所有語言











分享
“像近年的蘋果發布會,並無新意”,專家吐槽谷歌 Gemini:只是小進步,飛躍談不上
“Gemini 是這波生成式 AI 浪潮的頂峰,但並非下一個高峰的開端。”

圖片來源:由無界 AI生成
12 月 6 日晚,谷歌 DeepMind 推出了其“迄今為止最強大、最通用的模型”Gemini。一位觀察家表示,Gemini 是一台“萬能機器”,在各種性能上都是同類最佳的。谷歌及其母公司 Alphabet 的首席執行官桑達爾 - 皮查伊(Sundar Pichai)在接受採訪時也表示:“這對我們來說是向前邁出的一大步。”
是的,對於谷歌而言,相比此前飽受詬病的 Bard,Gemini 是進步,但對整個 AI 領域來說未必是一個巨大的飛躍。
作為對 OpenAI GPT-4 的回應,谷歌 DeepMind 聲稱,Gemini 在 32 項標準性能指標中,有 30 項指標都優於 GPT-4。然而,它們之間的差距其實是微乎其微的。谷歌 DeepMind 所做的,其實只是將人工智能目前最好的能力整合到一個強大的軟件包中。從演示來看,它在很多方面都做得很好,但很少有我們以前沒見過的東西。
Gemini 可能是一個跡象,表明我們已經達到了人工智能炒作的頂峰。至少現在是這樣。
華盛頓大學專門研究在線搜索的教授 Chirag Shah 把這次發布比作蘋果公司近年推出的新款 iPhone。他說:“也許我們現在只是上升到了一個不同的閾值,在這個閾值上,這並沒有給我們留下那麼深刻的印象,因為我們已經看過太多(類似的產品和功能了)。”
與 GPT-4 一樣,Gemini 也是多模態的,這意味着它經過訓練可以處理多種輸入:文本、圖像、音頻。它可以將這些不同的格式結合起來,回答從家務到大學數學到經濟學等各種問題。
在昨天為記者進行的演示中,谷歌展示了 Gemini 的性能,它可以截取現有圖表的截圖,分析數百頁的研究報告和新數據,然後根據新信息更新圖表。在另一演示中,Gemini 显示了在平底鍋中烹飪蛋餅的圖片,並詢問(使用語音而非文字)蛋餅是否已經熟透。Gemini 也能準確地答上來:“還沒熟,因為蛋液還是流動的。”
目前,Gemini 還未完全上線。今天推出的版本是谷歌基於文本的搜索聊天機器人 Bard 的後端。Gemini 的全面發布將在未來幾個月內分期進行。經過 Gemini 強化的新 Bard 最初將在 170 多個國家(不包括歐盟和英國)提供英語版本。負責 Bard 的谷歌副總裁 Sissie Hsiao 說,這是為了讓公司與當地監管機構“接觸”。
具體而言,Gemini 有三種規格:Ultra、Pro 和 Nano。其中,Ultra 是全功率版本;Pro 和 Nano 則是為計算資源有限的應用程序量身定製的。Nano 則專為在谷歌新款 Pixel 手機等設備上運行而設計。開發人員和企業將從 12 月 13 日開始訪問 Gemini Pro。Gemini Ultra 是功能最強大的規格,將在“明年初經過”廣泛的信任和安全檢查“后推出。
“我認為大模型已經到了 Gemini 時代,”皮查伊表示。“這就是谷歌 DeepMind 在人工智能領域的構建和進步方式。它永遠代表着我們在人工智能技術方面取得進展的前沿。”
更大、更好、更快、更強?
OpenAI 最強大的模型 GPT-4 被視為業界的黃金標準。雖然谷歌誇口說 Gemini 比 OpenAI 之前的模型 GPT 3.5 性能更強,但公司高管迴避了關於該模型比 GPT-4 強多少的問題。
在與同類大模型相比時,谷歌特彆強調了一個名為 MMLU(大規模多任務語言理解)的基準。這是一套測試,旨在衡量模型在涉及文本和圖像的任務中的表現,包括閱讀理解、大學數學以及物理、經濟和社會科學方面的多項選擇測驗。皮查伊說,在純文本問題上,Gemni 的得分率為 90%,人類專家的得分率約為 89%,而 GPT-4 在這類問題上的得分率為 86%。在多模態問題上,Gemini 的得分率為 59%,而 GPT-4 的得分率為 57%。皮查伊說:“這是第一個跨過這個門檻的模型。”
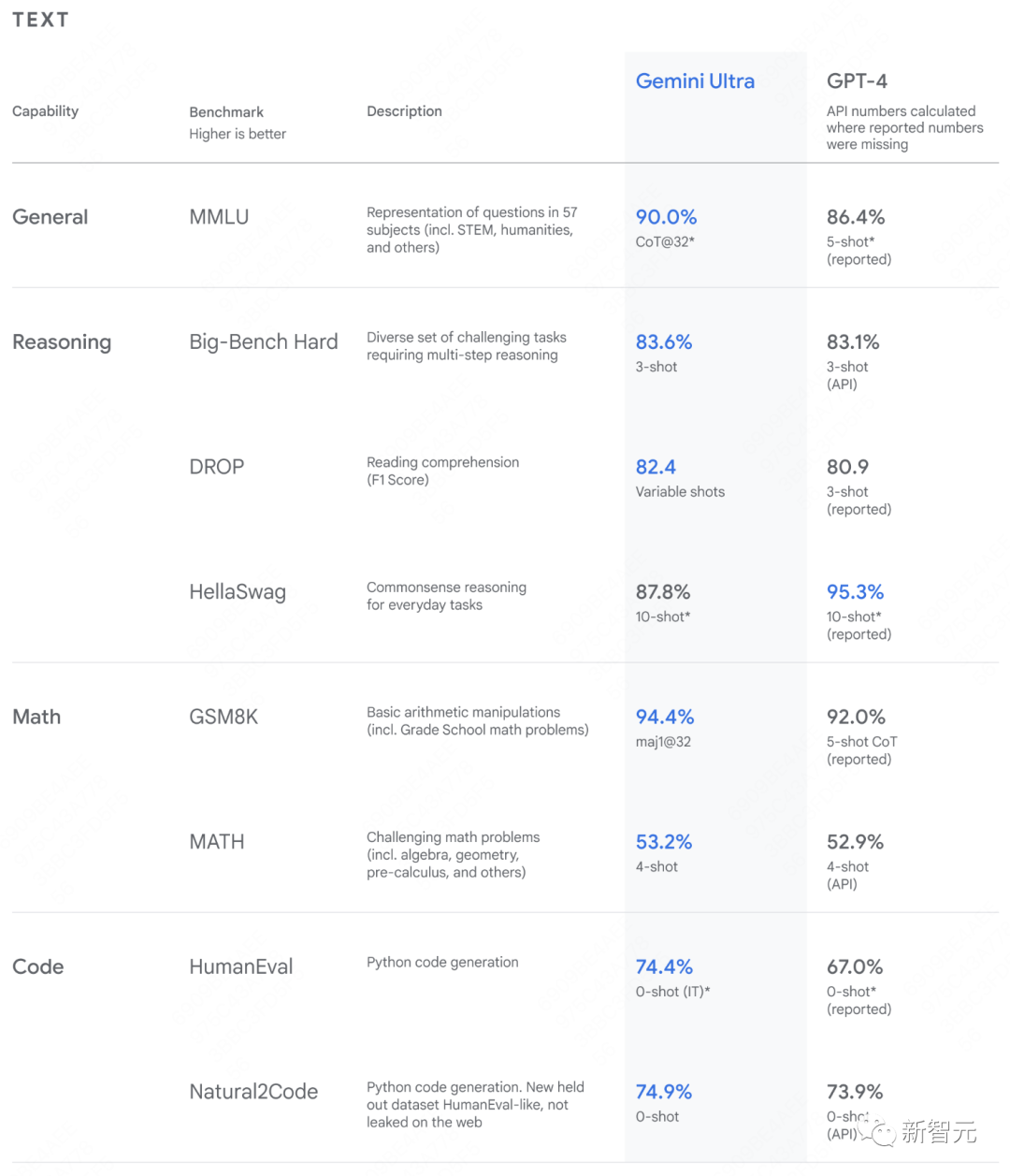
的確,在數據上,Gemini 的成績好於 GPT-4,但真的不多。
新墨西哥州聖達菲研究所(Santa Fe Institute)的人工智能研究員 Melanie Mitchell 就表示,“很明顯,Gemini 是一個非常複雜的人工智能系統。”但“在我看來,Gemini 的能力實際上並沒有明顯超過 GPT-4,”她補充說。
此外,斯坦福大學基礎模型研究中心主任 Percy Liang 也談到,雖然該模型有很好的基準分數,但由於我們不知道訓練數據的內容,因此很難解釋這些數據。
Mitchell 還指出,Gemini 在不同基準上的表現也沒那麼穩定,語言和代碼方面的表現要比在圖像和視頻方面好得多。她說:“多模態基礎模型要想在許多任務中發揮普遍而強大的作用,還有很長的路要走。”
據悉,谷歌 DeepMind 利用人類測試者的反饋對 Gemini 進行了訓練,使其能地反映事實,在被要求時給出歸因,並在面對無法回答的問題時迴避而不是胡言亂語。谷歌稱,這可以減輕幻覺問題。但是,如果不對基礎技術進行徹底改革,大型語言模型將繼續胡編亂造。
專家表示,目前還不清楚谷歌用來衡量 Gemini 性能的基準是否能提供那麼多的洞察力,而且在不透明的情況下,也很難核實谷歌的說法。
華盛頓大學計算語言學教授 Emily Bender 說:“谷歌宣傳 Gemini 是一台萬能機器 -- 一個可用於多種不同用途的通用模型。”但是,該公司正在使用狹隘的基準來評估它期望用於這些不同用途的模型。“這意味着它實際上無法得到徹底評估,”她說。
Shah 表示,最終,對於普通用戶來說,與競爭模型相比的進步可能不會帶來太大的影響。“這更多的是便利性、品牌認知度和現有集成,而不是人們真正認為‘哦,這個更好’,”他說。
漫長而緩慢的積累
Gemini 的誕生由來已久。2023 年 4 月,谷歌宣布將其人工智能研究部門 Google Brain 與 Alphabet 位於倫敦的人工智能研究實驗室 DeepMind 合併。因此,谷歌花了近一年的時間來開發其應對 OpenAI 最先進的大型語言模型 GPT-4 的答案。
谷歌一直承受着巨大的壓力,它必須向投資者展示自己在人工智能領域能夠與競爭對手匹敵,甚至超越對手。雖然谷歌多年來一直在開發和使用功能強大的人工智能模型,但由於擔心聲譽受損和安全問題,它一直對推出公眾可以使用的工具猶豫不決。
今年 4 月,傑弗里 - 辛頓(Geoffrey Hinton)在離開谷歌時表示:“谷歌在向公眾發布這些東西方面一直非常謹慎。”“可能發生的壞事太多了,谷歌不想毀了自己的聲譽。”面對似乎不可信或無法銷售的技術,谷歌採取了穩妥的做法 -- 直到更大的風險變成了錯失良機。
谷歌已經深刻認識到,推出有缺陷的產品可能會適得其反。今年 2 月,谷歌推出了 ChatGPT 的競對巴德(Bard),但科學家們很快就發現該公司自己為聊天機器人所做的廣告中存在事實錯誤,這一事件也導致谷歌市值蒸發了 1000 億美元。
今年 5 月,谷歌宣布在從电子郵件到生產力軟件的大部分產品中推出生成式人工智能。但結果並未給大伙兒留下深刻印象:例如,聊天機器人提到了並不存在的电子郵件。
這是大型語言模型一貫存在的問題。生成式人工智能系統雖然擅長生成聽起來像是人類寫的文字,但經常會胡編亂造。而且它們還容易被黑客攻擊,並且充滿偏見。
谷歌既沒有解決這些問題,也沒有解決幻覺問題。對於后一個問題,谷歌的解決方案是讓人們使用谷歌搜索來重複檢查聊天機器人的答案,但這依賴於在線搜索結果本身的準確性。
Gemini 可能是這波生成式人工智能浪潮的頂峰。但建立在大型語言模型基礎上的人工智能下一步將走向何方,目前還不清楚。一些研究人員認為,這可能只是一個平台期,而非下一個高峰的開端。
然而,對於未來,皮查伊並不悲觀。他說:“展望未來,我們確實看到了很大的發展空間。”“我認為多模態將大有作為。當我們教會這些模型更多地進行推理時,將會有越來越大的突破。更深層次的突破還在後面。”“從整體上看,我真的覺得我們正處於起步階段。”
原文來源:麻省理工科技評論,作者:Melissa Heikkilä、Will Douglas Heaven
- https://www.technologyreview.com/2023/12/06/1084471/google-deepminds-new-gemini-model-looks-amazing-but-could-signal-peak-ai-hype/