所有語言











分享
又打臉!微軟用新的提示策略證明:GPT-4 領先於 Gemini Ultra
巴比特_Yangz495天前
微軟想要強調的,也是 Gemini 發布時就已顯現出來的,是兩個模型的性能其實是相當的。

圖片來源:由無界 AI生成
簡直不講武德,繼上周推出號稱其“最新、功能最強大”的 AI 模型 Gemini 后,今日,谷歌宣布將向開發人員和組織提供 Gemini Pro 以及一系列新的人工智能工具、模型和基礎架構。
首先,Gemini Pro 可通過 Gemini API 提供給 Google AI Studio(免費的基於 Web 的開發工具)的開發人員。企業也可以通過谷歌雲的 Vertex AI 平台進行使用。此外,谷歌還將在 Vertex AI 中引入其他模型,幫助開發者和企業靈活構建和發布應用程序,包括升級版的文生圖工具 Imagen 2,以及針對醫療保健行業微調的基礎模型系列 MedLM。另外,谷歌還宣布其面向開發人員的在線協作工具 Duet AI 已全面上線。
作為對 OpenAI GPT-4 的回應,谷歌 DeepMind 稱,Gemini 的 Ultra 版本在 32 項標準性能指標中,有 30 項指標都優於 GPT-4。
然而,發布還不到一天,Gemini 就遭到了質疑,不僅測試標準有失偏頗,連效果視頻也疑似剪輯。
無獨有偶,微軟今日發文更是把谷歌的臉打的啪啪響。微軟稱,GPT-4 與特殊的提示策略相結合,在語言理解基準 MMLU(衡量大規模多任務語言理解能力)中的表現優於谷歌 Gemini Ultra。
微軟的反擊:複雜提示提高基準性能
據悉,Medprompt 是微軟最近推出的一種提示策略,最初是針對醫療挑戰而開發的。不過,微軟的研究人員發現,它也適用於更廣泛的應用。
通過使用改進版的 Medprompt 運行 GPT-4,微軟在 MMLU 基準測試中獲得了新的技術水平 (SoTA) 分數。根據報告,GPT-4 在 MMLU 中的表現達到了 90.10% 的歷史新高,超過了 Gemini Ultra 的 90.04%。
注:MMLU 基準測試是一項常識和推理的綜合測試。它包含數學、歷史、法律、計算機科學、工程和醫學等 57 個學科領域的數萬個題目。它被認為是語言模型最重要的基準。
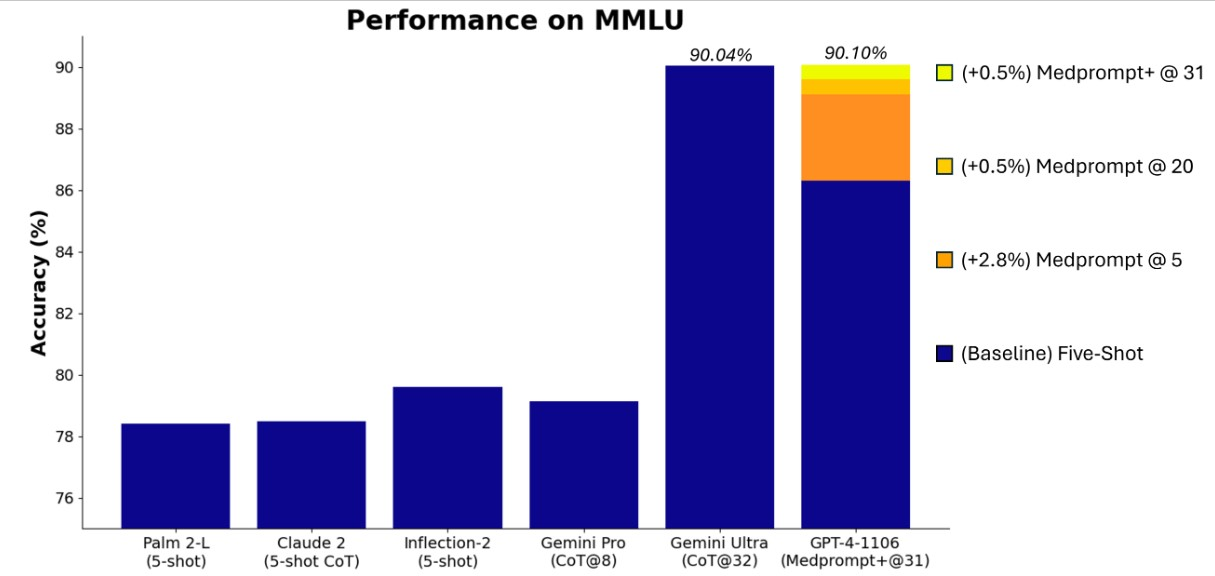
據悉,最初將原始 Medprompt 應用於 GPT-4 在綜合 MMLU 上的得分率為 89.1%。而通過將 Medprompt 中的集合調用次數從 5 次增加到 20 次,GPT-4 在 MMLU 上的表現進一步提高到 89.56%。為了達到新的 SoTA,微軟的研究人員將 Medprompt 擴展為 Medprompt+,方法是在 Medprompt 中添加一種更簡單的提示方法,並制定一種策略,將 Medprompt 基本策略和更簡單的提示方法的答案結合起來,得出最終答案。
除了 MMLU 基準測試之外,微軟還發布了其他基準測試的結果,使用這些基準測試中常見的簡單提示來显示 GPT-4 與 Gemini Ultra 的性能比較。據稱,GPT-4 在使用這種測量方法的多個基準測試中表現均優於 Gemini Ultra,包括 GSM8K、MATH、HumanEval、BIG-Bench-Hard、DROP 和 HellaSwag。
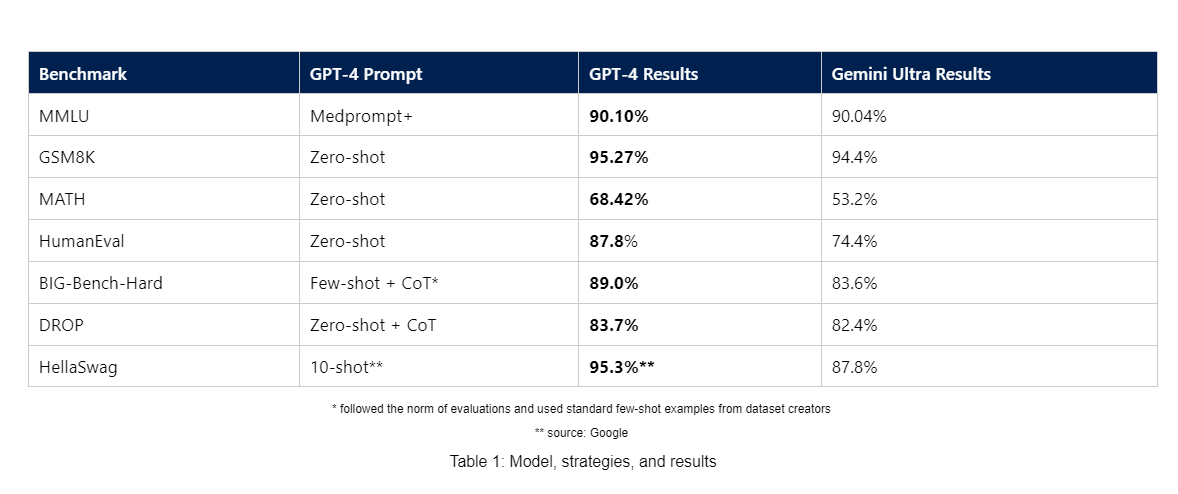
微軟表示,雖然系統化的提示工程可以產生最高性能,但其仍在探索使用簡單提示的前沿模型開箱即用性能。微軟稱,重要的是,要關注 GPT-4 的原生功能,以及如何利用零次或少量提示策略引導模型。如上圖所示,在採用更複雜、更昂貴的方法之前,從簡單的提示開始有助於建立基線性能。
據悉,微軟已在名為 Promptbase 的 GitHub 中發布了 Medprompt 和類似的提示策略,包含腳本、通用工具和信息,可幫助重現上述測試結果。
需要留意的是,在實際應用中,這些基準中的微小差異可能不會有太大影響,畢竟它的目的是用來公關的。微軟想要強調的,也是在 Gemini Ultra 發布時就已經顯現出來的,是兩個模型的性能其實是相當的。
可能正如比爾·蓋茨最近所說的那樣,當前形式的 LLM 技術已經達到了極限。或許要等到 GPT-4.5 或 GPT-5 的出現,才有可能迎來下一波浪潮。
參考鏈接: