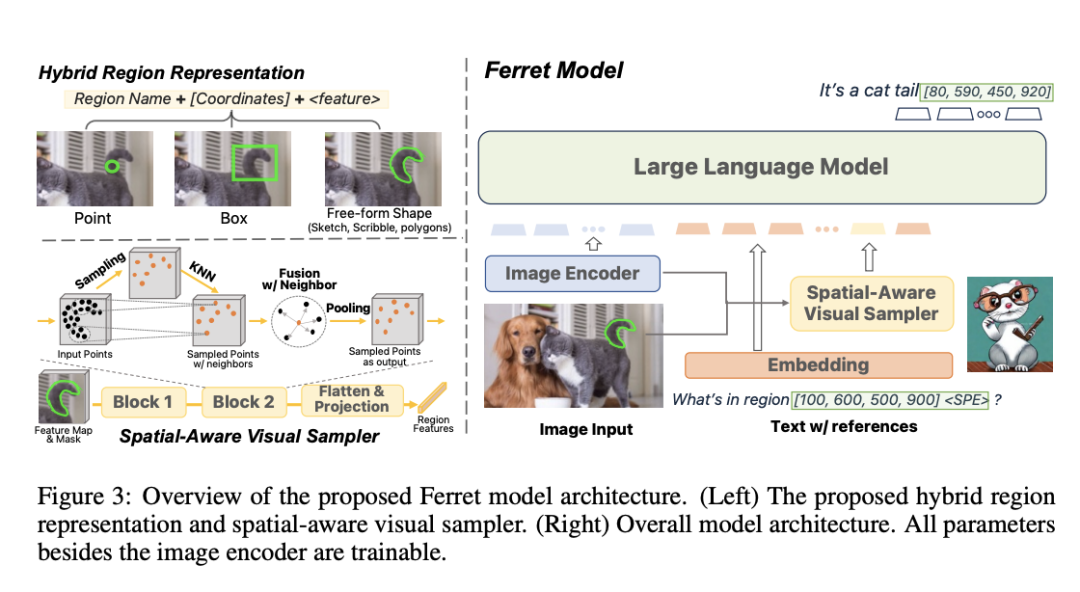
模型架構
根據介紹,Ferret 主要由用於提取圖像嵌入的圖像編碼器;用於提取區域連續特徵的空間感知視覺採樣器;以及用於對圖像、文本和區域特徵進行聯合建模的大語言模型組成。
輸入
將圖像輸入經過預訓練的視覺編碼器 CLIP-ViT-L/14 ,以提取圖像嵌入 Z ∈ R H×W×C。對於文本輸入,使用經過預訓練的大模型標記器對文本序列進行標記,並將其投射至文本嵌入 T ∈ R L×D 當中。
空間感知視覺採樣器
除了常見的點或矩形框之外,團隊需要處理的區域形狀可能存在很大差異。基於網格的處理方法(例如卷積或 patch attention)無法處理不規則形狀。與之類似,3D 點雲也屬於不規則形狀,而且在 3D 空間中表現出不同的稀疏性。受到現有 3D 點雲學習方法的啟發,團隊提出一種空間感知視覺採樣器。
空間感知視覺採樣器用以獲取任意形狀區域的視覺特徵,同時考慮到這些形狀所對應的不同稀疏性。以此為基礎,團隊將離散坐標與連續視覺特徵組合起來以表示輸入中的視覺區域,由此構成 Ferret 中的混合區域表示。憑藉上述方法,Ferret 就能夠處理由區域同自由格式文本混合而成的輸入,並可以無縫生成每個可定位對象的坐標和文本,由此在輸出中定位所提及的對象。
假設已經給定提取得出的圖像特徵圖 Z ∈ R H×W×C 和二值化區域掩模 M,團隊首先在 M 內隨機採樣 N 個正點。這 N 個點被輸入至級聯的塊中,每個塊包含三個步驟:採樣、收集、池化。經過這三個步驟,將獲得更少的點和更密集的特徵空間。
輸出
在 Ferret 的輸出中,為了實現定位,團隊在文本響應中的相應區域 / 名詞之後生成框坐標。例如“圖中有一隻狗 [100,150,300,200]。”通過這種數據格式,模型即可隱式學習當前圖像中的可定位內容及其確切位置。
大語言模型
團隊選定 Vicuna 作為語言模型,這是一種在 Llama 之上通過指令微調而來的純解碼器大語言模型。在輸入大模型之前,圖像嵌入先通過額外的線性層進行轉換,以匹配文本標記的嵌入維度。
為了使 Ferret 的引用機制具有開放詞彙、指令遵循和健壯性,團隊還整理出了一套包含 110 萬個樣本的引用與引用指令調整數據集 GRIT。
GRIT 中包含多個層次的空間知識,涵蓋對象、關係、區域描述和複雜推理等要素。GRIT 包含三種數據類型:被轉換為指認遵循格式的公共數據集、通過 ChatGPT 和 GPT-4 生成的指令微調數據和額外的空間負樣本數據。其中大部分數據是由現有視覺(語言)任務轉換而來,例如對象檢測和短語定位。
此外,團隊表示,通過 ChatGPT/GPT-4 收集的 34000 條引用和定位指令調整對話,可以高效完成模型的指令遵循與開放詞彙引用 / 定位訓練。團隊還進行了空間感知的負樣本挖掘,進一步提高了模型的健壯性。
幻覺問題
團隊也觀察到了多模態大模型在回答是 / 否類問題時,往往表現出產生“幻覺”。對此,團隊通過圖像條件類別定位以及語義條件類別定位兩種方式進行負樣本挖掘。
這兩種方式都要求模型定位特定的對象類別,從而使模型能夠辨別並潛在發現某些對象的缺失。不同之處在於,如何選擇負樣本類別。對於前者,團隊採用 Object365 數據從給定圖像中未显示的詞彙中隨機選擇對象類,對後者則使用 Flickr30k 數據,並通過 ChatGPT/GPT-4 查找與原始類別、屬性或數量最相似的實體以獲取負樣本,例如“男人”和“女人”、“藍色”和“黃色”。
此外,團隊還進行了數據整理,以維持兩種類別下正樣本和負樣本之間的平衡,最終共收集到 95000 條數據。
大模型響應
除了通過模板轉換現有數據集之外,對話指令調整數據同樣在幫助多模態大模型理解人類意圖,並生成流暢、自然、長格式響應方面至關重要。目前,業界廣泛使用少樣本提示以獲取視覺指令調整數據,其中將圖像的文本場景描述與人工標註對話作為少樣本演示,並通過提示詞要求 ChatGPT/GPT-4 根據新圖像的文本場景生成相應的對話描述。
但是,以往的指令調整數據主要集中於描述整體圖像,而不會明確指定空間相關信息。為了收集引用與定位指令調整數據,團隊通過以下三個步驟強調基於區域的空間知識:
- 除了像以往那樣使用對象與全局標題之外,其符號場景描述還包含對象與區域標題間的物理關係以及相應坐標。
- 在人工標註的對話中,團隊在輸入 / 輸出 / 二者兼具的可定位區域或對象之後添加坐標,且對話通常集中於特定區域,有助於隱式提示 ChatGPT/GPT-4 在生成新對話時遵循類似的模式。
- 實際生成的對話有時無法遵循在系統提示和少樣本示例中編寫的規則和模式,這可能是由於大語言模型輸入中的上下文太長,導致無法處理所有細節。為此,團隊建議重複使用 ChatGPT/GPT-4 來簡化最初生成的對話,其平均上下文長度僅為首輪生成數據的 10%。另外,為了節約成本,團隊僅在首輪生成中使用 ChatGPT,而後使用 GPT-4 進行簡寫提煉,最終共收集到 34000 條對話。
訓練過程
對於訓練過程,團隊使用 CLIP-ViT-L/14@336p 對圖像編碼器進行初始化,使用 Vicuna 對大模型進行初始化,使用 LlaVA 的第一階段權重對投射層進行初始化,藉此實現了視覺採樣器的隨機初始化。初始化完成后,Ferret 在 GRIT 數據上接受了三個輪次(epoch)的訓練,使用 Loshchilov & Hutter 進行優化,學習率為 2e − 5,批量大小為 128。
根據介紹,Ferret-13B/7B 模型在 8 張 A100 上的訓練分別需要約 5/2.5 天。在訓練過程中,當輸入引用區域時,團隊會隨機選擇中心點或邊界框(在可行時也會選擇分割掩膜)來表示各區域,並對訓練數據進行了重複數據刪除,藉此清理下游評估中的樣本。
為了評估這項新功能,團隊引入了 Ferret-Bench,其涵蓋三種新型任務:引用描述 / 引用推理和對話內定位。團隊表示,通過對現有多模態大模型進行了基準測試,發現 Ferret 的平均性能較最出色的原有大模型高 20.4%,而且在物體識別的幻覺方面也有所減輕。
概括來講,Ferret 項目論文的貢獻主要為以下三個方面:
- 提出了 Ferret 模型,其採用基於新型空間感知視覺採樣器的混合區域表示方法,可在多模態大模型中實現細粒度和開放詞彙的引用和定位功能。
- 建立起 GRIT,一套大規模定位與引用指令調整數據集,既可用於模型訓練,還包含額外的空間負樣本以增強模型健壯性。
- 引入了 Ferret-Bench 來評估涉及引用 / 定位、語義、知識和推理的聯合任務。
結束語
很明顯,蘋果正在努力追趕這次 AIGC 浪潮。據報道,蘋果每天在人工智能上投資數百萬美元,內部有多個團隊開發多種人工智能模型。
根據報道,蘋果致力於對話式人工智能的部門被稱為“Foundational Models”,“大約 16 名”成員,其中包括幾名前谷歌工程師。該部門由 Apple 人工智能主管 John Giannandrea 掌舵,他於 2018 年受聘幫助改進 Siri。
蘋果正在開發自己的大模型“Ajax”。Ajax 旨在與 OpenAI 的 GPT-3 和 GPT-4 等產品相媲美,可運行 2000 億個參數。Ajax 在內部被稱為“Apple GPT”,旨在統一整個 Apple 的機器學習開發,提出了將人工智能更深入地集成到 Apple 生態系統中的更廣泛戰略。
截至最新報告,Ajax 被認為比上一代 ChatGPT 3.5 更強大。然而,也有人認為,截至 2023 年 9 月,OpenAI 的新模型可能已經超越了 Ajax 的能力。
近日,蘋果的機器學習研究團隊還悄悄發布了一個名為 MLX 的框架來構建基礎模型。彭博社報道稱,蘋果正在開發 Siri 的改進版本,並計劃在下一個重大 iOS 版本中提供以人工智能為中心的功能。
另外,蘋果還正在與一些大型新聞出版商洽談授權其新聞檔案,並利用這些信息來訓練模型。《紐約時報》稱,該公司正在討論“價值至少 5000 萬美元的多年期交易” ,並已與 Condé Nast、NBC News 和 IAC 等出版商保持聯繫。
相關鏈接:
https://arxiv.org/pdf/2310.07704.pdf
https://www.macrumors.com/2023/12/21/apple-ai-researchers-run-llms-iphones/
https://www.theverge.com/2023/12/22/24012730/apple-ai-models-news-publishers