所有語言











分享
2.7B能打Llama 2 70B,微軟祭出「小語言模型」!96塊A100 14天訓出Phi-2,碾壓谷歌Gemini nano
巴比特_AI梦工厂494天前
文章來源:新智元
都快到年底了,大模型領域還在卷,今天,Microsoft發布了參數量為2.7B的Phi-2——不僅13B參數以內沒有對手,甚至還能和Llama 70B掰手腕!

圖片來源:由無界 AI生成
大模型現在真的是越來越卷了!
11月OpenAI先是用GPTs革了套殼GPT們的命,然後再不惜獻祭董事會搏了一波天大的流量。
谷歌被逼急了,趕在年底之前倉促發布了超大模型Gemini,捲起了多模態,甚至不惜「視頻造假」。
就在今天,微軟正式發布了曾在11月Ignite大會上預告的Phi-2!

憑藉著2.7B的參數,「小語言模型(SLM)」Phi-2幾乎打穿了所有13B以下的大模型——包括谷歌最新發布的Gemini Nano 2。
通過模型擴展和訓練數據管理方面的創新,Phi-2展現了出色的推理和語言理解能力,在複雜的基準測試中,Phi-2的性能可以打平比自己大25倍的模型,甚至略占上風。
它用非常「苗條」的尺寸,獲得了良好的性能。
這讓研究人員和模型開發人員能夠很方便地使用Phi-2進行可解釋性、安全性方面的改進,並針對其他任務進行微調。
Phi-2目前已經可以通過Azure AI Studio訪問。
但是值得注意的是,相比其他的開源模型基本上是基於Apache 2.0的授權協議,可以支持商用。Phi-2隻能用於研究目的,不支持商用。
微軟最強「小模型」來了!
大語言模型現已增長到數千億的參數量,龐大的規模帶來了強大的性能,改變了自然語言處理領域的格局。
不過,能否通過恰當的訓練方法(比如數據選擇等),使得小型的語言模型也能獲得類似的能力?
微軟的Phi-2給出了答案。
Phi-2打破了傳統語言模型的縮放定律,測試成績能夠PK比自己大25倍的模型。
對於Phi-2「以小博大」的成功,微軟闡述了兩點關鍵見解:
第一點:訓練數據質量對模型性能起着至關重要的作用。
作為大模型開發者的共識,微軟的研究人員在此基礎上更進一步——使用「教科書質量」的數據。
在發布Phi-1的時候,開發團隊就提出了「教科書是你所需要的一切」(Textbooks Are All You Need)。
在本次Phi-2的開發中,團隊更是將這一點發揮到了極致。
Phi-2所使用的訓練數據,包含合成數據集,——專門用於教授模型常識推理和一般知識(科學、日常活動和心智理論等)。
此外,研發團隊還根據教育價值和內容質量,過濾了精心挑選的網絡數據,進一步擴充了訓練語料庫。
第二點:利用創新技術進行模型擴展。
以1.3B參數的Phi-1.5為基礎,將其知識嵌入到2.7B參數的Phi-2中。這種規模化的知識轉移不僅加快了訓練的收斂速度,而且明顯提高了Phi-2的基準分數。
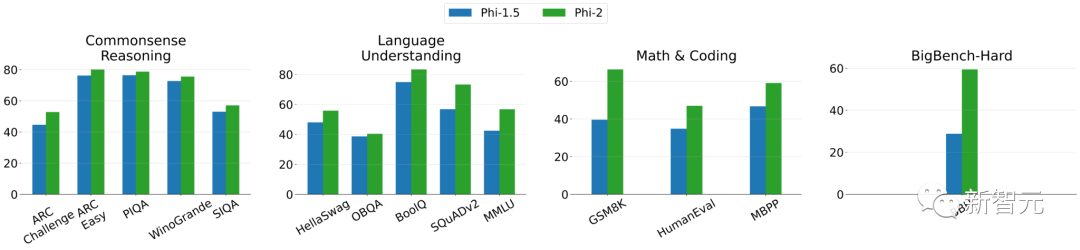
上圖展示了Phi-2和Phi-1.5在各項測試之中的比較(其中BBH和MMLU分別使用3次和5次CoT(Chain of Thought))。
我們可以看到,在創新技術的加持下,Phi-2的性能取得了明顯提升。
96塊A100練了14天
Phi-2 是一個基於 Transformer 的模型,使用1.4T個tokens進行訓練(包括用於NLP和編碼的合成數據集和Web數據集)。
訓練Phi-2使用了96塊A100 GPU,耗時14天。
Phi-2是一個基礎模型,它沒有通過人類反饋的強化學習(RLHF)進行對齊,也沒有經過微調。
儘管如此,與經過對齊的現有開源模型相比,Phi-2在毒性(toxicity)和偏差(bias)方面有更好的表現。——這得益於採用了量身定製的數據整理技術。
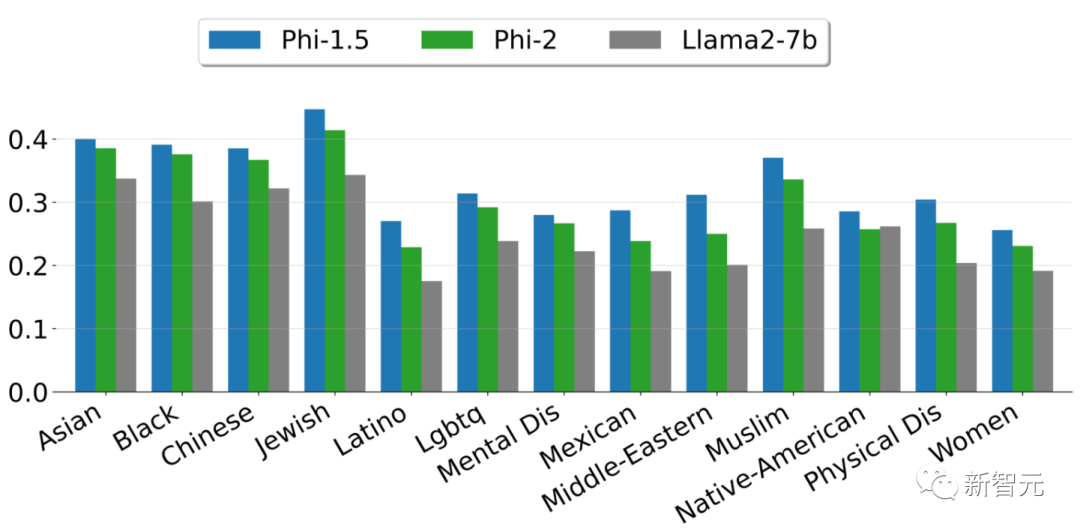
上圖展示了根據ToxiGen中的13個人口統計學數據,計算出的安全性分數。
這裏選取了6541個句子的子集,並根據複雜度和句子毒性在0到1之間進行評分。分數越高,表明模型產生有毒句子的可能性越小。
評估
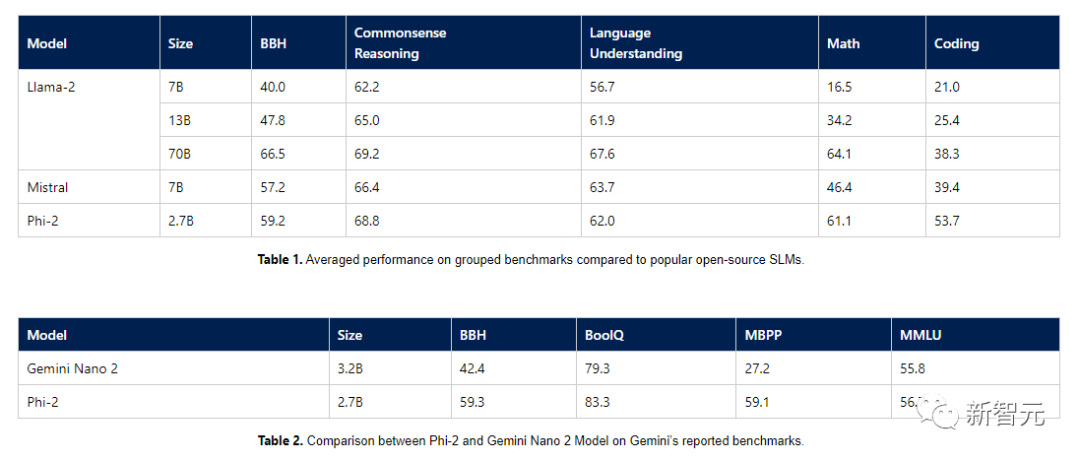
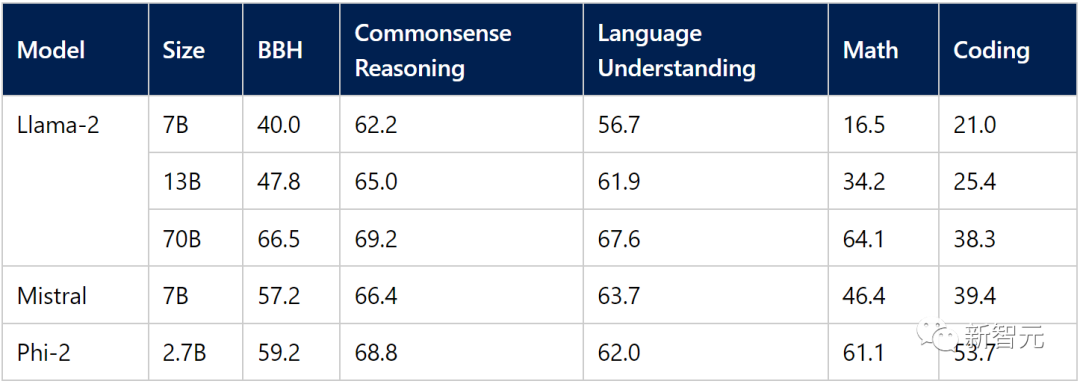
下面,研發團隊總結了Phi-2與流行語言模型相比在學術基準上的表現。
基準測試涵蓋了多個類別,Big Bench Hard(BBH)(使用CoT進行3次測試)、常識推理(PIQA、WinoGrande、ARC easy and challenge、SIQA)、語言理解(HellaSwag、OpenBookQA、MMLU(5次)、SQuADv2(2次)、BoolQ)、數學(GSM8k(8次))和編碼(HumanEval、MBPP(3次))。
Phi-2隻有2.7B的參數,在各種基準上,性能超過了Mistral 7B和 Llama-2 13B的模型性能。
而且,與25倍體量的Llama-2-70B模型相比,它在多步推理任務(即編碼和數學)上的性能還要更好。
此外,Phi-2與最近發布的Google Gemini Nano 2相比,性能也更好,儘管它的體量還稍小一些。
考慮到現在很多模型測試基準有可能已經被訓練數據污染了,研究團隊在Phi-1的開發時,就盡量避免了訓練數據被污染的可能。
微軟研究團隊也認為,判斷語言模型性能的最佳方法是在實際使用場景上進行測試。
本着這種求真務實的精神,微軟還使用了幾個Microsoft內部專有數據集和任務評估了Phi-2,並與Mistral和Llama-2進行了再次比較。得到的結果也還是說明Phi-2的平均性能要優於Mistral-7B 和Llama-2家族(7B、13B 和 70B)。

除了這些基準之外,Microsoft也忍不住對谷歌現在備受批評的Gemini演示視頻進行了一些挖掘,
視頻中展示了谷歌即將推出的最強大的人工智能模型Gemini Ultra,如何來解決相當複雜的物理問題,甚至糾正學生在這些問題上的錯誤。
事實證明,儘管Phi-2的參數量遠遠小於Gemini Ultra,但也能夠正確回答問題,並使用相同的提示糾正學生。

上圖展示了Phi-2在一個簡單的物理問題上的輸出,包括近似正確的平方根計算。

與Gemini的測試類似,這裏用學生的錯誤答案進一步詢問Phi-2,看看Phi-2是否能識別錯誤在哪裡。
我們可以看到,儘管Phi-2沒有針對聊天或指令跟蹤進行微調,但它還是識別出了問題所在。
不過需要注意的是,谷歌的演示視頻中使用學生手寫文本的圖像作為輸入,而Phi-2的測試中直接輸入了文本。
魔改提示工程,GPT-4逆襲Gemini Ultra
微軟放出了一個關於提示工程的研究Medprompt。他們通過創新的LLM提示工程技巧,在醫療領域獲得了之前需要專門的訓練或者微調才能達到性能提升。

論文地址:https://www.microsoft.com/en-us/research/publication/can-generalist-foundation-models-outcompete-special-purpose-tuning-case-study-in-medicine/
而在這個提示工程的基礎之上,微軟發現提示策略可以具有更通用效果。最終通過Medprompt的修改版本引導GPT-4,微軟取得了MMLU上的SOTA成績。
剛好比谷歌Gemini發布時的成績好了一點點。

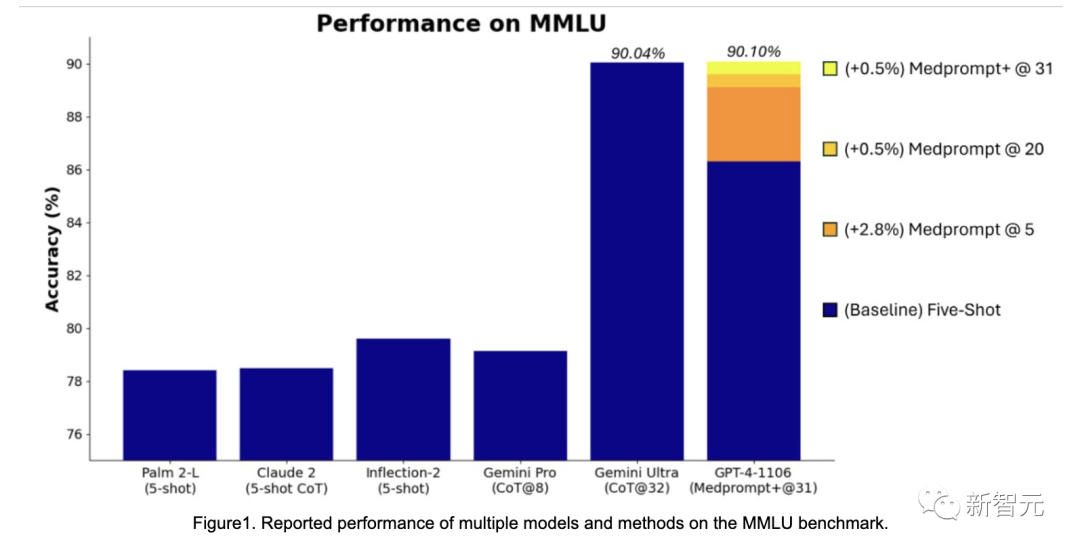
微軟用這個「不經意間」取得的結果,狙擊了在Gemini發布時,谷歌用CoT@32擊敗GPT-4 5 shot的成績。

這暗中較勁,卻還要表現得舉重若輕的感覺,像極了讀書時班上兩個學霸因為競爭相互拆台的場面。
網友熱議
此前,微軟的大佬就放出了在MT bench上對幾個模型的測試結果:
我們可以看到,僅僅2.7B的Phi-2系列,表現還是很不錯的。
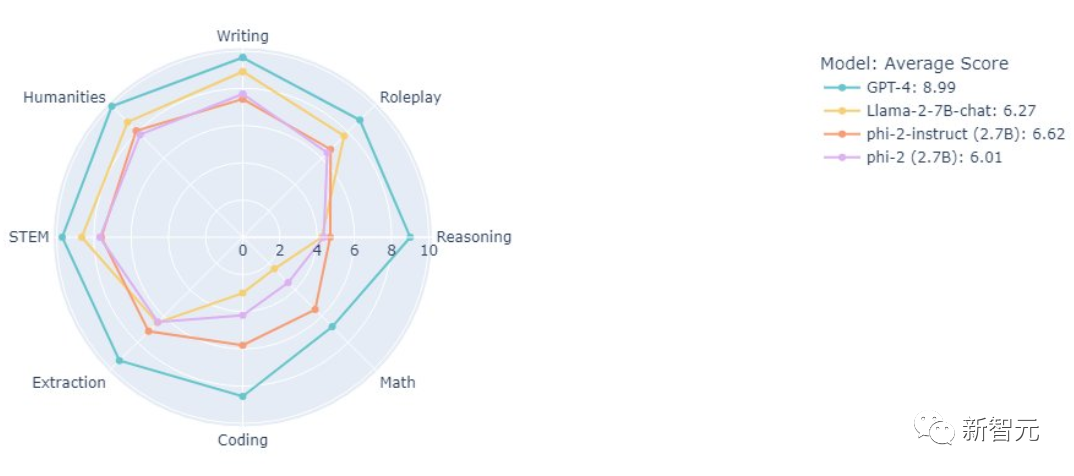
對於Phi-2的表現,網友也是不吝讚美之詞:

「哇,Phi-2聽起來像是遊戲規則的改變者!它的功能強大到足以與大型語言模型相媲美,但又足夠小,可以在筆記本電腦或移動設備上運行,這真是太棒了。這為在設備有限的設備上進行自然語言處理開闢了一個全新的世界。」
有網友表示很着急:

「有人想出如何在Mac上運行Microsoft的新Phi-2嗎?」
當然也有較為「尖銳」的網友拉出了OpenAI:

「如果一開始就不給模型喂垃圾,似乎就不必擔心對齊問題。@Openai 」
也有網友對小語言模型的前景充滿希望:

「非常希望Phi-3能夠在所有任務中勝過GPT-3.5」。
參考資料:
https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/