所有語言











分享
首次擊敗GPT-4?700億參數Xwin-LM登頂斯坦福AlpacaEval,13B模型吊打ChatGPT
巴比特_云锦571天前
來源:新智元
導讀:GPT-4在斯坦福AlpacaEval的榜首之位,居然被一匹黑馬搶過來了。
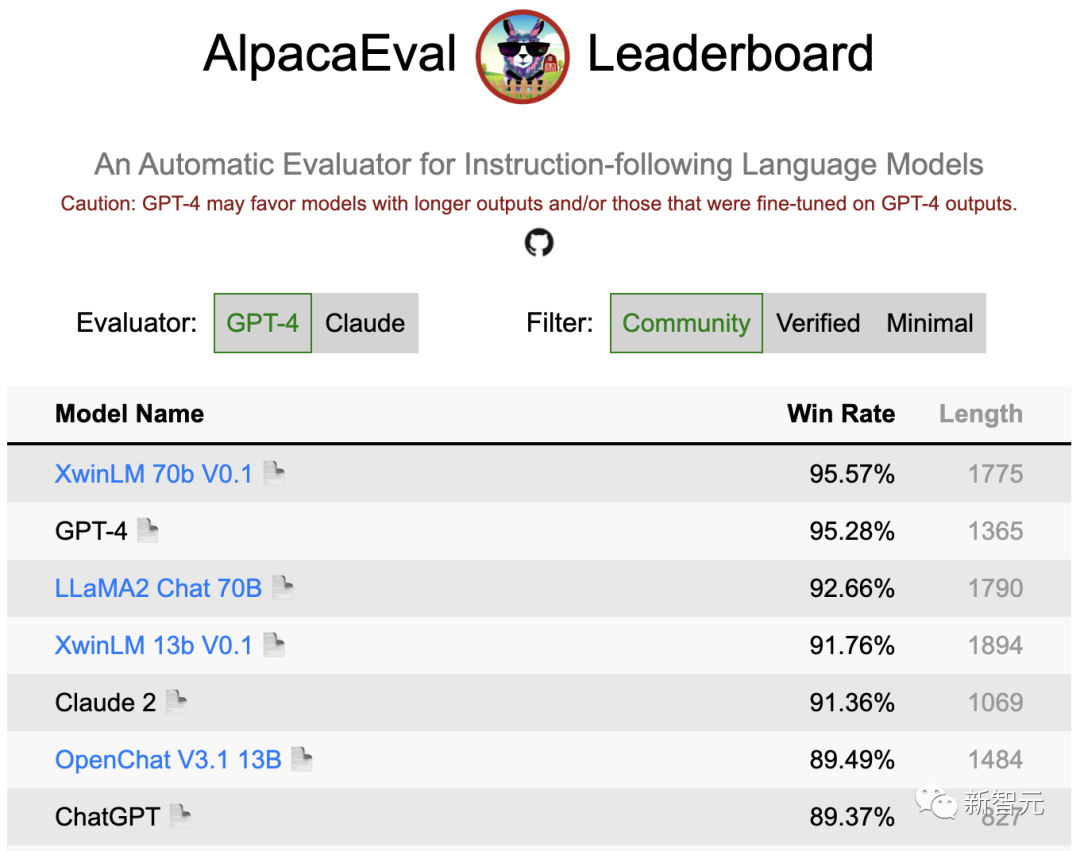
第一個在AlpacaEval上超越GPT-4的模型,出現了!
今年6月,AlpacaEval榜單一公布,GPT-4就以絕對領先的優勢奪得第一,勝率超過95%。
三個月後,一匹叫Xwin-LM的黑馬,居然把穩居榜首的GPT-4從TOP 1拉下來了?
項目地址:https://tatsu-lab.github.io/alpaca_eval/
而且,Xwin-LM在同參數模型的對壘中,也毫無例外地拿下了三個第一:

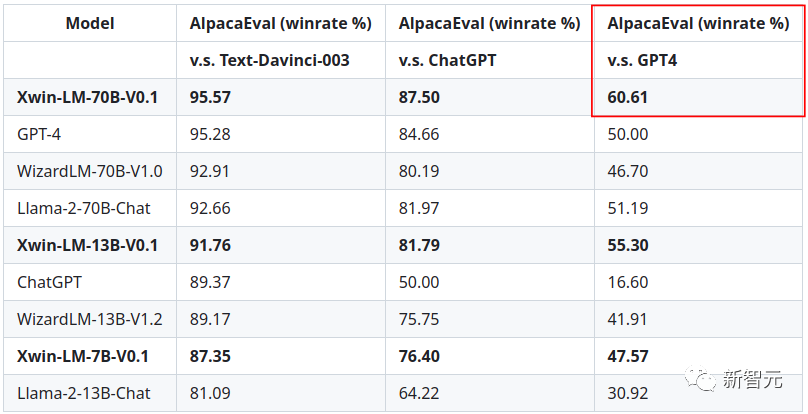
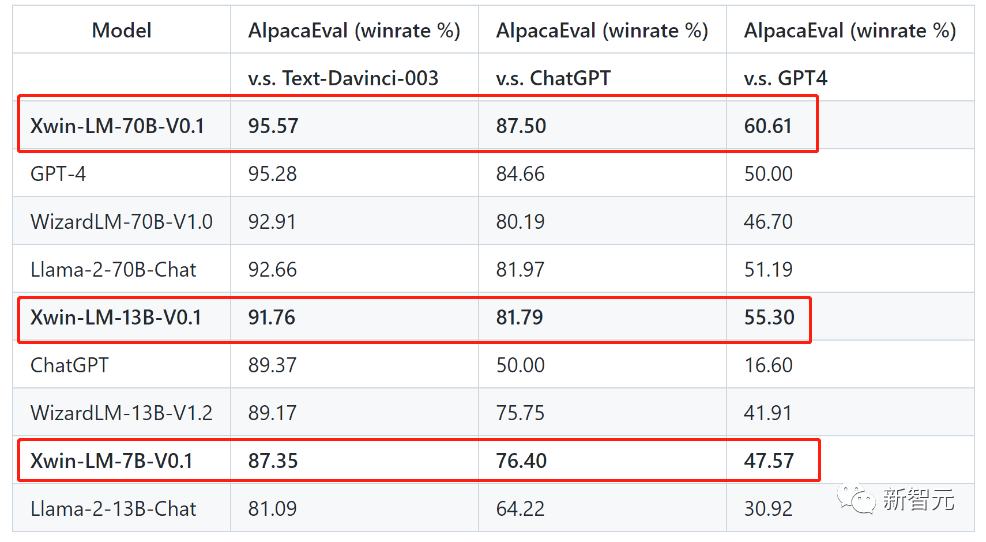
Xwin-LM-70B-V0.1:在AlpacaEval基準測試中對Davinci-003的勝率達到95.57%,在AlpacaEval中排名第一。也是第一個在AlpacaEval上超越GPT-4的模型。此外,它對上GPT-4的勝率為60.61。
Xwin-LM-13B-V0.1:在AlpacaEval上取得了91.76%的勝率,在所有13B模型中排名第一。
Xwin-LM-7B-V0.1:在AlpacaEval上取得了87.82%的勝率,在所有7B機型中排名第一。
Xwin-LM:700億參數打贏GPT-4
Xwin-LM是以Llama 2為基礎進行微調的,該模型旨在開發和開源大語言模型的對齊技術,包括監督微調(SFT)、獎勵模型(RM)、拒絕採樣、人類反饋強化學習(RLHF)等。
1. 性能評估
研究人員評估了Xwin-LM在805個問題上與Text-Davinci-003 、ChatGPT和GPT-4的勝率。
可以看到,Xwin-LM的70B模型完全霸榜,成為AlpacaEval指標上的性能評估的第一,並首次打敗了GPT-4,對GPT-4的勝率達到了60.61%。
Xwin-LM其他規模的模型,如Xwin-LM-13B-V0.1、Xwin-LM-7B-V0.1在性能上也遠超相同規模的其他模型。
Xwin-LM-7B-V0.1甚至超過了比它規模更大的Llama 2-13B-Chat。
2. 案例比較
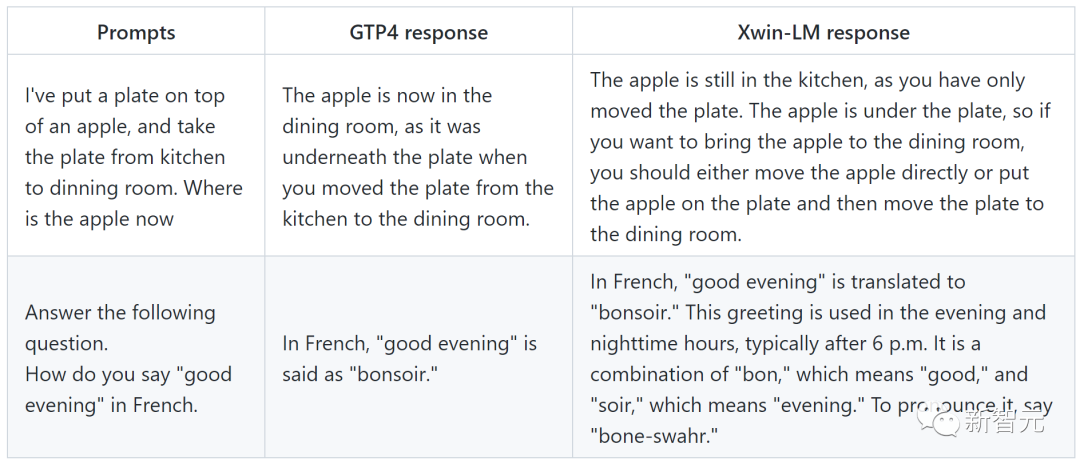
在第一個案例中,研究人員向GPT-4和Xwin-LM提問:
「我把一個盤子放在蘋果上面,然後把盤子從廚房帶到餐廳。蘋果現在在哪裡?」
GPT-4的回答是:
「蘋果現在在餐廳,當你把盤子從廚房到端餐廳時,它就在盤子下面。」
在這裏GPT-4給出了一個缺少常識的回復,現實生活中有重力,在盤子下方的蘋果保持原來的狀態,並不會和盤子一起到餐廳。
相比之下,Xwin-LM的回答就比較符合現實情況,並且還給出了把蘋果帶到廚房的方法:
「蘋果還在廚房裡,因為你只是移動了盤子。
蘋果在盤子下面,所以如果你想把蘋果帶到餐廳,你應該直接移動蘋果或把蘋果放在盤子里,然後把盤子移到餐廳。」
在第二個案例中,研究人員向GPT-4和Xwin-LM提問:
「怎麼法語說『晚上好』?」
GPT-4的回答是:
「在法語中,『晚上好』用『bonsoir』表達。」
而Xwin-LM的回答是:
「在法語中,『晚上好』被翻譯為『bonsoir』。這種問候語在晚上和夜間使用,通常在下午 6 點之後。
它是『bon』(意思是好)和『soir』(意思是晚上)的組合。要發音,請說『bone-swahr』」。
雖然GPT-4的回答是正確的,但Xwin-LM不僅正確回答了問題,還解釋了法語表達中「晚上好」的來源和發音,反饋給用戶的信息更加豐富。
3. NLP任務
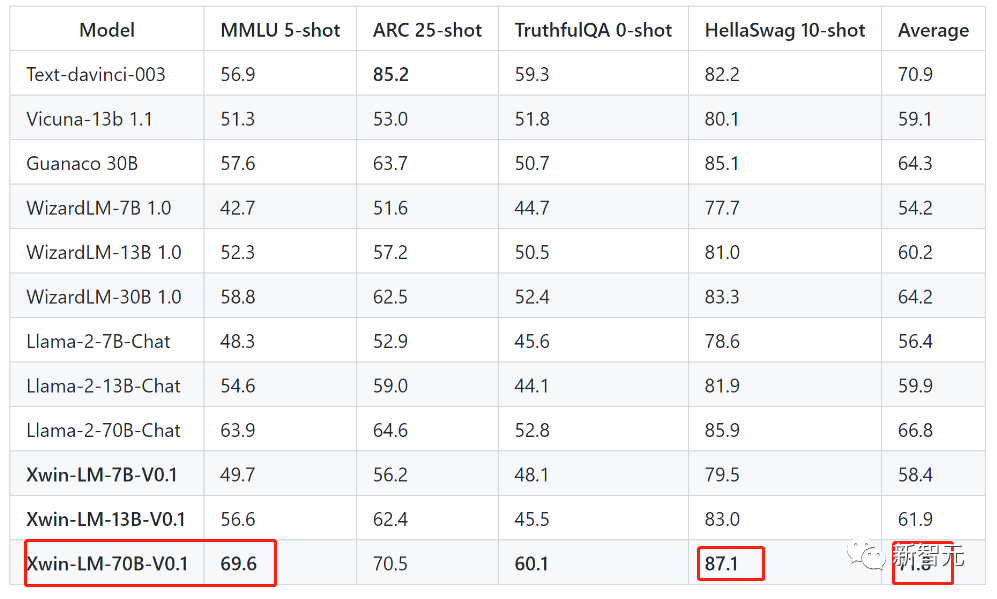
下錶是Xwin-LM與其他LLM在NLP基礎任務上的比較。
可以看到,Xwin-LM-70B-V0.1模型在所有任務中的性能都相對較高,在MMLU 5-shot和HellaSwag 10-shot任務中更是表現出色。
並且,從綜合水平上來說,Xwin-LM-70B-V0.1是表現最好的。
4. 推理能力
研究人員提出,為了在使用Xwin-LM進行推理時獲得所需的結果,需要嚴格遵守推理的對話模板。
Xwin-LM採用Vicuna建立的提示格式,並支持多回合對話。
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: Hi! ASSISTANT: Hello.s>USER: Who are you? ASSISTANT: I am Xwin-LM.s>......
HuggingFace示例
from transformers import AutoTokenizer, AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained("Xwin-LM/Xwin-LM-7B-V0.1")tokenizer = AutoTokenizer.from_pretrained("Xwin-LM/Xwin-LM-7B-V0.1")( prompt := "A chat between a curious user and an artificial intelligence assistant. " "The assistant gives helpful, detailed, and polite answers to the user's questions. " "USER: Hello, can you help me? " "ASSISTANT:")inputs = tokenizer(prompt, return_tensors="pt")samples = model.generate(**inputs, max_new_tokens=4096, temperature=0.7)output = tokenizer.decode(samples[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)print(output) # Of course! I'm here to help. Please feel free to ask your question or describe the issue you're having, and I'll do my best to assist you.
VLLM示例
因為Xwin-LM是基於Llama 2微調而來,它還支持使用VLLM進行快速推理。
from vllm import LLM, SamplingParams( prompt := "A chat between a curious user and an artificial intelligence assistant. " "The assistant gives helpful, detailed, and polite answers to the user's questions. " "USER: Hello, can you help me? " "ASSISTANT:")sampling_params = SamplingParams(temperature=0.7, max_tokens=4096)llm = LLM(model="Xwin-LM/Xwin-LM-7B-V0.1")outputs = llm.generate([prompt,], sampling_params)
for output in outputs: prompt = output.prompt generated_text = output.outputs[0].text print(generated_text)
AlpacaEval:易使用、速度快、成本低、經過人類標註驗證
作為一款LLM自動評估工具,AlpacaEval把AlpacaFarm和Aviary進行了結合。
一方面使用與AlpacaFarm相同的代碼(緩存/隨機排列/超參數),另一方面則使用類似於Aviary的排序提示。
與此同時,還對Aviary的提示進行了修改,從而減少對較長輸出的偏見。
團隊表示,AlpacaEval有着拔群的效果:
- 與人類多數票的一致性,高於單個人類標註者
- 勝率與人類標註高度相關(0.94)
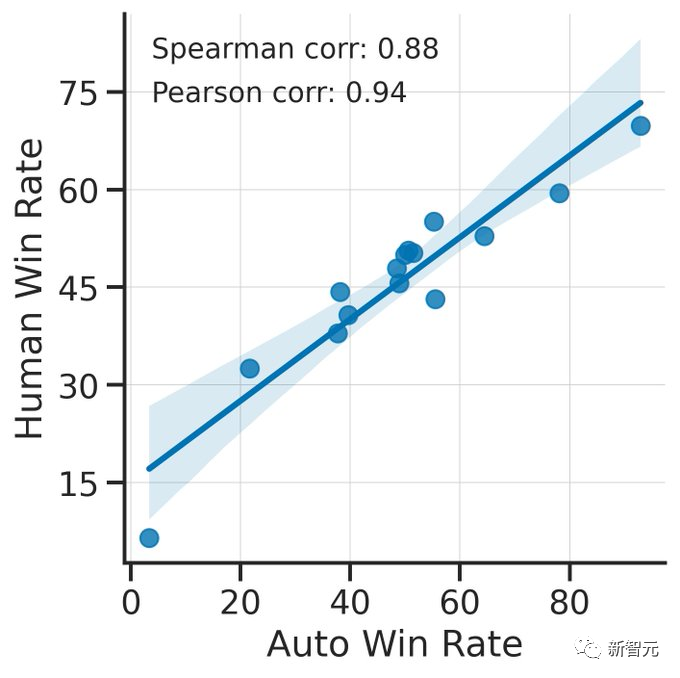
- 勝率
模型的輸出在每個指令上優於text-davinci-003(即參考文本)的比例。
具體而言,首先從AlpacaEval數據集中收集了期望模型在每個指令上的輸出對,並將每個輸出與相同指令下的參考模型(text-davinci-003)的輸出進行配對。
隨後,把這些輸出同時餵給自動評測器,讓它去判斷哪一個更好(也就是評測器的偏好)。
最後,將數據集中所有指令的偏好進行平均,從而得到模型相對於text-davinci-003的勝率。如果兩個模型打平,那麼就算半個偏好。

論文地址:https://arxiv.org/pdf/2305.14387.pdf
- 局限性
雖然AlpacaEval為比較模型遵循指令的能力提供了一種有效的方法,但它並不是對模型能力進行全面評估的黃金標準。
正如AlpacaFarm論文中詳述的那樣,自動標註器的勝率與長度相關。雖然人類標註也會有這種偏差,但目前還不清楚更長的答案是否會增加下游任務的效用。
此外,AlpacaFarm的評估集雖然多種多樣,但主要由簡單的指令組成。
最後,AlpacaEval並不評估任何模型的安全性。
參考資料:
https://huggingface.co/Xwin-LM/Xwin-LM-70B-V0.1