所有語言











分享
中文大模型比英文更燒錢,這居然是AI底層原理決定的?
巴比特_AI梦工厂592天前
來源:未來科技力
作者:李欣帥
ChatGPT等AI工具的使用正越來越普遍。在與AI交互時,我們知道,輸入的提示詞差異會對輸出結果產生影響。那麼,如果相同意思的提示詞,用不同語言分別表述,結果差異是否較大?另外,提示詞的輸入和輸出是和模型背後的計算量直接掛鈎的。因此,不同語言之間在AI輸出和成本消耗方面是不是有着天然的差異性或者說是“不公平性”?這種“不公平性”又是如何產生的呢?
據了解,提示詞背後其實對應的不是文字,而是token。當接收到用戶輸入的提示詞之後,模型會將輸入轉換為token列表進行處理和預測,同時將預測的token轉換為我們在輸出中看到的單詞。也就是,token是語言模型處理和生成文本或代碼的基本單位。可以關注到,各家廠商會宣稱自家模型支持多少token的上下文,而不是說支持的單詞或漢字的數量。
影響Token計算的因素
首先,一個token並不對應一個英文單詞或一個漢字,token跟單詞之間沒有具體的換算關係。比如,根據OpenAI發布的token計算工具,hamburger一詞被分解為ham、bur和ger,共計3個token。另外,同一個詞語,如果在兩句話中的結構不同,會被記作不同數目的token。
具體token如何計算主要取決於廠商使用的標記化(tokenization)方法。標記化是將輸入和輸出文本拆分為可由語言模型處理的token的過程。該過程可以幫助模型處理不同的語言、詞彙表和格式。而ChatGPT背後採用的是一種稱為“字節對編碼”(Byte-Pair Encoding,BPE)的標記化方法。
目前來看,一個單詞被分解成多少token,跟它的發音和在句子中的結構有關。而不同語言之間的計算差異似乎較大。
拿“hamburger”對應的中文“漢堡包”來說,這三個漢字被計作8個token,也就是被分解成了8部分。

圖源:OpenAI官網截圖
再拿一段話來進行中英文語言token計算的“不公平性”對比。
下面是OpenAI官網的一句話:You can use the tool below to understand how a piece of text would be tokenized by the API, and the total count of tokens in that piece of text.這段話共計33個token。

圖源:OpenAI官網截圖
對應的中文為:您可以使用下面的工具來理解API如何將一段文本標記化,以及該段文本中標記的總數。共計76token。
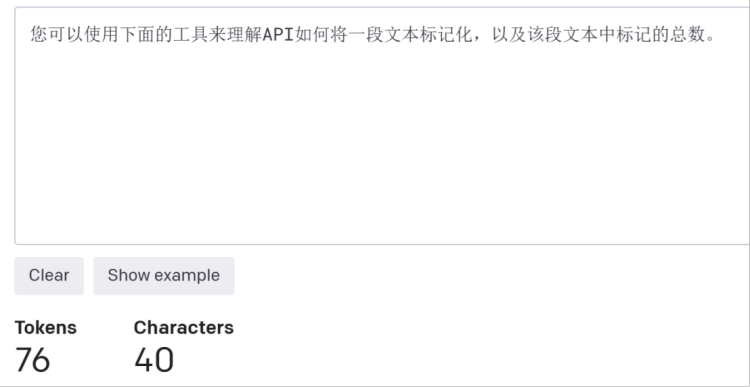
圖源:OpenAI官網截圖
中英文語言在AI上存在天然“不公平”
可以看到,相同意思的中文token數是英文的兩倍多。中文和英文在訓練和推理上的“不公平性”,也許是因為中文通常一個詞彙可以表達多種含義,語言組成較為靈活,中文還有着深厚的文化內涵,具有豐富的語境意義,這極大增加了語言的歧義性和處理難度;英語語法結構較為簡單,這使得英語在一些自然語言任務上比中文更容易被處理和理解。
中文需要處理的token更多,模型所消耗的內存和計算資源也就越多,當然所需要的成本也就越大。
同時,ChatGPT雖然可以識別包括中文在內的多種語言,但它訓練使用的數據集大都為英文文本,在處理非英語語言時,可能面臨語言結構、語法等方面的挑戰,進而影響輸出效果。近日的一篇題為《多語言語言模型在英語中表現得更好嗎?》(Do Multilingual Language Models Think Better in English?)的論文中提到,當將非英文語言翻譯成英文後輸出的結果,要好於直接使用非英文語言作為提示詞的結果。
對中文用戶來說,似乎先將中文翻譯成英文,然後再與AI交互,似乎效果更好,也更划算。畢竟使用OpenAI的GPT-4模型API,每輸入1千token至少要收費0.03美元。
那由於中文語言的複雜性,AI模型在使用中文數據進行準確訓練和推理方面可能面臨挑戰,並增加了中文模型應用和維護的難度。同時,對開發大模型的公司來說,做中文大模型由於需要額外的資源,或許要承擔更大的成本。