所有語言











分享
Radical Ventures 合伙人 Rob Toews:2024 年的 10 項人工智能預測
巴比特_Yangz488天前
來源:福布斯
作者:Radical Ventures 合伙人Rob Toews

圖片來源:由無界 AI生成
1. 英偉達將加大力度成為雲計算供應商
大多數企業並會不直接向英偉達購買 GPU。相反,他們通過亞馬遜網絡服務(Amazon Web Services)、微軟 Azure 和谷歌雲平台(Google Cloud Platform)等雲服務提供商獲得 GPU,而這些雲服務提供商又會從英偉達大量購買芯片。
但亞馬遜、微軟和谷歌 -- 英偉達的最大客戶 -- 正迅速成為其競爭對手。在認識到當今人工智能的價值主要來自硅層后(Nvidia 的股價就是最好的證明),主要雲提供商都在投入巨資開發自己的原生人工智能芯片,這將與英偉達 GPU 直接競爭。
隨着雲計算提供商希望將技術堆棧下移到硅層以獲取更多價值,英偉達朝相反的方向發展也不就顯得不那麼驚訝了。英偉達將提供自己的雲服務並運營自己的數據中心,以減少傳統上對雲計算公司的分銷依賴。
英偉達已經開始探索這條道路,今年早些時候推出了名為 DGX Cloud 的新雲服務。我們預測,該公司將在明年切實加強這一戰略。
為實現這一目標,英偉達預計將建立自己的數據中心(DGX Cloud 目前位於其他雲提供商的物理基礎設施中);甚至可能需要收購像 CoreWeave 這樣的新興雲提供商(英偉達已與 CoreWeave 建立了緊密的合作夥伴關係),以此實現垂直整合。無論如何,預計進入 2024 年後,英偉達與大型雲計算提供商之間的關係將變得更加複雜。
2. Stability AI 將倒閉
這是人工智能界最不為人知的秘密之一:曾經高歌猛進的初創公司 Stability AI 在 2023 年的大部分時間里就是一列緩慢前行的火車殘骸。
Stability 正在大失血。最近幾個月離職的包括公司的首席運營官、首席人事官、工程副總裁、產品副總裁、應用機器學習副總裁、通信副總裁、研究主管、音頻主管和法律總顧問。
據報道,由於與 Stability 首席執行官 Emad Mostaque 發生爭執,去年領導 Stability 高調完成 1 億美元融資的兩家公司 Coatue 和 Lightspeed 近幾個月都退出了公司董事會。今年早些時候,該公司曾試圖以 40 億美元的估值籌集更多資金,但以失敗告終。
2024 年,我們預測這家陷入困境的公司將在越來越大的壓力下屈服,徹底倒閉。
據報道,迫於投資者的壓力,Stability 已開始尋找收購方,但迄今為止幾乎感興趣的收購方並不多。
Stability 的一個有利條件是:公司最近從英特爾那裡融資了 5000 萬美元,這筆現金注入將延長該公司的運營時間。就英特爾而言,這筆投資似乎反映出其迫切希望獲得高知名度客戶對其新型人工智能芯片的支持,以在與英偉達的競爭中佔據優勢。
但 Stability 的燒錢速度之快是出了名的:據報道,在 10 月份英特爾投資 Stability 時,Stability 的月支出為 800 萬美元,而帶來的收入僅為該數據的一小部分。按照這個速度,5000 萬美元的投資撐不到 2024 年底。
3.“大型語言模型”和“LLM”這兩個術語將不再常見
在當今的人工智能領域,“大型語言模型”(及其縮寫 LLM)經常被用作“任何高級人工智能模型”的簡稱。這是可以理解的,因為許多最初崛起的生成式人工智能模型(如 GPT-3)都是純文本模型。
但是,隨着人工智能模型類型的增加,以及人工智能變得越來越多模態化,這個術語將變得越來越不準確。多模態人工智能的出現是 2023 年人工智能的決定性主題之一。當今許多領先的生成式人工智能模型都結合了文本、圖像、三維、音頻、視頻、音樂、肢體動作等等。它們遠不止是語言模型。
試想看一個人工智能模型,它可以根據已知蛋白質的氨基酸序列和分子結構進行訓練,以生成全新的蛋白質療法。雖然其底層架構是 GPT-3 等模型的延伸,但將其稱為大型語言模型真的有意義嗎?
或者想一下機器人學中的基礎模型:大型生成模型將視覺和語言輸入與一般互聯網知識相結合,以便在現實世界中採取行動,例如通過机械臂。對於這類模型,應該而且將會有一個比“語言模型”更豐富的術語。(“視覺 - 語言 - 行動”模型或 VLA 模型是研究人員使用的另一種說法)。
DeepMind 最近發布的 FunSearch 模型也有類似的意思,作者自己稱其為 LLM,但它涉及的是數學而非自然語言。
2024 年,隨着我們的模型變得越來越多維,我們用來描述它們的術語也將越來越多維。
4. 最先進的封閉模型將繼續大幅超越最先進的開放模型
當今人工智能討論的一個重要話題是圍繞開源和閉源人工智能模型的爭論。雖然大多數尖端人工智能模型開發商 --OpenAI、谷歌 DeepMind、Anthropic、Cohere 等公司 -- 都將其最先進的模型作為專利,但包括 Meta 和熱門初創公司 Mistral 在內的少數幾家公司卻選擇公開其最先進的模型權重。
如今,性能最高的基礎模型(如 OpenAI 的 GPT-4)都是閉源的。但許多開源倡導者認為,封閉模型與開放模型之間的性能差距正在縮小,而且開放模型有望在性能上超越封閉模型,或許到明年就能實現。(這張圖最近在網上瘋傳)。
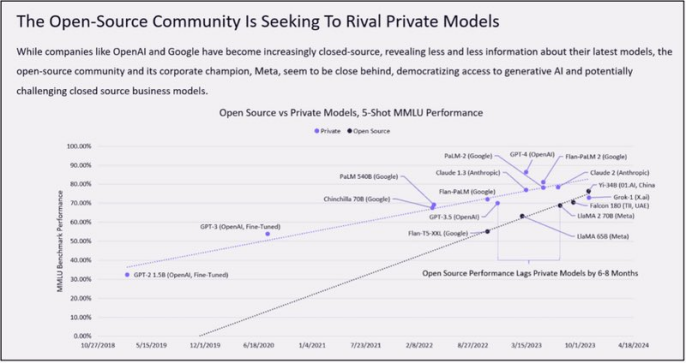
我們不同意這一觀點。我們預測,最好的封閉式模型在 2024 年(及以後)將繼續明顯優於最好的開源模型。
基礎模型的性能是一個快速發展的前沿領域。Mistral 最近誇口說,它將在 2024 年的某個時候開源 GPT-4 級模型,這一說法在開源社區引起了轟動。但 OpenAI 在 2023 年初就發布了 GPT-4。等到 Mistral 推出這個新模型時,很可能已經落後一年多了。屆時,OpenAI 很可能已經發布了 GPT-4.5,甚至 GPT-5,從而開創一個全新的性能領域。(有傳言稱,GPT-4.5 甚至可能在 2023 年底前發布)。
與許多其他領域一樣,在另一個團體確定了前沿之後,作為快速追隨者趕上前沿,要比在其他人證明這是可能的之前建立一個新的前沿更容易實現。例如,OpenAI 使用專家混合架構構建 GPT-4 的風險、挑戰和成本都要比 Mistral 在幾個月後用自己的專家混合模型追隨 OpenAI 的腳步要高得多,因為在此之前,這種方法還沒有被證明能在這種規模下起效。
有一個基本的結構性原因讓人遲疑,開放模型的性能是否會在 2024 年超越封閉模型。開發一個能推動技術發展的新模型所需的投資是巨大的,而且隨着模型能力的每一步提升,投資只會繼續膨脹。一些行業觀察家估計,OpenAI 將花費約 20 億美元來開發 GPT-5。
Meta 作為一家上市公司,最終要對股東負責。該公司似乎並不指望從其發布的開源模型中獲得任何直接收入。據報道,Llama 2 的製造成本約為 2000 萬美元;考慮到戰略利益,即使沒有任何相關的收入增長,這樣的投資水平也是合理的。但是,Meta 真的打算投入近 20 億美元來打造一個性能超越其他任何公司的人工智能模型,而僅僅是為了開源而不期獲得任何具體的投資回報嗎?
當然了,像 Mistral 這樣的後起之秀也面臨着類似的難題。開源基礎模型並沒有明確的收入模式(Stability AI 就有過這樣的慘痛教訓)。例如,對託管開源模型收費,就成了一場價格競爭,正如我們最近在 Mistral 的新 Mixtral 模型中看到的那樣。那麼 -- 即使 Mistral 能夠獲得所需的數十億美元來構建一種新模式,從而超越 OpenAI-- 它真的會選擇轉過身來免費贈送這種模式嗎?
對此,我們隱隱懷疑,隨着 Mistral 這樣的公司投入越來越多的資金來構建更強大的人工智能模型,他們最終可能會轉變對開源的態度,將最先進的模型保留為專有,以便收費。
(要明確的是:這並不是在反對開源人工智能的優點。這並不是說開源人工智能在未來的人工智能世界中將不再重要。恰恰相反,我們預計開源模型將在未來幾年人工智能的普及中發揮關鍵作用。但是:我們預測,最先進的人工智能系統,那些能夠推動人工智能發展的前沿系統,將繼續是專有的。)
5. 許多財富 500 強公司將設立一個新職位:首席人工智能官。
人工智能已成為今年《財富》500 強企業的首要任務,各行各業的董事會和管理團隊都在爭先恐后地研究這項強大的新技術對企業的意義。
我們預計,明年大型企業將更普遍地採取一種策略:任命一位“首席人工智能官”來領導企業的人工智能計劃。
在十年前雲計算興起的時候,我們也看到了類似的趨勢,許多企業都聘請了“首席雲計算官”來幫助他們應對雲計算的戰略影響。
這一趨勢將在企業界獲得更多動力,因為政府部門已經出現了并行趨勢。拜登總統最近發布的人工智能行政命令要求每個聯邦政府機構任命一名首席人工智能官,這意味着未來幾個月美國政府將新聘 400 多名 CAO。
任命首席人工智能官將成為公司對外表明其對人工智能態度的一種流行方式。至於這些職位能否長期發揮價值,則是另一個問題。(想想看,如今還有多少首席雲計算官?)
6. Transformer 架構的替代方案將得到有意義的採用
Transformer 架構是谷歌在 2017 年發表的一篇開創性論文中提出的,是當今人工智能技術的主流範式。現存的每個主要生成式人工智能模型和產品 --ChatGPT、Midjourney、GitHub Copilot 等等,都是使用 Transformer 構建的。
但是,沒有哪種技術能永遠佔據主導地位。
在人工智能研究界的前沿,有幾個團體一直在努力開發新型的下一代人工智能架構,這些架構在不同方面都優於 Transformer。
Chris Ré 在斯坦福大學的實驗室就是這些努力的一個關鍵樞紐。Ré 和他的學生們的工作中心主題是建立一種新的模型架構,這種架構可隨序列長度以亞二次方的方式擴展(而不是像 Transformer 那樣以四次方的方式擴展)。亞二次方擴展將使人工智能模型:(1) 計算密集度更低;(2) 與 Transformer 相比,能更好地處理長序列。近年來,Ré 實驗室推出的著名亞二次方模型架構包括 S4、Monarch Mixer 和 Hyena。
最新的亞二次元架構 -- 或許也是最有前途的架構 -- 是 Mamba。Mamba 由 Ré 的兩位門生於上個月發表,在人工智能研究界引起了巨大反響,一些評論家將其譽為“Transformer 的終結者”。
此外,其他試圖構建 Transformer 架構替代品的努力還包括麻省理工學院開發的液態神經網絡,以及由 Transformer 聯合發明人之一領導的初創公司 Sakana AI。
2024 年,我們預測這些挑戰者架構中的一個或多個將取得突破並贏得真正的採用,從單純的研究新穎性過渡到用於生產的可靠替代人工智能方法。
需要明確的是,這並不是說 Transformer 會在 2024 年消失。它仍是一種根深蒂固的技術,世界上最重要的人工智能系統都是基於這種技術。但我們預測,在 2024 年,Transformer 的尖端替代品將成為現實世界人工智能用例的可行選擇。
7. 雲提供商對 AI 初創企業的戰略投資 -- 以及相關的會計影響 -- 將受到監管機構的質疑
今年以來,大型科技公司的投資資金如潮水般湧向人工智能初創企業。
今年 1 月,微軟向 OpenAI 投資了 100 億美元,6 月又領投了 Inflection 的 13 億美元融資。今年秋天,亞馬遜宣布將向 Anthropic 投資 40 億美元。幾周后,Alphabet 也不甘示弱,宣布將向 Anthropic 投資 20 億美元。與此同時,英偉達可能是今年全球最多產的人工智能投資者,它向數十家使用其 GPU 的人工智能初創公司投入資金,其中包括 Cohere、Inflection、Hugging Face、Mistral、CoreWeave、Inceptive、AI21 Labs 和 Imbue。
不難看出,進行這些投資的動機至少部分是為了確保這些高增長的人工智能初創公司成為其長期計算客戶。
這類投資可能會牽涉到會計規則中的一個重要灰色地帶。這聽起來可能是一個深奧的話題,但它將對未來人工智能領域的競爭格局產生巨大影響。
假設一家雲計算供應商向一家人工智能初創企業投資 1 億美元,並保證這家初創企業會將這 1 億美元用於購買雲計算供應商的服務。那麼從概念上講,這對雲廠商來說並不是真正的正常收入;實際上,廠商是在利用投資將自己資產負債表上的現金人為地轉化為收入。
這類交易通常被稱為“返程資本流入”(round-tripping:資金出去后又馬上回來),在今年引起了風投 Bill Gurley 等硅谷領袖的關注。
然而,並非上述所有交易都是真正的“round-tripping”。例如,投資是否明確要求初創企業將資金用於投資方的產品,或者只是鼓勵兩家公司開展廣泛的戰略合作,這一點很重要。微軟與 OpenAI、亞馬遜與 Anthropic 之間的合同並未公開,因此我們無法確定它們的結構。
但至少在某些情況下,雲計算提供商很可能通過這些投資獲得了本不該獲得的收入。
到目前為止,這些交易幾乎沒有受到任何監管審查。這種情況將在 2024 年發生變化。預計明年美國證券交易委員會將對人工智能投資中的返程資本流入進行更嚴厲的審查 -- 預計此類交易的數量和規模將因此大幅下降。
鑒於雲計算提供商是迄今為止推動人工智能熱潮的最大資金來源之一,這可能會對 2024 年的整體人工智能籌資環境產生重大影響。
8. 微軟與 OpenAI 的關係將開始出現裂痕
微軟和 OpenAI 關係密切。迄今為止,微軟已向 OpenAI 投入超過 100 億美元。OpenAI 的模型為必應、GitHub Copilot 和 Office 365 Copilot 等微軟關鍵產品提供了支持。上個月,OpenAI 首席執行官 Sam Altman 意外被董事會解僱,微軟首席執行官 Satya Nadella 在讓他復職方面發揮了重要作用。
然而,微軟和 OpenAI 是不同的組織,對人工智能的未來有着不同的願景。迄今為止,這一聯盟對兩個組織都很有利,但這隻是權宜之計。這兩個組織遠非完全一致。
明年,我們預測這兩大巨頭之間的合作關係將開始出現裂痕。事實上,未來摩擦的蛛絲馬跡已經開始浮出水面。
隨着 OpenAI 积極拓展企業業務,它將發現自己越來越經常地與微軟直接爭奪客戶。就微軟而言,除了將 OpenAI 作為尖端人工智能模型的供應商外,它還有很多理由進行多元化發展。例如,微軟最近宣布與 OpenAI 的競爭對手 Cohere 達成合作協議。面對大規模運行 OpenAI 模型的高昂成本,微軟還在 Phi-2 等小型語言模型上投入了內部人工智能研究。
從大的方面看,隨着人工智能變得越來越強大,有關人工智能安全、風險、監管和公共責任的重要問題將成為焦點。利害關係將非常重大。鑒於兩家公司不同的文化、價值觀和歷史,似乎不可避免地會在處理這些問題的理念和方法上產生分歧。
微軟市值 2.7 萬億美元,是全球第二大公司。然而,OpenAI 及其魅力四射的領導者 Sam Altman 的野心可能更加深遠。如今,這兩家公司彼此合作無間。但不要指望這會永遠持續下去。
9. 2023 年從加密圈轉向人工智能的一些炒作和從眾心理行為,將在 2024 年重新迴轉
現在很難想象風險投資家和技術領導者會對人工智能以外的東西感到興奮。但是,一年是很長的時間,風險投資人的“信念”會轉變得非常快。
Crypto 是一個周期性行業。現在的它可能有點過時,但別誤會,另一輪大牛市將會到來 -- 就像 2021 年、2017 年和 2013 年一樣。如果你還沒有注意到,比特幣的價格在今年年初低於 17000 美元后,在過去幾個月里大幅上漲,從 9 月份的 25000 美元漲到了現在的 40000 多美元。比特幣的大漲可能正在醞釀之中,如果真的如此,大量的加密活動和炒作將隨之而來。
如今將自己定位為“all in” 人工智能的許多知名風險投資家、企業家和技術專家,在 2021-2022 年的牛市期間都對加密貨幣情有獨鍾。如果明年加密資產價格真的飆升回來,預計他們中的一些人也會追隨這一方向的熱度,就像他們今年追隨人工智能的熱度一樣。
(坦率地說,如果明年能看到一些過度的人工智能炒作轉向其他領域,那將是一個值得歡迎的發展)。
10. 至少有一家美國法院將裁定,在互聯網上訓練的 AI 生成模型侵犯版權。美國最高法院將開始審理這一問題。
目前,整個生成式人工智能領域都面臨着一個被忽視的重大法律風險:世界領先的生成式人工智能模型是在大量受版權保護的內容上訓練出來的,這一事實可能會引發巨大的法律責任,並改變該行業的經濟狀況。
無論是 GPT-4 還是 Claude 2, 中的詩歌,DALL-E 3 或 Midjourney 中的圖像,還是 Pika 或 Runway 中的視頻,生成式人工智能模型都能產生令人嘆為觀止的複雜輸出,因為它們已經在世界上的大部分数字數據上接受過訓練。在大多數情況下,人工智能公司從互聯網上免費獲取這些數據,並隨意用於開發它們的模型。
但是,最初真正創造了這些知識產權的數百萬人 -- 寫書、寫詩、拍照、畫畫、拍視頻的人類 -- 對人工智能從業者是否和如何使用這些數據有發言權嗎?他們是否有權分享人工智能模型所創造的部分價值?
這些問題的答案將取決於法院對“合理使用”這一關鍵法律概念的解釋。合理使用是一項成熟的法律理論,已經存在了幾個世紀。但將其應用於新生的生成式人工智能領域,會產生複雜的新理論問題,目前沒有明確的答案。
斯坦福大學研究員 Peter Henderson 說:“機器學習領域的人們並不一定了解合理使用的細微差別,同時,法院已經裁定,現實世界中某些備受矚目的例子不屬於受保護的合理使用,但這些例子看起來就像是人工智能正在推出的東西。”“這方面的訴訟結果如何,還存在不確定性。”
那麼這些問題將如何解決?通過個案和法院裁決。
將合理使用原則應用於生成式人工智能將是一項複雜的工作,需要創造性思維和主觀判斷。問題的雙方都會有可信的論據和站得住腳的結論。
因此,如果明年至少有一家美國法院裁定,像 GPT-4 和 Midjourney 這樣的生成式人工智能模型確實侵犯了版權,並且建立這些模型的公司要對訓練這些模型的知識產權的所有者負責,請不要感到驚訝。
另外,這並不能解決問題。其他司法管轄區的其他美國法院面對不同的事實模式,很可能會得出相反的結論:生成式人工智能模型受到合理使用原則的保護。
這個問題會一直發展到美國最高法院,最終由最高法院給出一個結論性的法律解決方案。(通往美國最高法院的道路漫長而曲折;不要指望最高法院明年會就此問題做出裁決)。
在此期間,大量的訴訟將接踵而至,大量的和解將通過談判達成,世界各地的律師將忙於處理各種拼湊的判例法。數十億美元將懸而未決。