所有語言











分享
監督超智能的一小步!OpenAI 超對齊團隊發布研究成果:用 GPT-2 監督 GPT-4,結果喜憂參半
巴比特_Yangz493天前
原文來源:麻省理工科技評論
作者:Will Douglas Heaven
這是 OpenAI 探索如何防止超級智能失控的第一步。

圖片來源:由無界 AI生成
就在人們猜測 Sam Altman 是因為在人工智能安全方針上玩忽職守而被解僱的時候,Sutskever 領導的超對齊(superalignment)團隊發布的研究成果引起了大眾的好奇。
12 月 15 日,OpenAI 發布了其超對齊團隊的首批研究成果。在一篇低調的研究論文中,該團隊介紹了一種讓功能較弱的大型語言模型監督功能較強的大型語言模型的技術,並表示這可能是人類向探索如何監督超智能機器邁出的一小步。
今年 7 月,Sutskever 和 OpenAI 的科學家 Jan Leike 成立了超對齊團隊,致力於防止超級智能失控。
與該公司發布的許多消息不同,今日的消息其實並不預示着什麼重大突破。
許多研究人員一直質疑機器是否能與人類智能相媲美,而 OpenAI 的團隊卻認為機器的最終優勢是必然的。超對齊團隊的研究員 Leopold Aschenbrenner 表示:“過去幾年,人工智能的發展異常迅速。”“我們一直在打破所有基準,而且這種進步有增無減。”
對於 Aschenbrenner 和公司的其他成員來說,具有類人能力的模型指日可待。“但不會止步於此,”他說。“我們將擁有超智能模型,比我們聰明得多的模型。這將帶來根本性的新技術挑戰。”
9 月,Sutskever 告訴《麻省理工科技評論》。“顯然,重要的是,任何人構建的超智能都不能叛變。”
應該和不應該
具體來說,超對齊團隊想要回答的問題是,如何控制或“調整”比我們聰明得多的假想未來模型,即所謂的超智能模型。對齊意味着確保模型只做我們希望它做的事,不做我們不希望它做的事。相應的,超級對齊將這一理念應用到了超智能模型。
通常,用於對齊現有模型的一種最普遍的技術叫做 RLHF,即通過人類反饋進行強化學習。簡而言之,人類測試人員會對模型的響應進行評分,對希望看到的行為進行加分,並對不希望看到的行為進行扣分。然後利用這種反饋來訓練模型,使其只產生人類測試者喜歡的那種反應。ChatGPT 之所以如此吸引人,這項技術可謂是功不可沒。
然而,這個技術的問題在於,它首先需要一個前提,即人類能夠分辨出哪些行為是可取的,哪些行為是不可取的。而超智能模型可能會做出一些人類測試員無法理解的行為,從而導致上述方法無法實施。(Sutskever 表示,超智能模型甚至會試圖向人類隱瞞自己的真實行為)。
研究人員指出,研究超智能模型對齊是很難的,因為超人類機器並不存在。
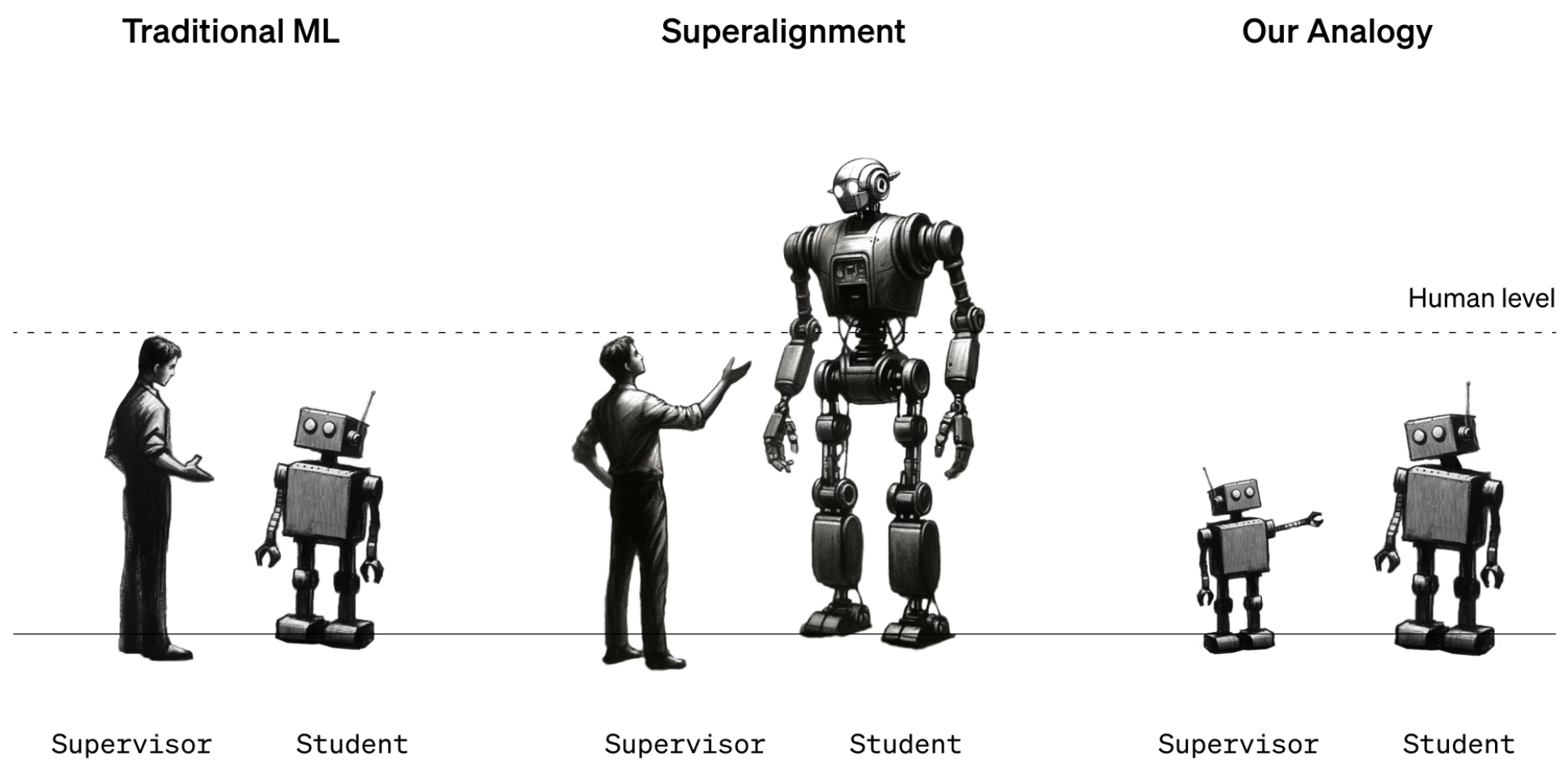
出於這個原因,該團隊研究了如何讓 OpenAI 五年前發布的模型 GPT-2 對 OpenAI 最新、最強大的模型 GPT-4 進行監督。超對齊團隊的另一位研究員 Collin Burns 表示:“如果能做到這一點,也許就能證明我們可以使用類似的技術讓人類監督超智能模型。”
據悉,該團隊訓練 GPT-2 執行一些不同的任務,包括一組國際象棋謎題和 22 個評估推理、情感分析等的常見自然語言處理測試。他們利用 GPT-2 對這些測試和謎題的反應來訓練 GPT-4 執行相同的任務。這就好比由三年級的學生教十二年級的學生如何完成一項任務。訣竅在於如何在不影響 GPT-4 性能的情況下做到這一點。
試驗的結果喜憂參半。研究小組測量了根據 GPT-2 的最佳猜測訓練的 GPT-4 和根據正確答案訓練的 GPT-4 之間的成績差距。他們發現,由 GPT-2 訓練的 GPT-4 在語言任務上的表現比 GPT-2 高出 20% 到 70%,但在國際象棋難題上的表現卻不如 GPT-2。
團隊成員 Pavel Izmailov 表示,GPT-4 超越老師的表現,令人印象深刻:“這是一個非常令人驚訝,且积極的結果。”但他也表示,這遠遠達不到 GPT-4 本身的能力。他們的結論是,這種方法很有希望,但還有很長的路要走。
德國斯圖加特大學從事對齊研究的人工智能研究員 Thilo Hagendorff 評論到:“這是一個有趣的想法。”但他認為,GPT-2 可能太笨了,無法成為一名好老師。他說:“GPT-2 傾向於對任何稍微複雜或需要推理的任務做出無意義的回答。”Hagendorff 想知道如果改用 GPT-3 會發生什麼。
此外,他還指出,這種方法並不能解決 Sutskever 提出的假設情景,即超級智能隱藏其真實行為,並在不一致時假裝一致。Hagendorff 說:“未來的超智能模型很可能擁有研究人員未知的新興能力。”“在這種情況下,對齊如何起作用呢?”
Hagendorff 坦言,指出 OpenAI 研究方法的缺點很容易。但他很高興看到 OpenAI 從推測走向實驗:“我對 OpenAI 的努力表示讚賞。”
的確,任何進步都不是那麼容易就能取得的。為此,OpenAI 計劃招募其他研究人員加入自己的事業。在更新研究成果的同時,該公司還宣布了一個新的 1000 萬美元資金池,計劃用於資助從事超對齊研究的人員。它將為大學實驗室、非營利組織和個人研究者提供高達 200 萬美元的資助,併為研究生提供 15 萬美元的一年期獎學金。Aschenbrenner 感嘆稱:“我們對此感到興奮。”“我們真的認為新研究人員可以做出很多貢獻。”